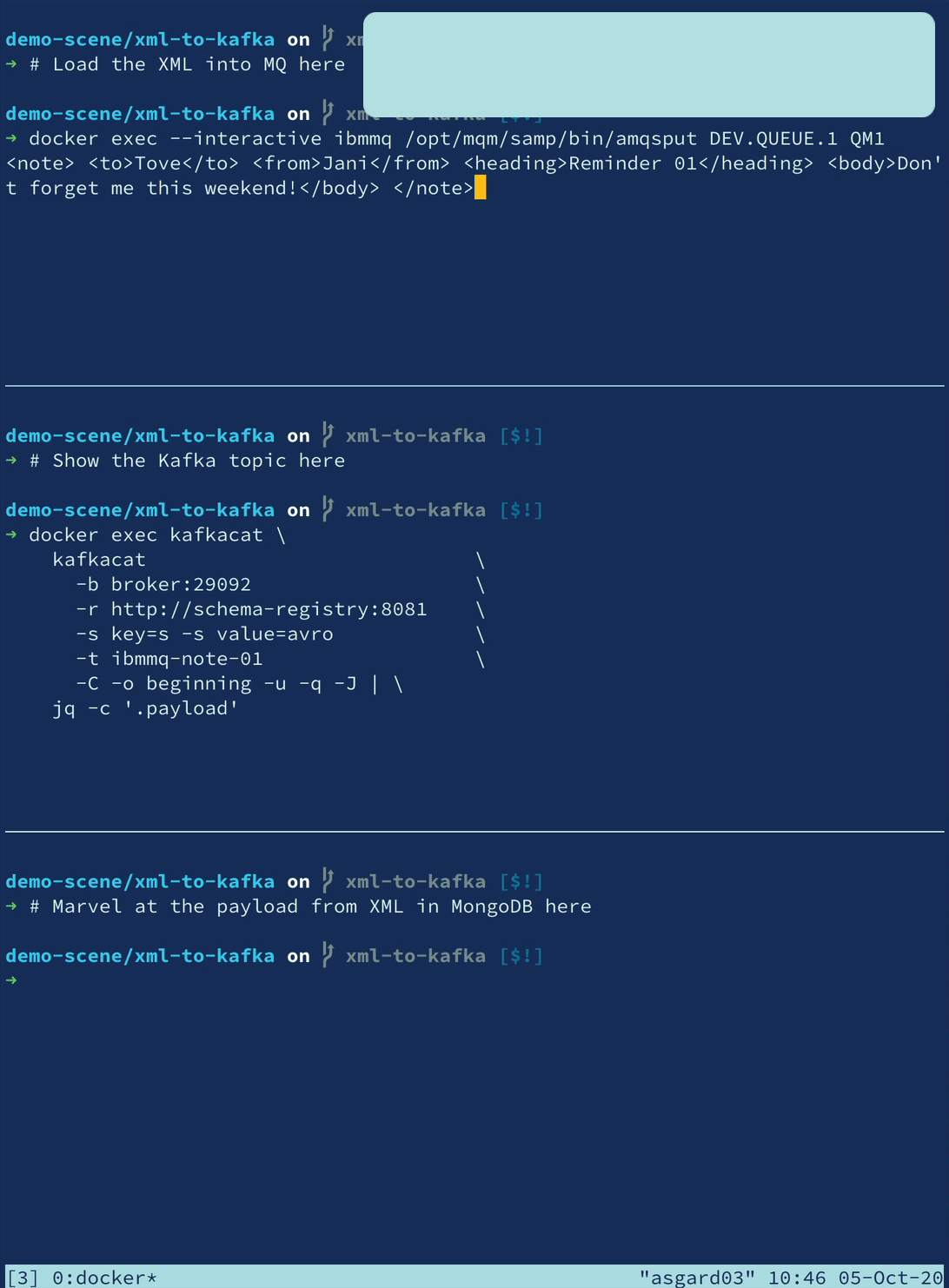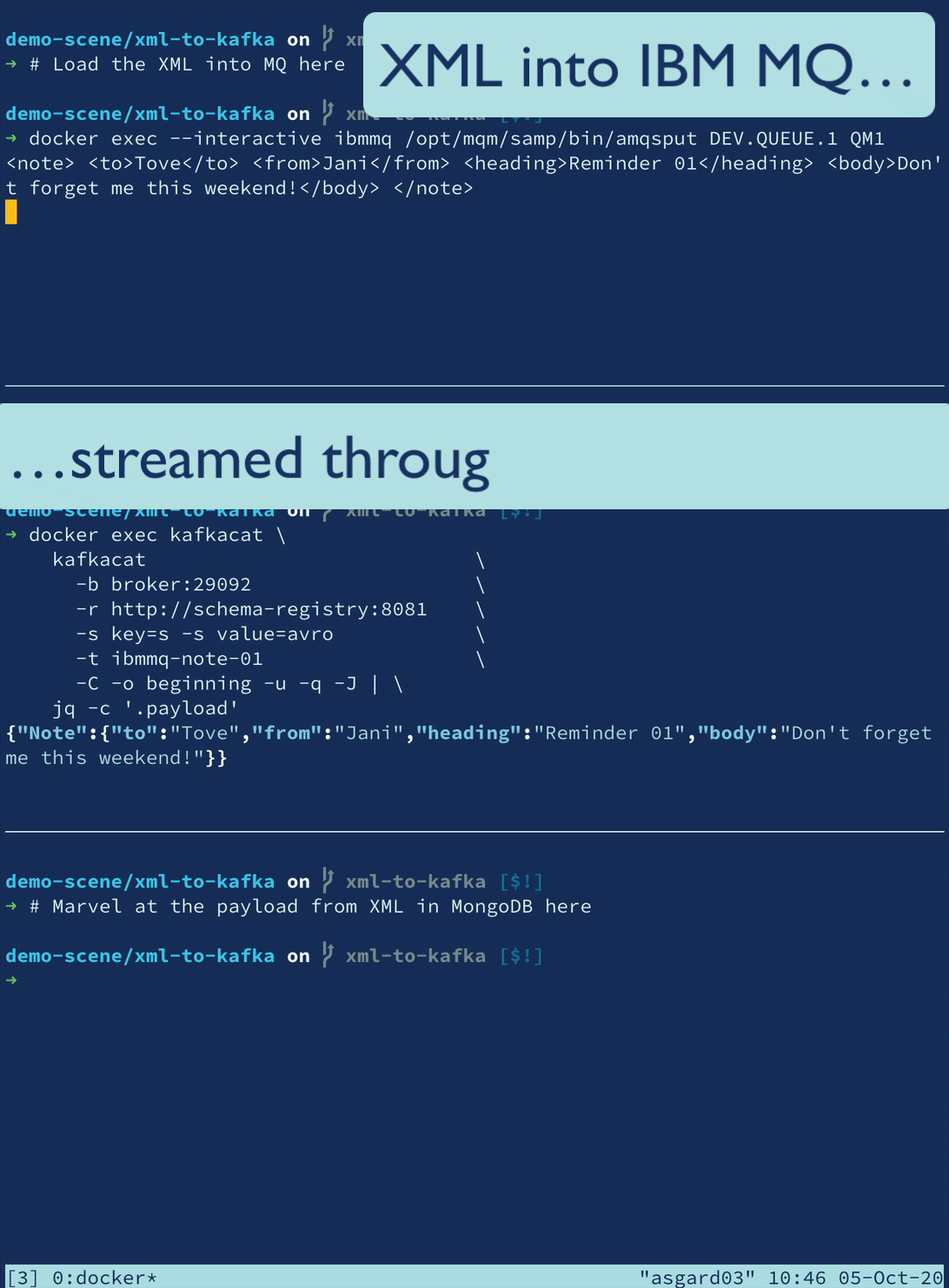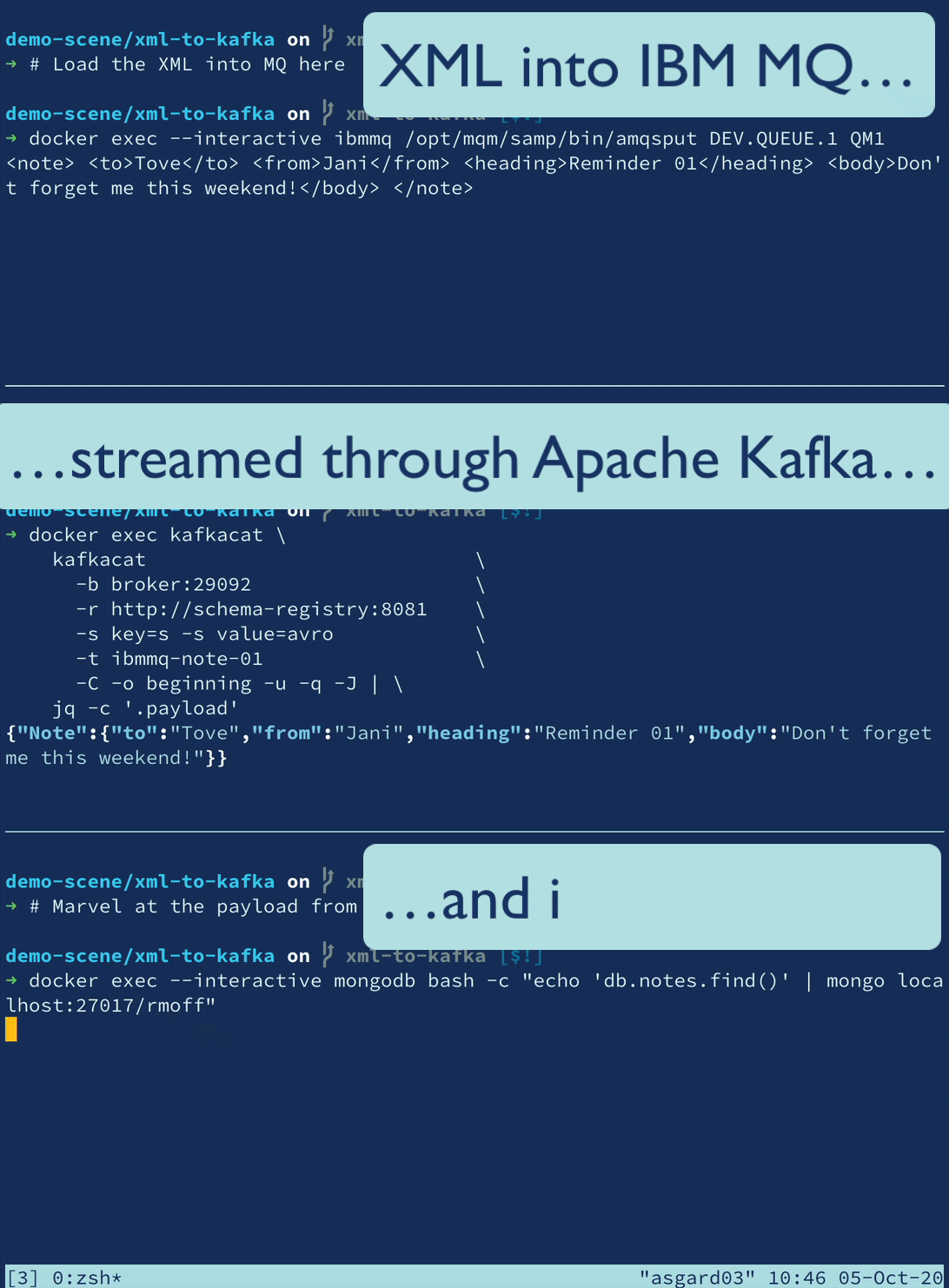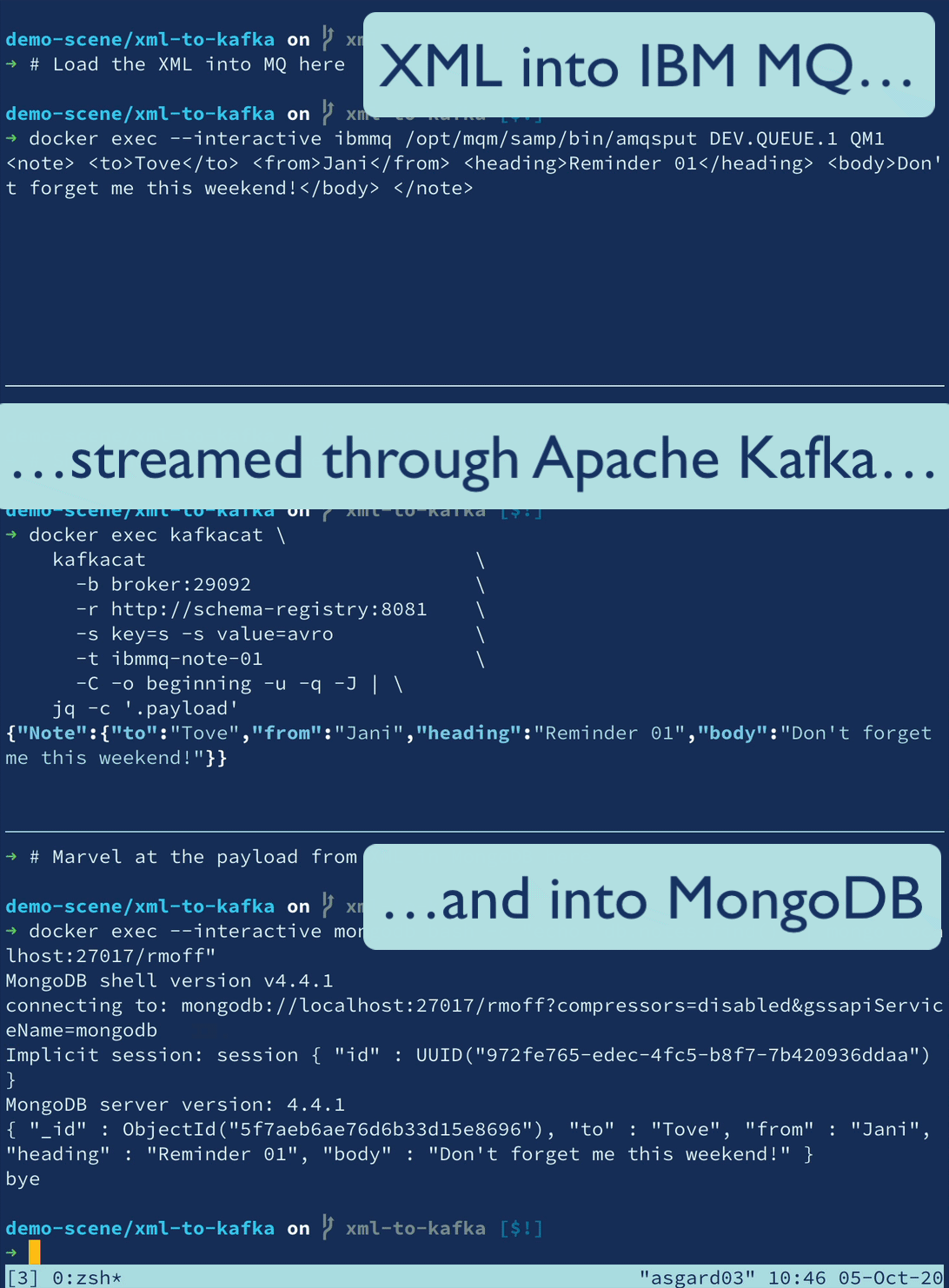
🎄 Twelve Days of SMT 🎄 - Day 12: Community Transformations
Apache Kafka ships with many Single Message Transformations (SMT) included - but the great thing about it being an open API is that people can, and do, write their own transformations. Many of these …