Interesting links - July 2026
Sheesh, 162 links this month. What is going ON? There is just too much interesting material being written, and that’s after filtering out clanker slop. I’m pretty sure I need to curtail the scope of …

Sheesh, 162 links this month. What is going ON? There is just too much interesting material being written, and that’s after filtering out clanker slop. I’m pretty sure I need to curtail the scope of …




 5k run/walk
5k run/walk




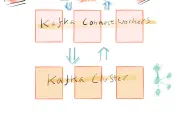
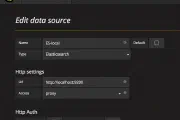
 Kafka Connect
Kafka Connect

 AI
AI
 AI
AI





 AI
AI
 AI
AI





 Property Graph
Property Graph


 Stumbling into AI
Stumbling into AI
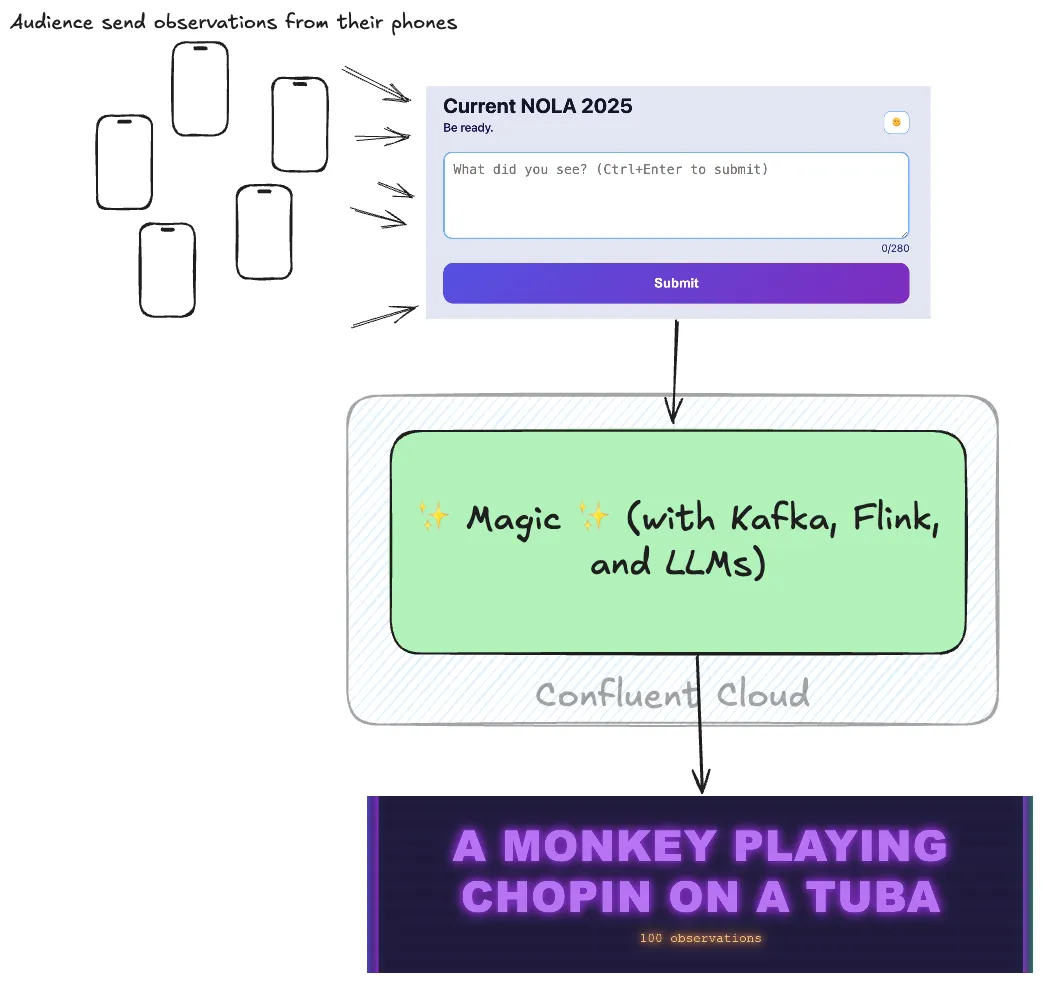 Stumbling into AI
Stumbling into AI




 AI
AI





 Apache Flink
Apache Flink

 Apache Iceberg
Apache Iceberg
 Apache Iceberg
Apache Iceberg

 Flink SQL
Flink SQL



 Kafka Summit
Kafka Summit
 Apache Flink
Apache Flink

 Apache Flink
Apache Flink

 LinkedIn
LinkedIn



 Confluent Cloud
Confluent Cloud

 Blogging
Blogging



 DuckDB
DuckDB
 DuckDB
DuckDB




 Postgres
Postgres





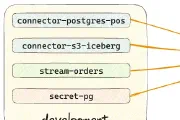 Decodable
Decodable

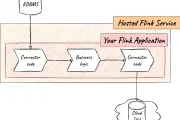
 Apache Flink
Apache Flink
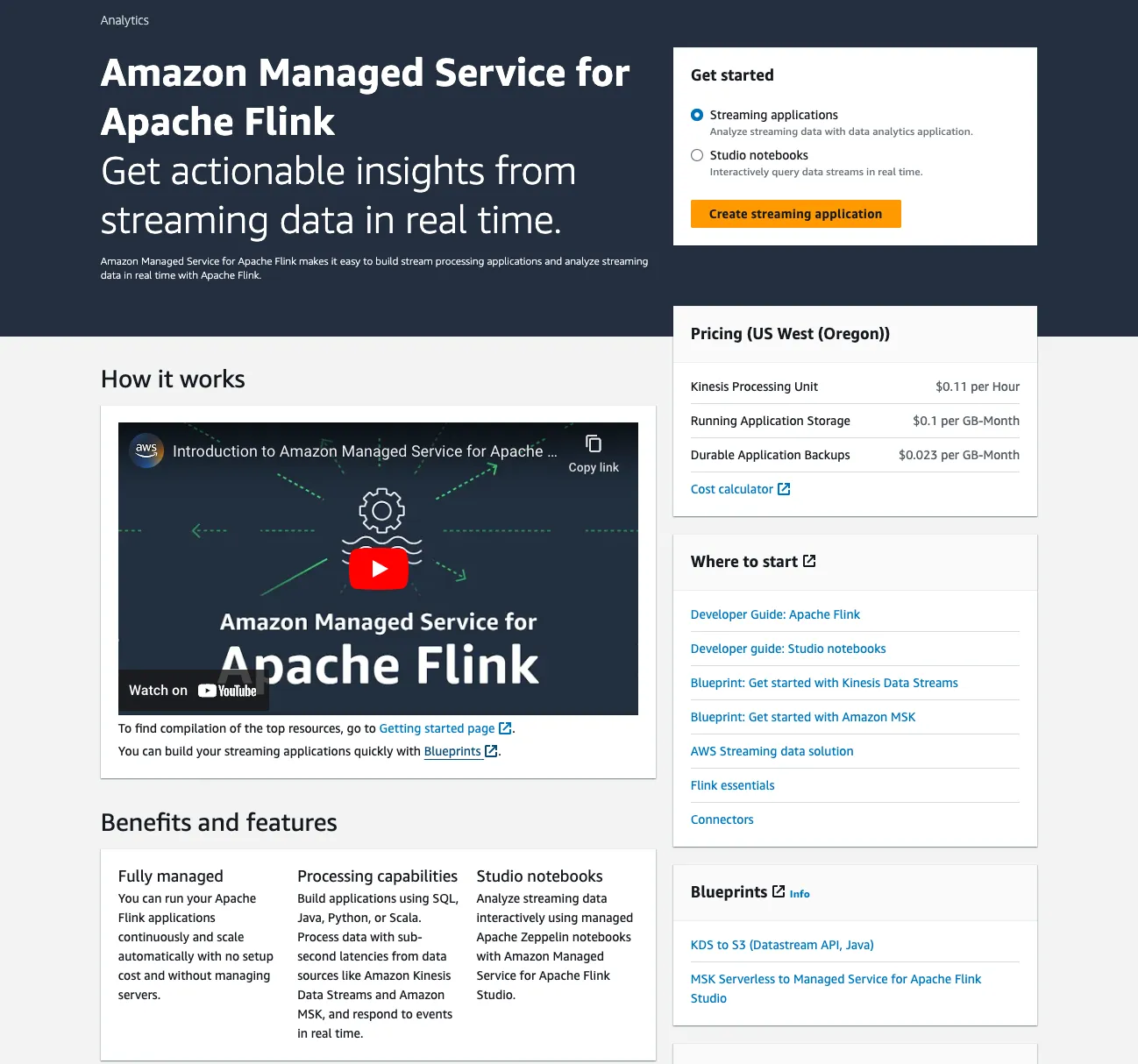 Apache Flink
Apache Flink
 Apache Kafka
Apache Kafka

 RSS
RSS


 Apache Flink
Apache Flink

 Kafka Summit
Kafka Summit






 Antora
Antora
 GitHub
GitHub
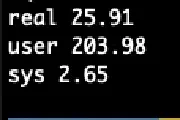
 Antora
Antora



 Flink JDBC
Flink JDBC

 LAF
LAF
 LAF
LAF
 LAF
LAF



 Streaming
Streaming


 Markdown
Markdown
 Documentation
Documentation
 PySpark
PySpark





 dbt
dbt
 Data Engineering
Data Engineering
 DuckDB
DuckDB
 Data Engineering
Data Engineering

 Data Engineering
Data Engineering


 Data Engineering
Data Engineering
 Airtable
Airtable
 DevRel
DevRel

 DevRel
DevRel


 Hugo
Hugo
 Kafka Summit
Kafka Summit
 Productivity
Productivity

 ksqlDB
ksqlDB
 Confluent Cloud
Confluent Cloud
 ksqlDB
ksqlDB
 ActiveMQ
ActiveMQ
 Kafka Connect
Kafka Connect

 Data
Data

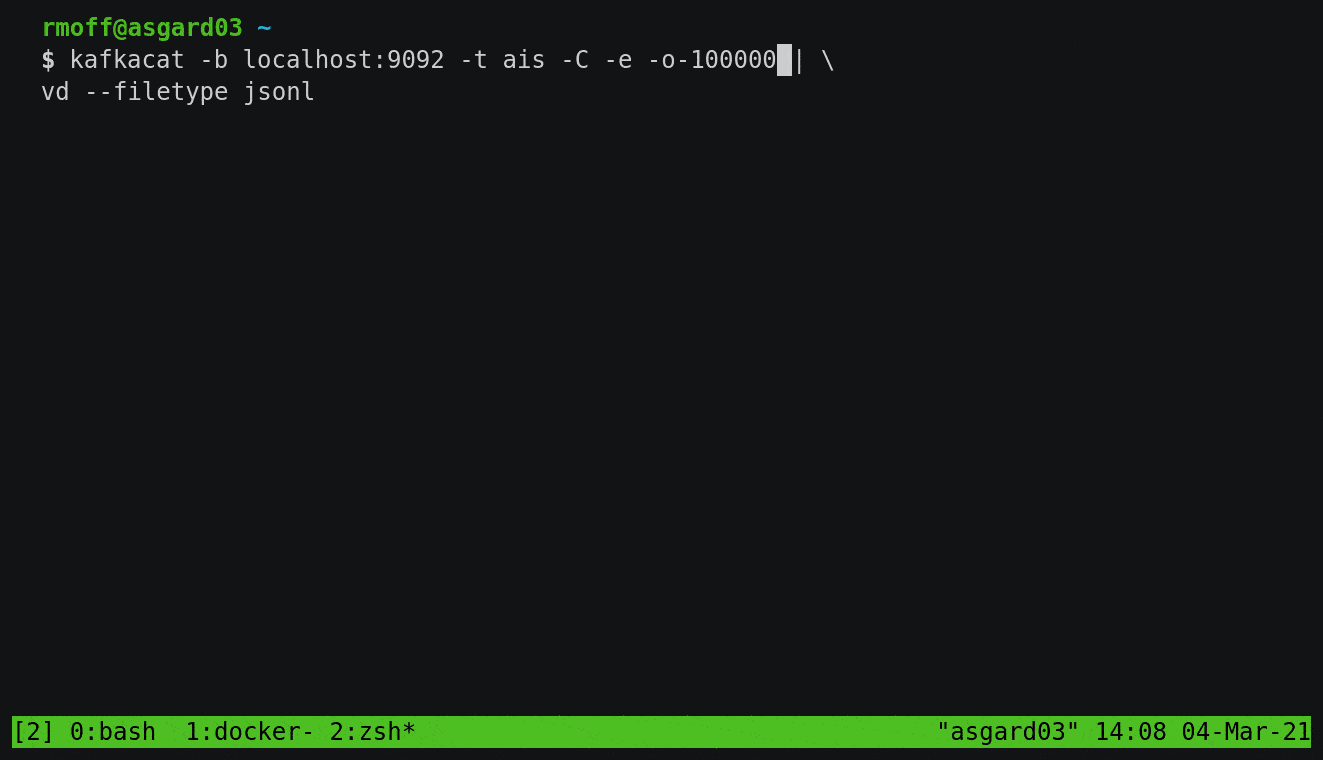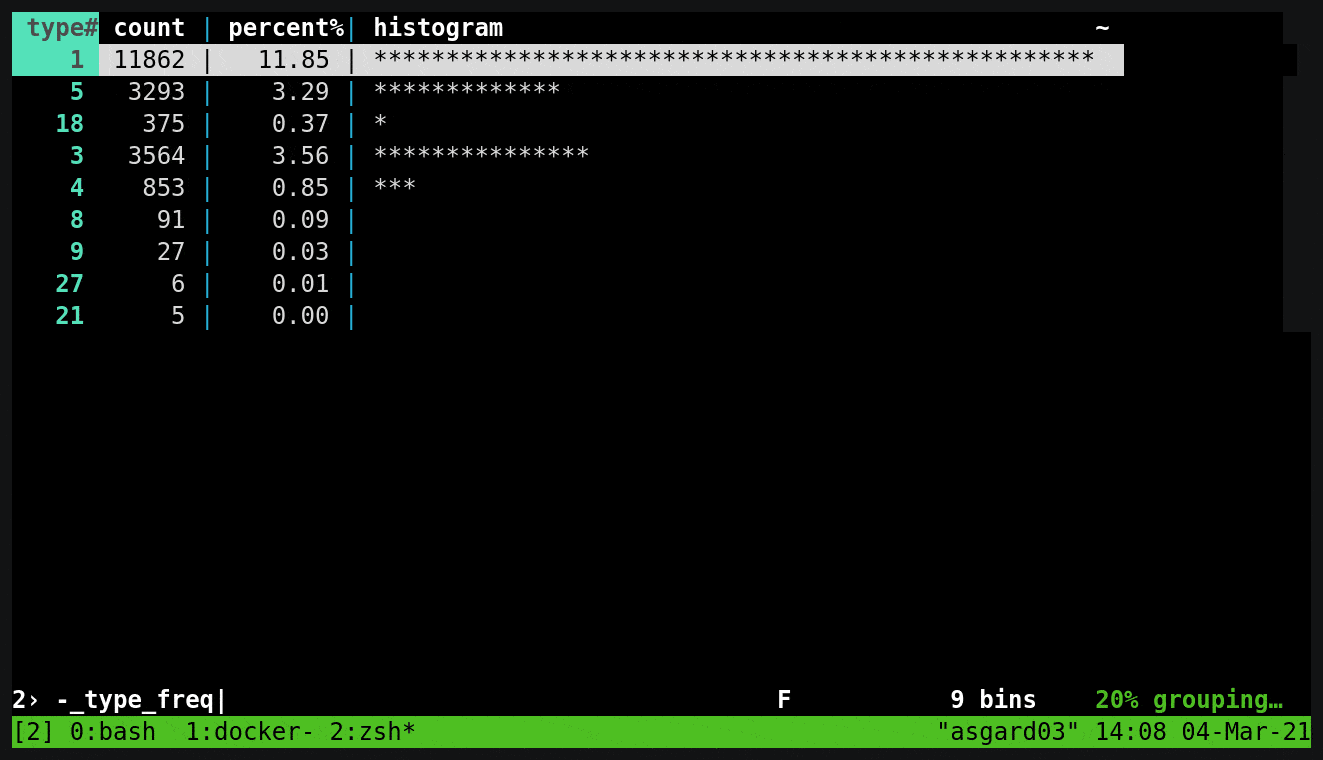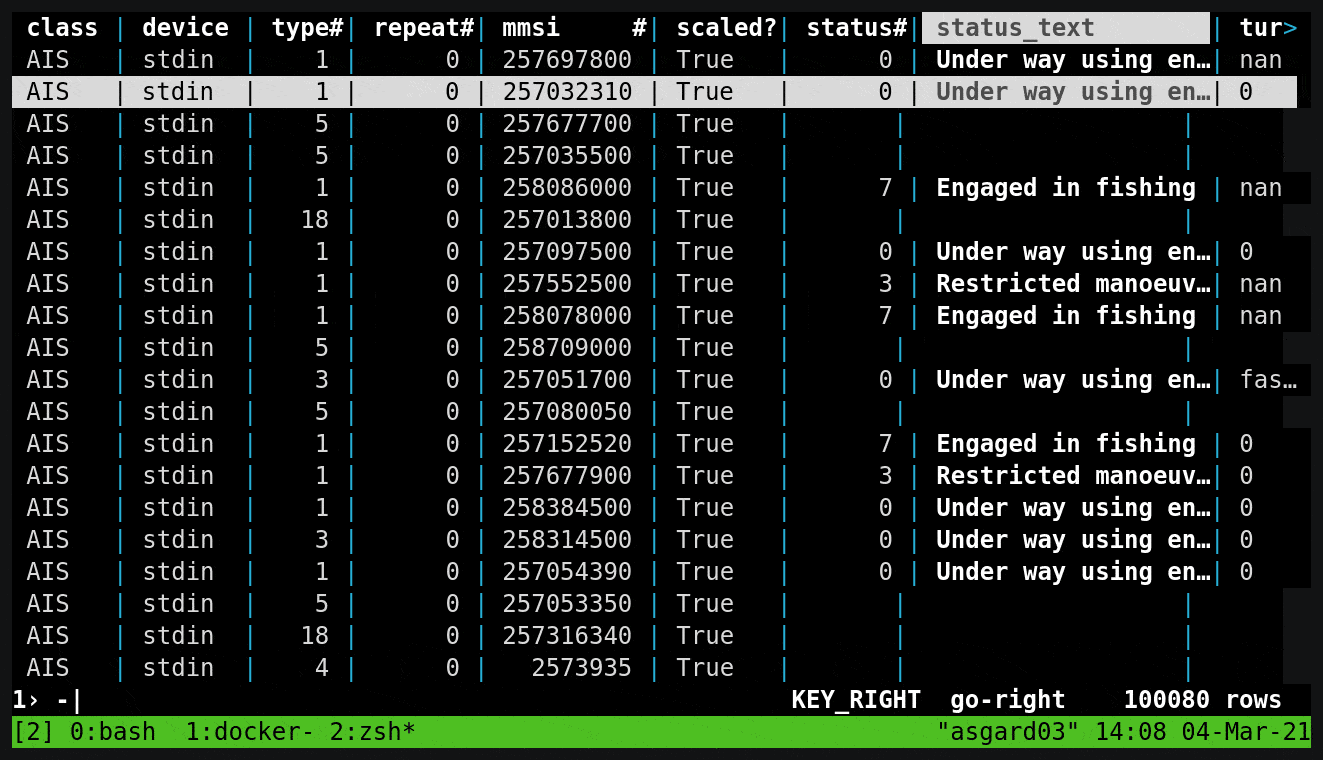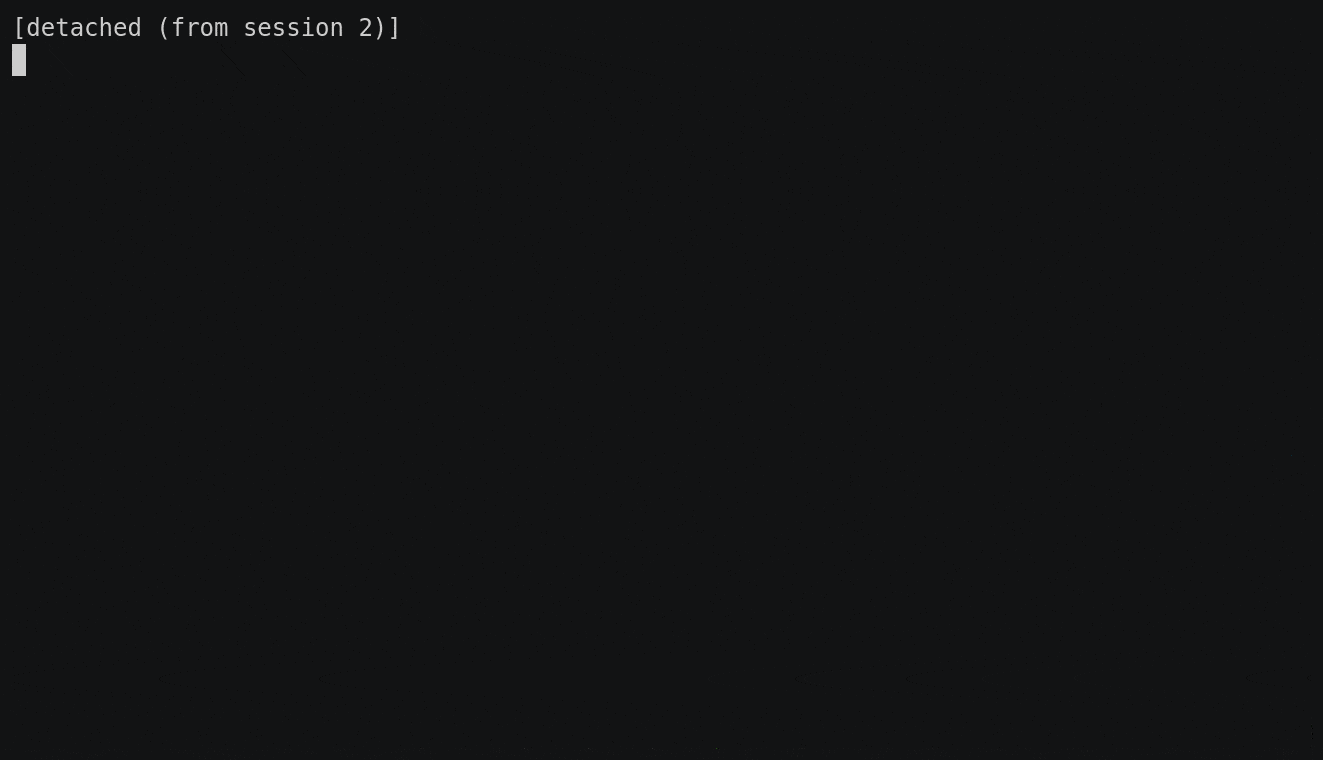
 kcat (kafkacat)
kcat (kafkacat)


 oracle
oracle
 Kafka Connect
Kafka Connect

 Kafka Connect
Kafka Connect
 Kafka Connect
Kafka Connect
 Kafka Connect
Kafka Connect

 Blogging
Blogging

 Kafka Connect
Kafka Connect





 Kafka Connect
Kafka Connect
 Kafka Connect
Kafka Connect
 DevRel
DevRel


 Kafka
Kafka
 Kafka Connect
Kafka Connect
 ksqlDB
ksqlDB
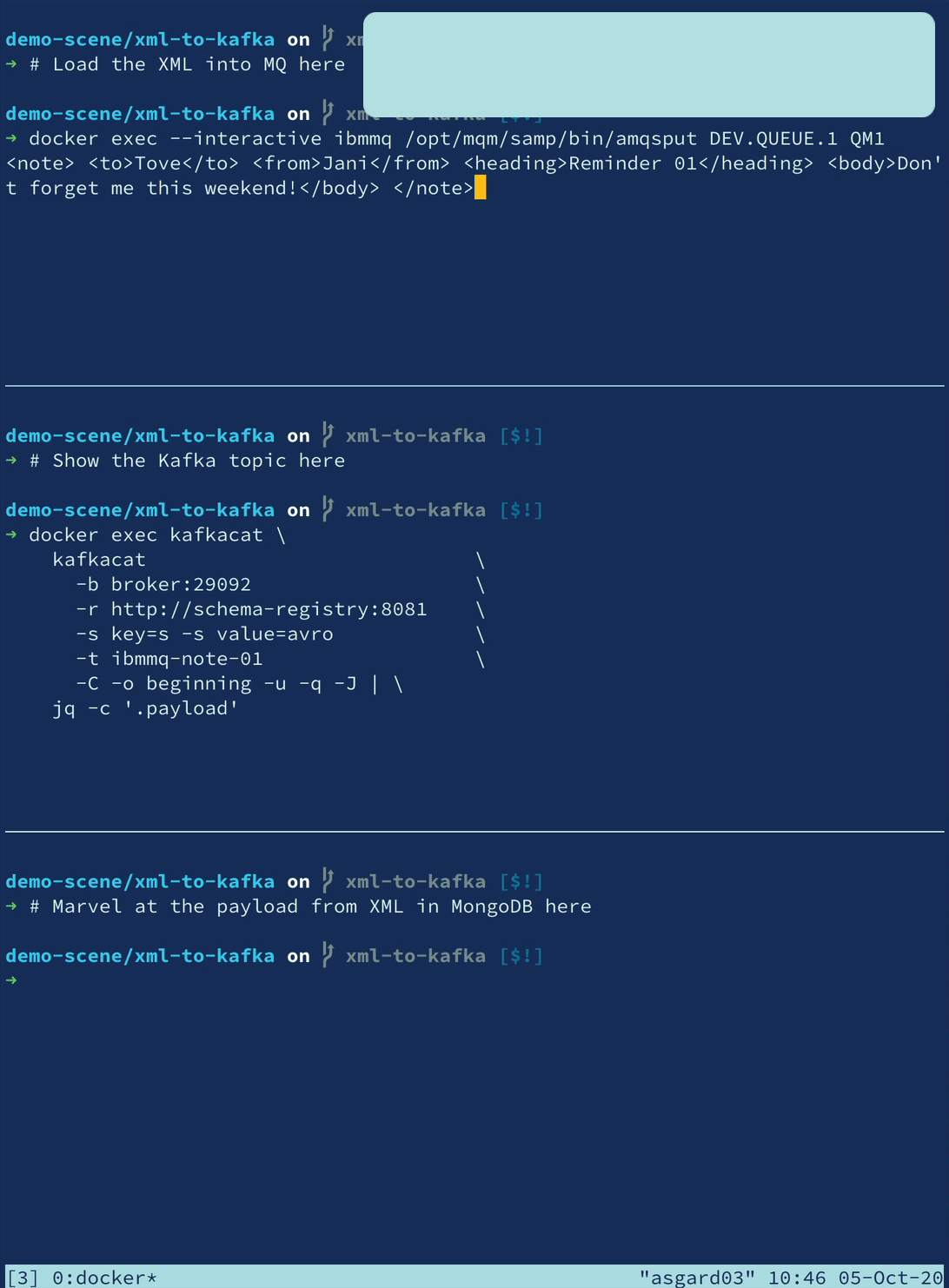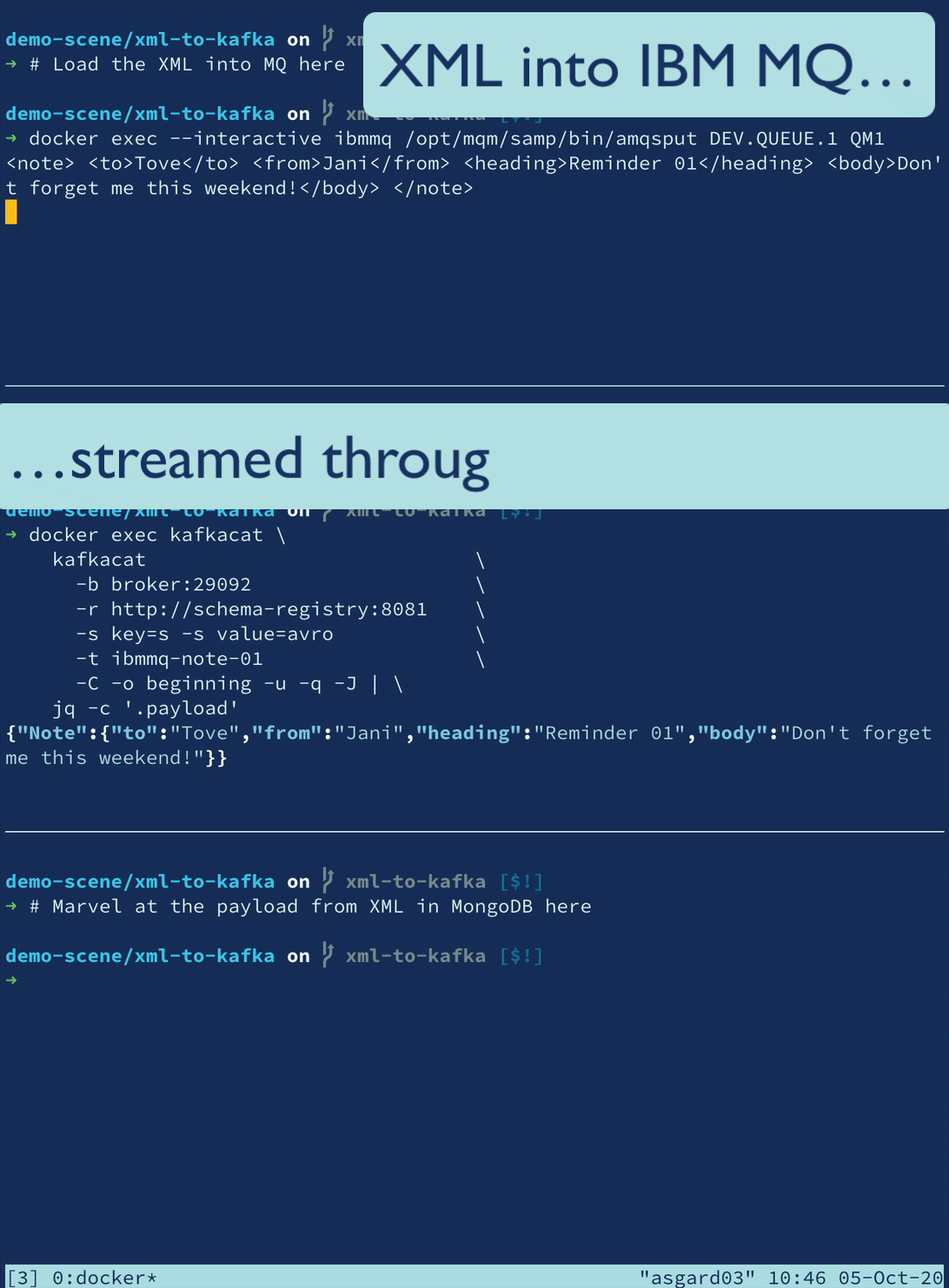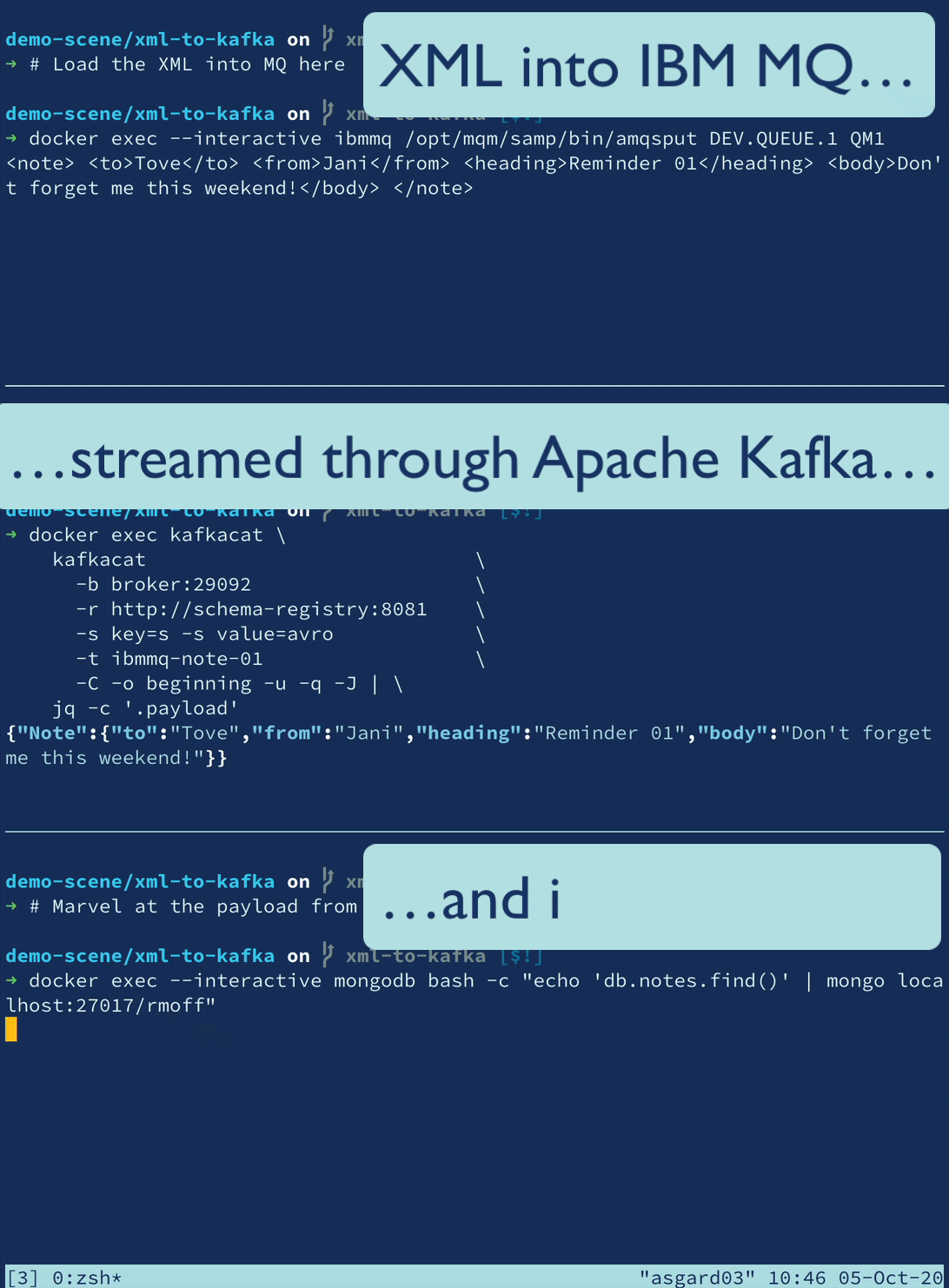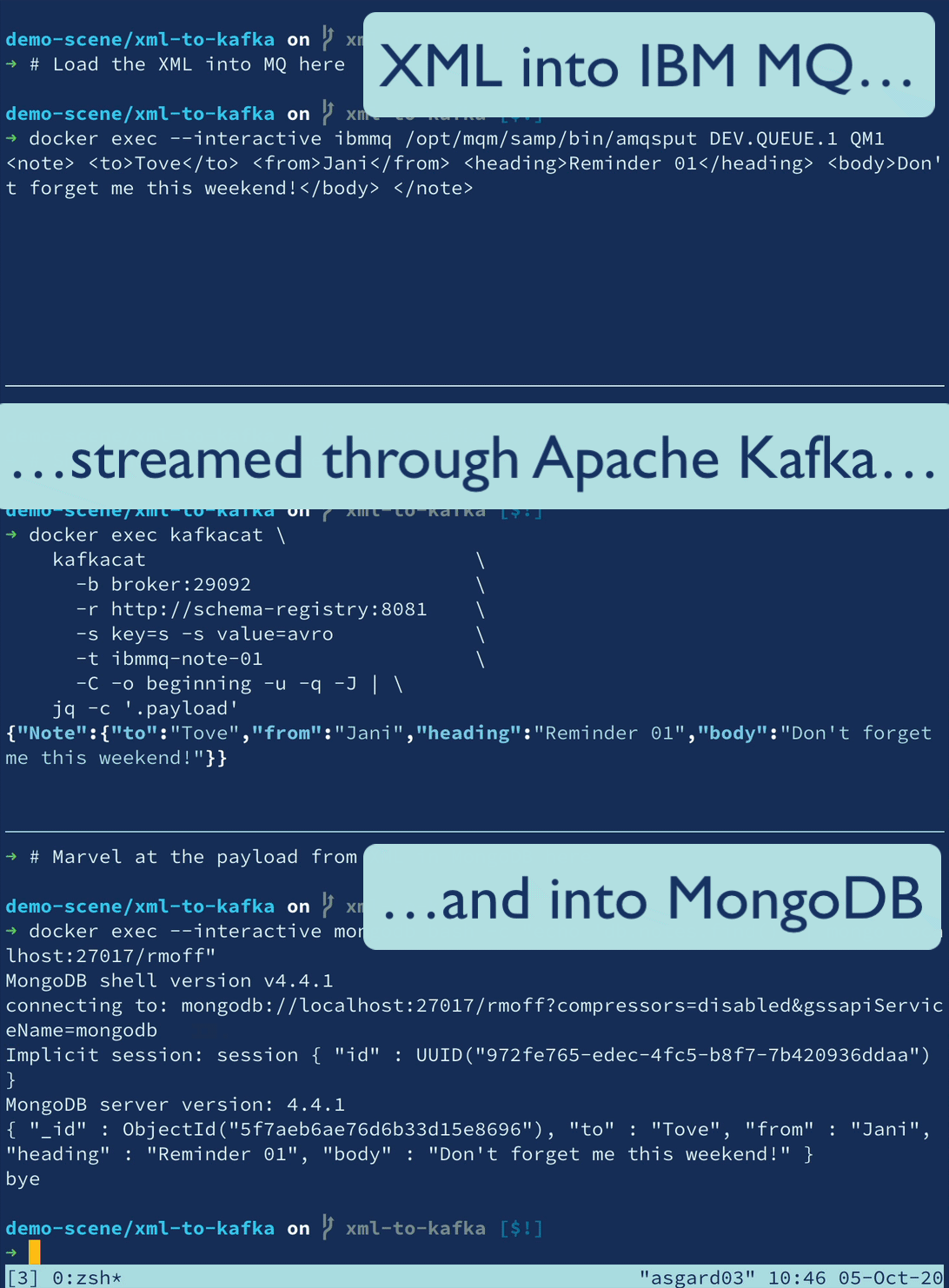 XML
XML
 XML
XML
XML
abcde
XML
XML
XML
abcde
 jq
jq

 MS SQL
MS SQL
 Hugo
Hugo


 sqlite
sqlite
 Go
Go
 Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
 Go
Go
 kcat (kafkacat)
Go
Go
Go
Go
Go
Go
Go
Go
Go
kcat (kafkacat)
Go
Go
Go
Go
Go
Go
Go
Go
Go
 Kafka Connect
Kafka Connect

 Kafka REST Proxy
ksqlDB
Kafka REST Proxy
ksqlDB
 Alfred
Alfred
 ksqlDB
ksqlDB
 Youtube
Youtube
 Confluent Cloud
Confluent Cloud

 pandoc
pandoc
 Kafka
Kafka

 Raspberry pi
Raspberry pi
 Kafka Connect
Kafka Connect

 Fantastical
Fantastical
 Kafka Connect
Kafka Connect
 ksqlDB
ksqlDB

<x> has been compiled by a more recent version of the Java Runtime
 Kafka Connect
Kafka Connect
 DevRel
DevRel
 RabbitMQ
RabbitMQ
 Kafka
Kafka

 unifi
unifi

 Kafka Connect
Kafka Connect
 Kafka Connect
Kafka Connect

 Debezium
Debezium
 Kafka Connect
Kafka Connect
 Kafka Connect
Kafka Connect

 kcat (kafkacat)
kcat (kafkacat)


 DevRel
DevRel

 Kafka Connect
Kafka Connect


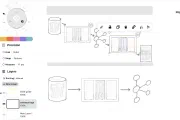


 Kafka Connect
Kafka Connect
 Kafka Connect
Kafka Connect
 Kafka Connect
Kafka Connect

 Kafka Connect
Kafka Connect







 Kafka Connect
Kafka Connect
 bash
bash


 docker
docker

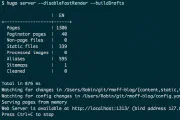
 docker
docker


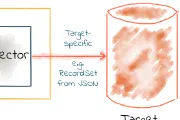


 docker
docker



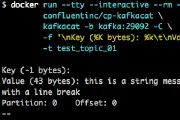
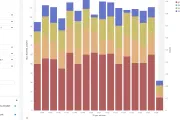 ksql
ksql



 elasticsearch
elasticsearch


 ksql
ksql
 Apache Kafka
Apache Kafka
 mongodb
mongodb
 mongodb
mongodb
 debezium
debezium

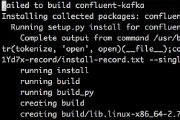 Apache Kafka
Apache Kafka

 apache kafka
apache kafka


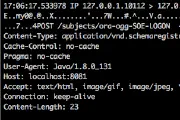
 Apache Kafka
Apache Kafka
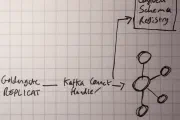
 goldengate
goldengate
 conferences
conferences
 lsblk
lsblk
 Apache Kafka
Apache Kafka
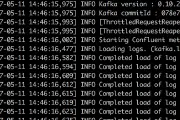 Apache Kafka
Apache Kafka
 vmdk
vmdk


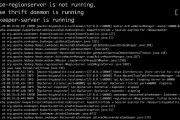
 Apache Kafka
Apache Kafka
Apache Spark
Apache Kafka
Apache Spark
Apache Spark
OBIEE
OBIEE
Apache Kafka
ogg
Apache Kafka
Data Visualisation
OBIEE
Kafka Connect
OBIEE
Kafka Connect
Apache Kafka
Apache Kafka
Apache Spark
Apache Kafka
Apache Spark
Apache Spark
OBIEE
OBIEE
Apache Kafka
ogg
Apache Kafka
Data Visualisation
OBIEE
Kafka Connect
OBIEE
Kafka Connect
 Apache Kafka
Apache Kafka
 ogg
Apache Kafka
Apache Kafka
ogg
Apache Kafka
Apache Kafka


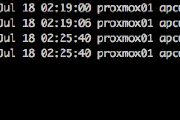
 ksqlDB
spark
ksqlDB
ksqlDB
spark
ksqlDB
 apache drill
apache drill
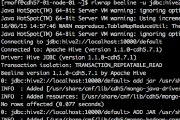 mogodb
mogodb
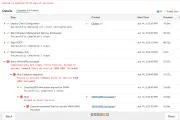 lxc
lxc
 Apache Spark
Apache Spark
Apache Spark
Apache Spark
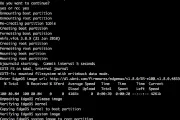 edgemax
edgemax
 docker
docker
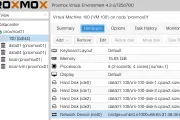
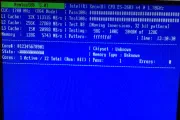 proxmox
proxmox


 OBIEE
OBIEE
 OBIEE
OBIEE
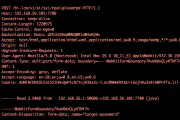 OBIEE
OBIEE
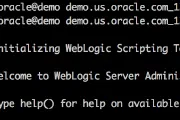 OBIEE
OBIEE

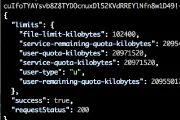 OBIEE
OBIEE
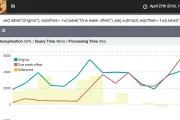 timelion
timelion
 OBIEE
OBIEE
 OBIEE
OBIEE
 OBIEE
OBIEE
OBIEE
OBIEE
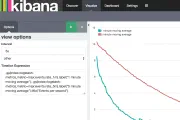 logstash
logstash
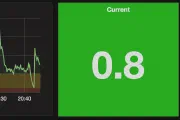 influxdb
influxdb
 conferences
conferences

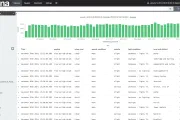 R
R
 OBIEE
OBIEE
 elasticsearch
elasticsearch
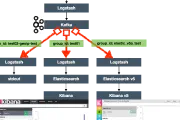 apache kafka
apache kafka


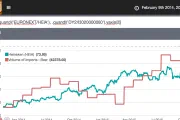
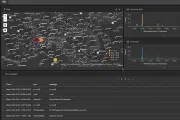
 OBIEE
OBIEE
 logstash
logstash
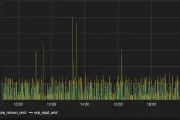

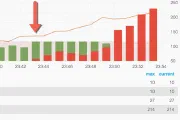
 Monitoring
Monitoring

 OBIEE
OBIEE
 OBIEE
OBIEE
 Apache Kafka
Apache Kafka
 OBIEE
Apache Kafka
OBIEE
Apache Kafka
 OBIEE
OBIEE
 OBIEE
OBIEE
 OBIEE
OBIEE
 Elasticsearch
Elasticsearch
 Elasticsearch
OBIEE
OBIEE
Elasticsearch
Elasticsearch
Linux
Linux
OBIEE
OBIEE
Elasticsearch
Elasticsearch
Linux
Elasticsearch
OBIEE
Monitoring
OBIEE
Monitoring
Monitoring
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
Oracle GoldenGate
Monitoring
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
inventory
windows
fedora
hp
etl
copy_table_stats
documentation
oracle
io
bi
dwh
etl
jmx
OBIEE
support
OBIEE
io
OBIEE
informatica
bi
io
documentation
oracle
hack
dac
oracle
jmx
cluster
OBIEE
OBIEE
OBIEE
cluster
OBIEE
loadrunner
loadrunner
oracle
oracle
OBIEE
OBIEE
hack
otn
apache
obia
oas
jmanage
oas
oas
dac
bi-publisher
bi-publisher
Elasticsearch
OBIEE
OBIEE
Elasticsearch
Elasticsearch
Linux
Linux
OBIEE
OBIEE
Elasticsearch
Elasticsearch
Linux
Elasticsearch
OBIEE
Monitoring
OBIEE
Monitoring
Monitoring
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
Oracle GoldenGate
Monitoring
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
OBIEE
inventory
windows
fedora
hp
etl
copy_table_stats
documentation
oracle
io
bi
dwh
etl
jmx
OBIEE
support
OBIEE
io
OBIEE
informatica
bi
io
documentation
oracle
hack
dac
oracle
jmx
cluster
OBIEE
OBIEE
OBIEE
cluster
OBIEE
loadrunner
loadrunner
oracle
oracle
OBIEE
OBIEE
hack
otn
apache
obia
oas
jmanage
oas
oas
dac
bi-publisher
bi-publisher