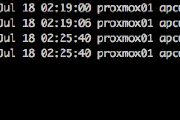
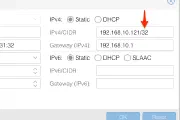
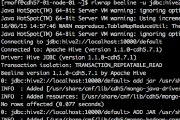
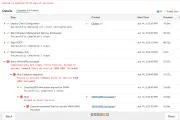
All You Ever Wanted to Know About OBIEE Performance…but were too afraid to ask
This post originally appeared on the Rittman Mead blog. At the Polish Oracle Users Group (POUG) conference this week I’m presenting one of my favourite talks, [Still] No Silver Bullets - OBIEE …