
In this blog article I’ll show you how you can use the confluent CLI to set up a Kafka cluster on Confluent Cloud, the necessary API keys, and then a managed connector.
The connector I’m setting up is the HTTP Source (v2) connector.
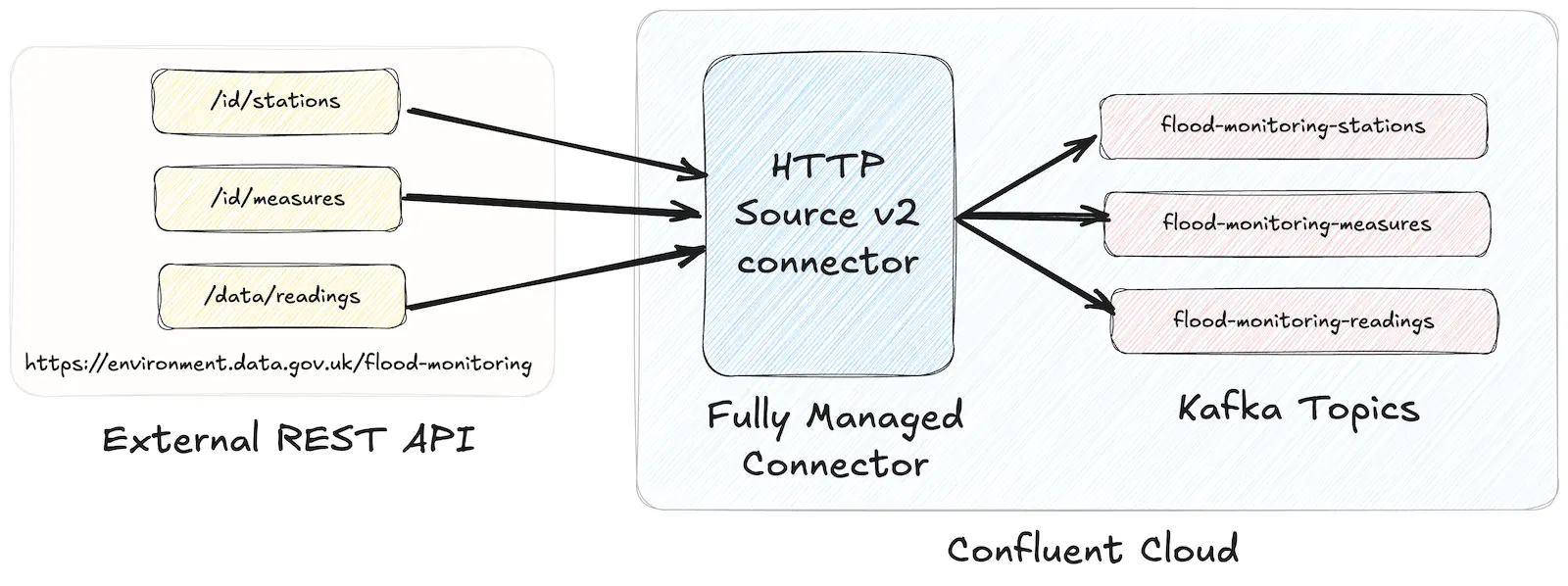
It’s part of a pipeline that I’m working on to pull in a feed of data from the UK Environment Agency for processing. The data is spread across three endpoints, and one of the nice features of the HTTP Source (v2) connector is that one connector can pull data from more than one endpoint.
As part of learning about Confluent Cloud and its support for Kafka Connect, I wanted to understand how to configure fully-managed connectors from the CLI. The UI is nice, but the CLI is repeatable. Whilst there is Terraform support for resources in Confluent Cloud, I’ve yet to learn Terraform so this would take me off a whole different yak-shaving path that I’m going to save for another day.
Setup 🔗
To start with, login to Confluent Cloud:
$ confluent login --save
To actually start with, you need to go and sign up for Confluent Cloud (which you can even do from the CLI with confluent cloud-signup!). Then come back here :)
|
Now we’ll create an environment within our organisation and set it as the active environment for the CLI:
$ confluent environment create rmoff
# The above command with return an ID for the environment, which
# is what you specify in the next command here
$ confluent environment use env-253ngyWhat does any environment need? A Kafka cluster!
$ confluent kafka cluster create cluster00 --cloud aws --region us-west-2The output of this command tells us various things about the cluster, including its ID and broker. I’m going to store these in local environment variables to make things easier later on when we want to use them.
+----------------------+---------------------------------------------------------+
[…]
| ID | lkc-qnygo6 |
| Endpoint | SASL_SSL://pkc-rgm37.us-west-2.aws.confluent.cloud:9092 |
[…]
+----------------------+---------------------------------------------------------+
$ export CNFL_ENV=env-253ngy
$ export CNFL_KAFKA_CLUSTER=lkc-qnygo6
$ export CNFL_KAFKA_BROKER=pkc-rgm37.us-west-2.aws.confluent.cloud:9092Having created the cluster, we’ll set it as the active one for our CLI session:
$ confluent kafka cluster use $CNFL_KAFKA_CLUSTER
Set Kafka cluster lkc-qnygo6 as the active cluster for environment env-253ngy.When we created the cluster we got a Schema Registry with it—we need to get the ID and endpoint details:
$ confluent schema-registry cluster describe
+----------------------+----------------------------------------------------+
| Name | Always On Stream Governance |
| | Package |
| Cluster | lsrc-g70zm3 |
| Endpoint URL | https://psrc-13go8y7.us-west-2.aws.confluent.cloud |
[…]
+----------------------+----------------------------------------------------+
export CNFL_SR_HOST=psrc-13go8y7.us-west-2.aws.confluent.cloud
export CNFL_SR_ID=lsrc-g70zm3API Keys 🔗
| I’m obviously not sharing the actual API keys generated by the commands below, and have instead put placeholders. |
We need to create some API keys for the calls we’re going to be making to interact with the cluster.
First, one for the Kafka cluster itself:
$ confluent api-key create --resource $CNFL_KAFKA_CLUSTER
It may take a couple of minutes for the API key to be ready.
Save the API key and secret. The secret is not retrievable later.
+------------+------------------------------------------------------------------+
| API Key | (XXXmy-kafka-api-keyXXX) |
| API Secret | (XXXmy-kafka-api-secretXXX) |
+------------+------------------------------------------------------------------+Then one for the cloud resources:
$ confluent api-key create --resource cloud
It may take a couple of minutes for the API key to be ready.
Save the API key and secret. The secret is not retrievable later.
+------------+------------------------------------------------------------------+
| API Key | (XXXmy-cloud-api-keyXXX) |
| API Secret | (XXXmy-cloud-api-secretXXX) |
+------------+------------------------------------------------------------------+Finally, for the Schema Registry:
$ confluent api-key create --resource $CNFL_SR_ID
It may take a couple of minutes for the API key to be ready.
Save the API key and secret. The secret is not retrievable later.
+------------+------------------------------------------------------------------+
| API Key | (XXXmy-schema-registry-api-keyXXX) |
| API Secret | (XXXmy-schema-registry-api-secretXXX) |
+------------+------------------------------------------------------------------+Having done this, we’ll store the API keys and secrets in local environment variables to make it easy to re-use them later on.
export CNFL_KC_API_KEY=(XXXmy-kafka-api-keyXXX)
export CNFL_KC_API_SECRET=(XXXmy-kafka-api-secretXXX)
export CNFL_CLOUD_API_KEY=(XXXmy-cloud-api-keyXXX)
export CNFL_CLOUD_API_SECRET=(XXXmy-cloud-api-secretXXX)
export CNFL_SR_API_KEY=(XXXmy-schema-registry-api-keyXXX)
export CNFL_SR_API_SECRET=(XXXmy-schema-registry-api-secretXXX)| Storing API details in environment variables is a risky thing to do if anyone were to get hold of your machine, your bash history, etc etc. There are much better ways to manage secrets; I’m just taking the easy (but insecure) route here. |
The Confluent Cloud API 🔗
You can use the confluent CLI to create connectors, but I ended up using a REST call directly.
If you do use the confluent CLI note that the terminology is to create a Connect "Cluster", rather than a connector.
The Confluent Cloud API uses an API key for authentication.
For working with connectors the API key should be created for access to the cloud resource (see confluent api-key create --resource cloud above).
The docs show how to create an Authorization header with a base64-encoded representation of the API key.
A simpler way is to pass it as a username/password combo, separated by a colon (i.e. API_KEY:API_SECRET).
In curl you use --user like this:
curl --request GET \
--url https://api.confluent.cloud/org/v2/organizations \
--user "(XXXmy-cloud-api-keyXXX):(XXXmy-cloud-api-secretXXX)"Using httpie (my favourite tool for this kind of stuff) it’s --auth
http GET https://api.confluent.cloud/org/v2/organizations \
--auth "(XXXmy-cloud-api-keyXXX):(XXXmy-cloud-api-secretXXX)"Create an HTTP Source connector for a single endpoint 🔗
We’ll start simple and make sure that this thing works for a single endpoint.
http PUT \
"https://api.confluent.cloud/connect/v1/environments/$CNFL_ENV/clusters/$CNFL_KAFKA_CLUSTER/connectors/env-agency--flood-monitoring-stations/config" \
--auth "$CNFL_CLOUD_API_KEY:$CNFL_CLOUD_API_SECRET" \
content-type:application/json \
connector.class="HttpSourceV2" \
name="" \
http.api.base.url="https://environment.data.gov.uk/flood-monitoring" \
api1.http.api.path="/id/stations" \
api1.http.offset.mode="SIMPLE_INCREMENTING" \
api1.http.initial.offset="0" \
api1.request.interval.ms="3600000" \
api1.topics="flood-monitoring-stations" \
kafka.api.key=$CNFL_KC_API_KEY \
kafka.api.secret=$CNFL_KC_API_SECRET \
output.data.format="AVRO" \
tasks.max="1"The documentation for the connector details all of the configuration options. Let’s take a look at what we’re going to configure:
| Property | Value | Notes |
|---|---|---|
|
|
This is the connector type we’re going to use. |
|
This config value isn’t used, but the element must be specified for the config to be valid. The name of the connector is taken from the URL path (see below). |
|
|
|
The base URL for the API endpoint. This will make a lot of sense later when we define more than one endpoint. |
|
|
The path to the API endpoint (to be added to the base URL) |
|
|
Since the endpoint provides a full set of the data each time we query it, these two settings are necessary to tell the connector to expect this and not try to page through the endpoint. |
|
|
|
|
|
Poll the endpoint once an hour (60 minutes / 3600 seconds / 3600000 ms) |
|
|
Which topic to write the endpoint response to |
|
|
How to serialise the data when writing it |
|
|
Credentials that the connector will use to write to the Kafka cluster |
|
|
|
|
|
How many tasks the connector can run (less relevant for a single endpoint, but important when we add more later) |
The Confluent Cloud REST API endpoint that we’re going to send this data to is:
https://api.confluent.cloud/connect/v1/environments/$CNFL_ENV/clusters/$CNFL_KAFKA_CLUSTER/connectors/flood-monitoring-stations/config"The component parts are broken out like this:
| Value | URL Element |
|---|---|
|
[fixed] Base URL |
|
Confluent Cloud Environment ID |
|
Kafka Cluster ID |
|
[fixed] Resource Type |
|
The name that you want to use for the connector |
|
[fixed] The configuration endpoint |
The /config API expects a PUT operation, and has the advantage over the related POST to /connectors in that it does an 'upsert'—if the connector doesn’t exist it creates it, and if it does, it updates it. That makes the REST call idempotent (a fancy way of saying you can run it repeatedly with the same result).
When we run the command we get back an HTTP status code which if all has gone well is this:
HTTP/1.1 200 OKChecking the status of a connector 🔗
The /status endpoint tells us about the connector, including its health and details of the tasks within it:
http GET "https://api.confluent.cloud/connect/v1/environments/$CNFL_ENV/clusters/$CNFL_KAFKA_CLUSTER/connectors/env-agency--flood-monitoring-stations/status" \
--auth "$CNFL_CLOUD_API_KEY:$CNFL_CLOUD_API_SECRET"
Use the -b flag with httpie if you want to supress the response headers
|
{
"connector": {
"state": "RUNNING",
"trace": "",
"worker_id": "env-agency--flood-monitoring-stations"
},
"error_details": null,
"errors_from_trace": [],
"is_csfle_error": false,
"name": "env-agency--flood-monitoring-stations",
"override_message": "",
"tasks": [
{
"id": 0,
"msg": "",
"state": "RUNNING",
"worker_id": "env-agency--flood-monitoring-stations"
}
],
"type": "source",
"validation_error_category_info": null,
"validation_errors": []
}You could use jq to simplify this:
http GET "https://api.confluent.cloud/connect/v1/environments/$CNFL_ENV/clusters/$CNFL_KAFKA_CLUSTER/connectors/env-agency--flood-monitoring-stations/status" \
--auth "$CNFL_CLOUD_API_KEY:$CNFL_CLOUD_API_SECRET" | \
jq '.connector.state'"RUNNING"If you prefer, you can use the Confluent CLI too:
$ # Get the connector ID
$ confluent connect cluster list
ID | Name | Status | Type | Trace
-------------+---------------------------------------+---------+--------+--------
lcc-r19wjk | env-agency--flood-monitoring-stations | RUNNING | source |
$ # Get its details, including status
$ confluent connect cluster describe lcc-r19wjk
Connector Details
+--------+---------------------------------------+
| ID | lcc-r19wjk |
| Name | env-agency--flood-monitoring-stations |
| Status | RUNNING |
| Type | source |
+--------+---------------------------------------+
Task Level Details
Task | State
-------+----------
0 | RUNNING
Configuration Details
Config | Value
---------------------------+----------------------------------------------------------
api1.http.api.path | /id/stations
api1.http.initial.offset | 0
api1.request.interval.ms | 3600000
api1.topics | flood-monitoring-stations
cloud.environment | prod
cloud.provider | aws
connector.class | HttpSourceV2
http.api.base.url | https://environment.data.gov.uk/flood-monitoring
kafka.api.key | ****************
kafka.api.secret | ****************
kafka.endpoint | SASL_SSL://pkc-rgm37.us-west-2.aws.confluent.cloud:9092
kafka.region | us-west-2
name | env-agency--flood-monitoring-stations
output.data.format | AVRO
tasks.max | 1For brevity, you can ask the Confluent CLI to return JSON that you then filter with jq:
confluent connect cluster describe lcc-r19wjk --output json | jq '.connector.status'
"RUNNING"Looking at the data 🔗
Based on the above configuration and the fact that the connector is RUNNING, we should hopefully see data written to the flood-monitoring-stations topic.
As above, you can use the Confluent CLI, or your own approach for this.
I’m a big fan of kcat so tend to gravitate towards it, but it’s up to you.
Here’s kcat listing (-L) the topics on my Confluent Cloud Kafka cluster:
$ kcat -b $CNFL_KAFKA_BROKER \
-X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN \
-X sasl.username=$CNFL_KC_API_KEY -X sasl.password=$CNFL_KC_API_SECRET \
-L
Metadata for all topics (from broker -1: sasl_ssl://pkc-rgm37.us-west-2.aws.confluent.cloud:9092/bootstrap):
6 brokers:
broker 0 at b0-pkc-rgm37.us-west-2.aws.confluent.cloud:9092 (controller)
broker 1 at b1-pkc-rgm37.us-west-2.aws.confluent.cloud:9092
broker 2 at b2-pkc-rgm37.us-west-2.aws.confluent.cloud:9092
broker 3 at b3-pkc-rgm37.us-west-2.aws.confluent.cloud:9092
broker 4 at b4-pkc-rgm37.us-west-2.aws.confluent.cloud:9092
broker 5 at b5-pkc-rgm37.us-west-2.aws.confluent.cloud:9092
2 topics:
topic "error-lcc-r19wjk" with 1 partitions:
partition 0, leader 4, replicas: 4,2,0, isrs: 4,2,0
topic "flood-monitoring-stations" with 1 partitions:
partition 0, leader 2, replicas: 2,4,0, isrs: 2,4,0Doing the same with Confluent CLI:
$ confluent kafka topic list
Name | Internal | Replication Factor | Partition Count
--------------------------------+----------+--------------------+------------------
error-lcc-r19wjk | false | 3 | 1
flood-monitoring-stations | false | 3 | 1To query the topic, bearing in mind that it’s serialised with Avro and so we need the Schema Registry too, I’m using kcat.
Here is how to read (-C) a single message (-c1):
$ kcat -b $CNFL_KAFKA_BROKER \
-X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN \
-X sasl.username=$CNFL_KC_API_KEY -X sasl.password=$CNFL_KC_API_SECRET \
-s avro -r https://$CNFL_SR_API_KEY:$CNFL_SR_API_SECRET@$CNFL_SR_HOST \
-C -t flood-monitoring-stations -c1It turns out the payload is huge—more than will fit on a terminal to inspect.
We can use the Linux tool wc to see quite how big it is:
$ kcat -q -b $CNFL_KAFKA_BROKER \
-X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN \
-X sasl.username=$CNFL_KC_API_KEY -X sasl.password=$CNFL_KC_API_SECRET \
-s avro -r https://$CNFL_SR_API_KEY:$CNFL_SR_API_SECRET@$CNFL_SR_HOST \
-C -t flood-monitoring-stations -c1 | wc --bytes
5002406Huh—4.77 MB! We’re gonna need a bigger monitor ;)
Let’s look at the payload structure:
$ kcat -q -b $CNFL_KAFKA_BROKER \
-X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN \
-X sasl.username=$CNFL_KC_API_KEY -X sasl.password=$CNFL_KC_API_SECRET \
-s avro -r https://$CNFL_SR_API_KEY:$CNFL_SR_API_SECRET@$CNFL_SR_HOST \
-C -t flood-monitoring-stations -c1 | jq 'keys'
[
"_40context",
"items",
"meta"
]Based on the source API’s documentation we know items is an array, so let’s inspect on element of it:
$ kcat -q -b $CNFL_KAFKA_BROKER \
-X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN \
-X sasl.username=$CNFL_KC_API_KEY -X sasl.password=$CNFL_KC_API_SECRET \
-s avro -r https://$CNFL_SR_API_KEY:$CNFL_SR_API_SECRET@$CNFL_SR_HOST \
-C -t flood-monitoring-stations -c1 | jq '.items[1]'{
"_40id": "http://environment.data.gov.uk/flood-monitoring/id/stations/E2043",
"RLOIid": {
"string": "6022"
},
"catchmentName": {
"string": "Welland"
},
"dateOpened": {
"int": 8035
},
"easting": {
"string": "528000"
},
"label": "Surfleet Sluice",
[…]This all looks good. We’re going to about adding the other two endpoints into this connector. But first—let’s tidy up after ourselves and remove this version of the connector.
Deleting a managed connector on Confluent Cloud 🔗
My brain likes working with well-designed APIs and the HTTP vocabulary:
-
You
PUTa/config -
You
GETa/status
To list the connectors that have been created? It’s a GET against /connectors
$ http GET "https://api.confluent.cloud/connect/v1/environments/$CNFL_ENV/clusters/$CNFL_KAFKA_CLUSTER/connectors" \
--auth "$CNFL_CLOUD_API_KEY:$CNFL_CLOUD_API_SECRET" -b
[
"foo",
"env-agency--flood-monitoring-stations",
"flood-monitoring",
"test"
]So you can pretty much guess the Confluent Cloud REST API for deleting a connector—you DELETE a $connector-name
$ http DELETE \
"https://api.confluent.cloud/connect/v1/environments/$CNFL_ENV/clusters/$CNFL_KAFKA_CLUSTER/connectors/env-agency--flood-monitoring-stations" \
--auth "$CNFL_CLOUD_API_KEY:$CNFL_CLOUD_API_SECRET"
HTTP/1.1 200 OK
As discussed above, we could PUT the new config to this connector instead of deleting and recreating it, but I want to use a new name—plus this gives me an excuse to illustrate the DELETE endpoint :)
|
Creating an HTTP Source connector for multiple API endpoints 🔗
The HTTP source (v2) connector supports ingesting data with a single connector from multiple API endpoints with the same base URL. Our endpoints here are:
-
/id/stations(as above)
The core parts of configuration stay as they were, but we now add in api2 and api3 configuration.
We also need to define apis.num since it’s now greater than the default of one.
In the example below I’ve added in additional line breaks so that you can see the relevant groupings of the configuration.
http PUT \
"https://api.confluent.cloud/connect/v1/environments/$CNFL_ENV/clusters/$CNFL_KAFKA_CLUSTER/connectors/env-agency--flood-monitoring/config" \
--auth "$CNFL_CLOUD_API_KEY:$CNFL_CLOUD_API_SECRET" \
content-type:application/json \
connector.class="HttpSourceV2" \
name="" \
\
http.api.base.url="https://environment.data.gov.uk/flood-monitoring" \
apis.num="3" \
api1.http.api.path="/id/stations" \
api1.http.offset.mode="SIMPLE_INCREMENTING" \
api1.http.initial.offset="0" \
api1.request.interval.ms="3600000" \
api1.topics="flood-monitoring-stations" \
\
api2.http.api.path="/id/measures" \
api2.http.offset.mode="SIMPLE_INCREMENTING" \
api2.http.initial.offset="0" \
api2.request.interval.ms="3600000" \
api2.topics="flood-monitoring-measures" \
\
api3.http.api.path="/data/readings?latest" \
api3.http.offset.mode="SIMPLE_INCREMENTING" \
api3.http.initial.offset="0" \
api3.request.interval.ms="900000" \
api3.topics="flood-monitoring-readings" \
\
kafka.api.key=$CNFL_KC_API_KEY \
kafka.api.secret=$CNFL_KC_API_SECRET \
output.data.format="AVRO" \
\
tasks.max="3"|
If you want to run your connector with more than one task ( |
Let’s check the status:
http GET "https://api.confluent.cloud/connect/v1/environments/$CNFL_ENV/clusters/$CNFL_KAFKA_CLUSTER/connectors/env-agency--flood-monitoring/status" \
--auth "$CNFL_CLOUD_API_KEY:$CNFL_CLOUD_API_SECRET" \
--print b | jq '.tasks[]'
{
"id": 0,
"state": "RUNNING",
"worker_id": "env-agency--flood-monitoring",
"msg": ""
}
{
"id": 1,
"state": "RUNNING",
"worker_id": "env-agency--flood-monitoring",
"msg": ""
}
{
"id": 2,
"state": "RUNNING",
"worker_id": "env-agency--flood-monitoring",
"msg": ""
}Three tasks, all up and running :)
What about the data?
$ confluent kafka topic list
Name | Internal | Replication Factor | Partition Count
----------------------------+----------+--------------------+------------------
error-lcc-3mpv1j | false | 3 | 1
error-lcc-5nx9on | false | 3 | 1
error-lcc-5nxknn | false | 3 | 1
flood-monitoring-measures | false | 3 | 1
flood-monitoring-readings | false | 3 | 1
flood-monitoring-stations | false | 3 | 1-
Measures:
$ kcat -q -b $CNFL_KAFKA_BROKER \ -X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN \ -X sasl.username=$CNFL_KC_API_KEY -X sasl.password=$CNFL_KC_API_SECRET \ -s avro -r https://$CNFL_SR_API_KEY:$CNFL_SR_API_SECRET@$CNFL_SR_HOST \ -C -t flood-monitoring-measures -c1 | jq '.items[1]'{ "_40id": "http://environment.data.gov.uk/flood-monitoring/id/measures/1029TH-level-stage-i-15_min-mASD", "datumType": { "string": "http://environment.data.gov.uk/flood-monitoring/def/core/datumASD" }, "label": "RIVER DIKLER AT BOURTON ON THE WATER - level-stage-i-15_min-mASD", […] -
Stations:
$ kcat -q -b $CNFL_KAFKA_BROKER \ -X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN \ -X sasl.username=$CNFL_KC_API_KEY -X sasl.password=$CNFL_KC_API_SECRET \ -s avro -r https://$CNFL_SR_API_KEY:$CNFL_SR_API_SECRET@$CNFL_SR_HOST \ -C -t flood-monitoring-stations -c1 | jq '.items[1]'{ "_40id": "http://environment.data.gov.uk/flood-monitoring/id/stations/E2043", "RLOIid": { "string": "6022" }, "catchmentName": { "string": "Welland" }, "dateOpened": { "int": 8035 }, "easting": { "string": "528000" }, "label": "Surfleet Sluice", […] -
Readings:
$ kcat -q -b $CNFL_KAFKA_BROKER \ -X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN \ -X sasl.username=$CNFL_KC_API_KEY -X sasl.password=$CNFL_KC_API_SECRET \ -s avro -r https://$CNFL_SR_API_KEY:$CNFL_SR_API_SECRET@$CNFL_SR_HOST \ -C -t flood-monitoring-readings -c1 | jq '.items[1]'{ "_40id": "http://environment.data.gov.uk/flood-monitoring/data/readings/5312TH-level-stage-i-15_min-mASD/2025-02-21T13-45-00Z", "dateTime": 1740145500000, "measure": "http://environment.data.gov.uk/flood-monitoring/id/measures/5312TH-level-stage-i-15_min-mASD", "value": 22.664999999999999 }