Starting a Kafka Connect sink connector at the end of a topic
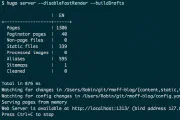
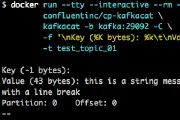
When you create a sink connector in Kafka Connect, by default it will start reading from the beginning of the topic and stream all of the existing—and new—data to the target. The setting that …