Kicking the tyres on the new DuckDB UI
I wrote a couple of weeks ago about using DuckDB and Rill Data to explore a new data source that I’m working with. I wanted to understand the data’s structure and distribution of values, as well as …
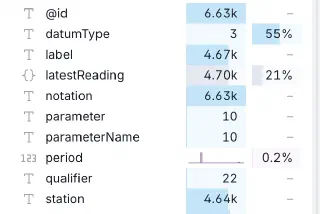
I wrote a couple of weeks ago about using DuckDB and Rill Data to explore a new data source that I’m working with. I wanted to understand the data’s structure and distribution of values, as well as …
 Confluent Cloud
Confluent Cloud

 Blogging
Blogging



 DuckDB
DuckDB
 DuckDB
DuckDB




 Postgres
Postgres





 Decodable
Decodable

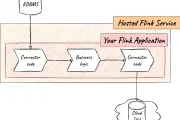
 Apache Flink
Apache Flink
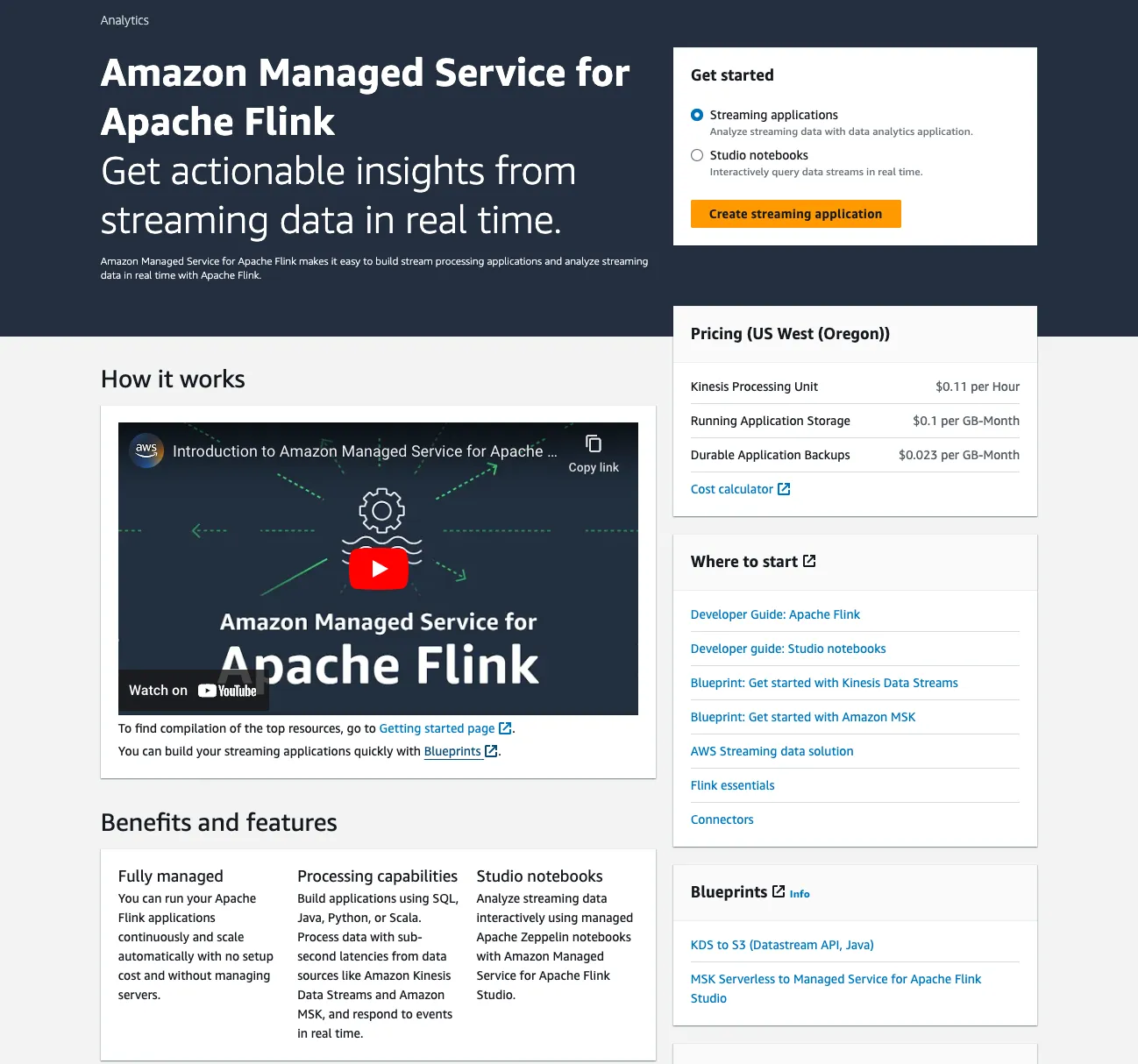 Apache Flink
Apache Flink
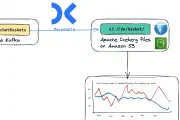 Apache Kafka
Apache Kafka

 RSS
RSS


 Apache Flink
Apache Flink

 Kafka Summit
Kafka Summit






 Antora
Antora
 GitHub
GitHub
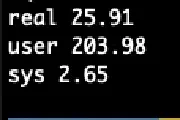
 Antora
Antora



 Flink JDBC
Flink JDBC

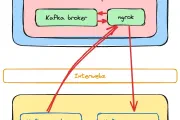
 LAF
LAF