2026
-
 Kafka Connect
Kafka Connect
2025
-
 18 Aug 2025 Kafka to Iceberg - Exploring the OptionsApache Iceberg
18 Aug 2025 Kafka to Iceberg - Exploring the OptionsApache Iceberg -
 Apache Iceberg
Apache Iceberg
-
 Confluent Cloud
Confluent Cloud
2021
-
 Confluent Cloud
Confluent Cloud
-
 ActiveMQ
ActiveMQ
-
 Kafka Connect
Kafka Connect
-
 11 Mar 2021 Kafka Connect - SQLSyntaxErrorException: BLOB/TEXT column … used in key specification without a key lengthKafka Connect
11 Mar 2021 Kafka Connect - SQLSyntaxErrorException: BLOB/TEXT column … used in key specification without a key lengthKafka Connect -
 Kafka Connect
Kafka Connect
-
 06 Jan 2021 Creating topics with Kafka ConnectKafka Connect
06 Jan 2021 Creating topics with Kafka ConnectKafka Connect -
 Kafka Connect
Kafka Connect
2020
-
 Kafka Connect
Kafka Connect
-
 Kafka Connect
Kafka Connect
-
 21 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 10: ReplaceFieldKafka Connect
21 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 10: ReplaceFieldKafka Connect -
 18 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 9: CastKafka Connect
18 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 9: CastKafka Connect -
 Kafka Connect
Kafka Connect
-
 16 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 7: TimestampRouterKafka Connect
16 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 7: TimestampRouterKafka Connect -
 15 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 6: InsertField IIKafka Connect
15 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 6: InsertField IIKafka Connect -
 14 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 5: MaskFieldKafka Connect
14 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 5: MaskFieldKafka Connect -
 11 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 4: RegExRouterKafka Connect
11 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 4: RegExRouterKafka Connect -
 10 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 3: FlattenKafka Connect
10 Dec 2020 🎄 Twelve Days of SMT 🎄 - Day 3: FlattenKafka Connect -
 Kafka Connect
Kafka Connect
-
 Kafka Connect
Kafka Connect
-
 Kafka
Kafka
-
 Kafka Connect
Kafka Connect
-
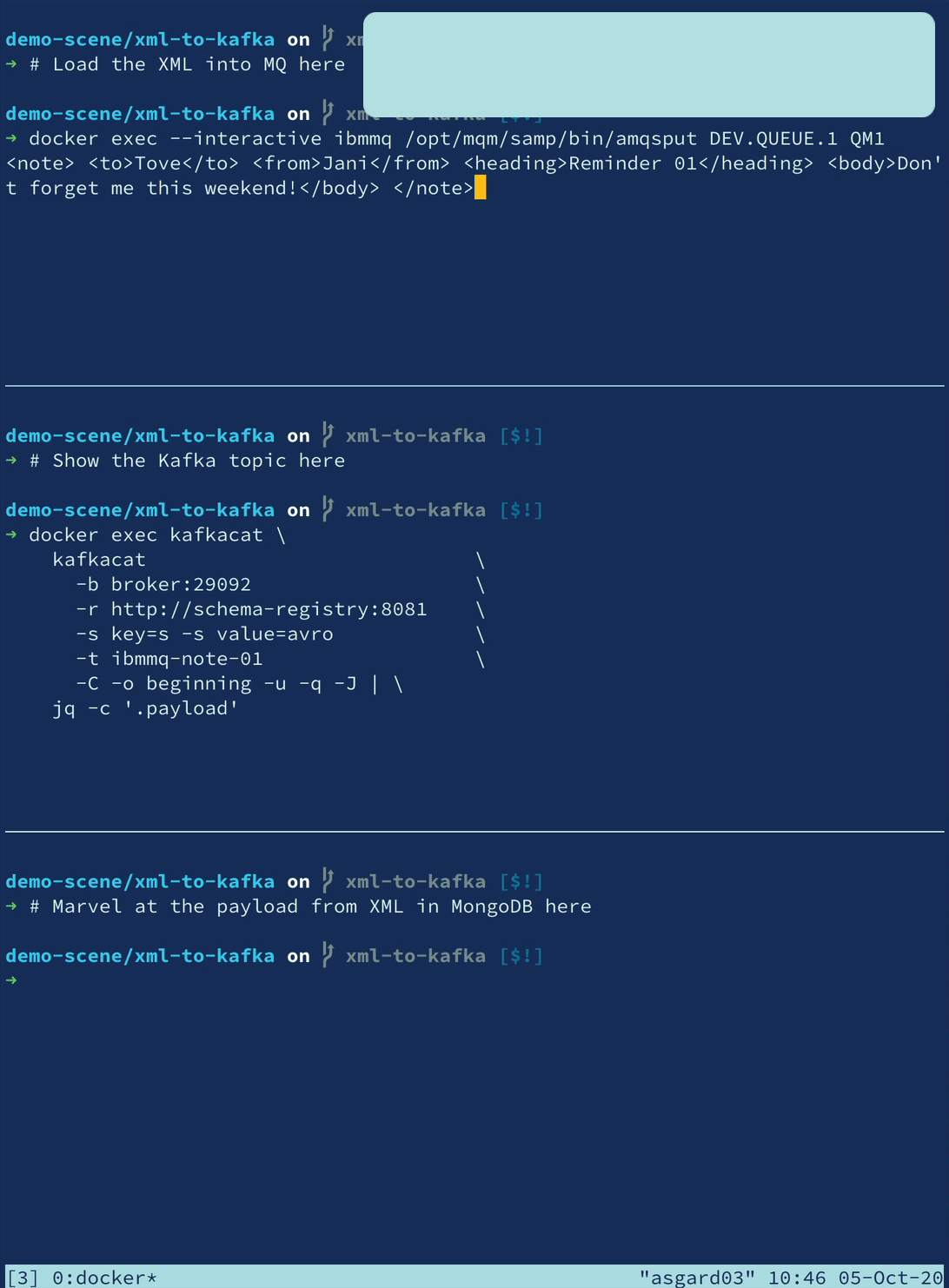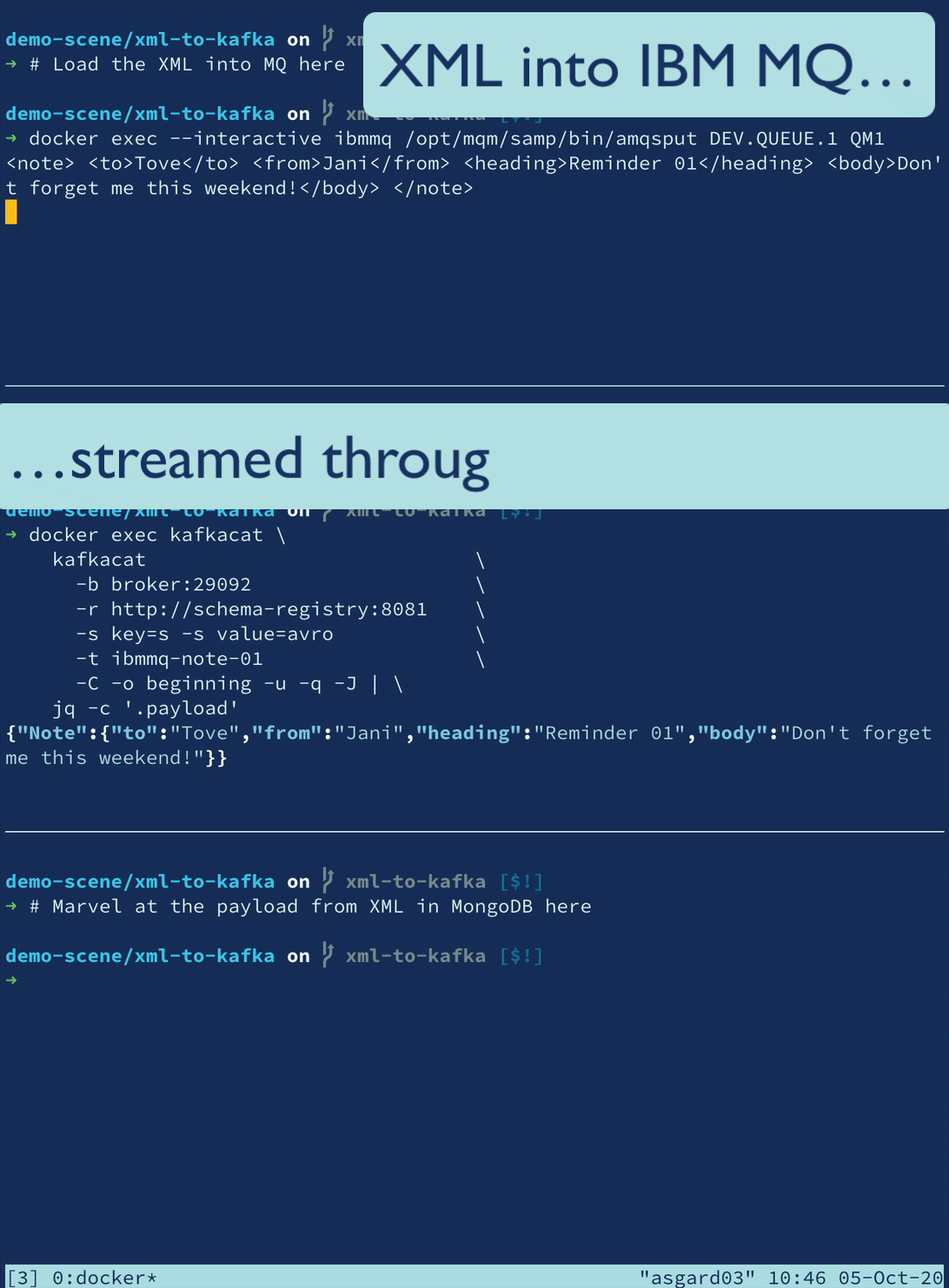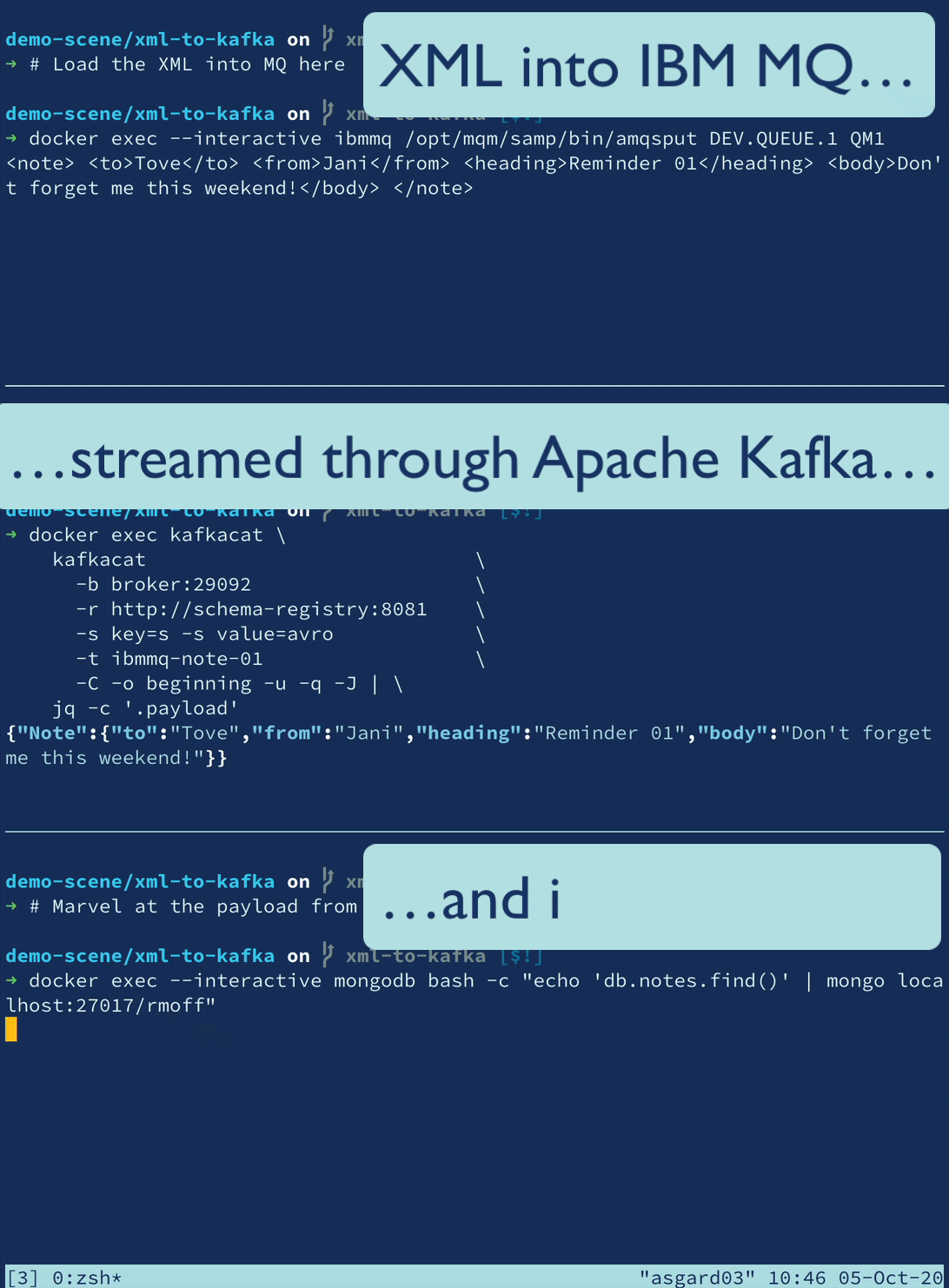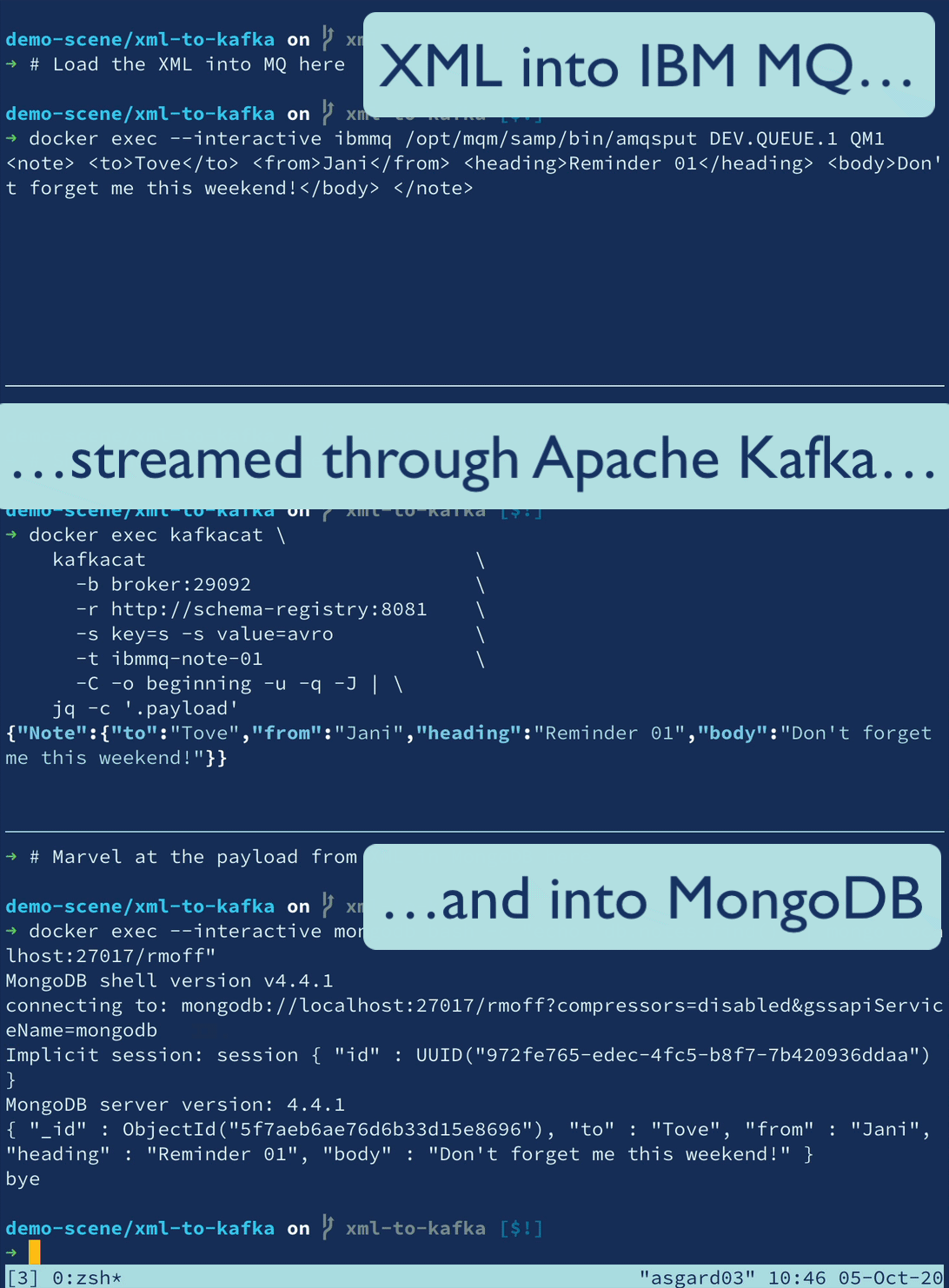 XML
XML
-
 XML
XML
-
XML
-
 11 Sep 2020 What is Kafka Connect?Kafka Connect
11 Sep 2020 What is Kafka Connect?Kafka Connect -
 Kafka Connect
Kafka Connect
-
 17 Jun 2020 Loading CSV data into KafkaKafka Connect
17 Jun 2020 Loading CSV data into KafkaKafka Connect -
 Kafka Connect
Kafka Connect
-
 07 Feb 2020 Primitive Keys in ksqlDBksqlDB
07 Feb 2020 Primitive Keys in ksqlDBksqlDB -
 Kafka Connect
Kafka Connect
-
 22 Jan 2020 Kafka Connect and SchemasKafka Connect
22 Jan 2020 Kafka Connect and SchemasKafka Connect -
 ksqlDB
ksqlDB
-
 Kafka Connect
Kafka Connect
-
 RabbitMQ
RabbitMQ
2019
-
 Kafka
Kafka
-
 18 Dec 2019 Detecting and Analysing SSH Attacks with ksqlDBKafka
18 Dec 2019 Detecting and Analysing SSH Attacks with ksqlDBKafka -
 29 Nov 2019 Kafka Connect - Request timed outKafka Connect
29 Nov 2019 Kafka Connect - Request timed outKafka Connect -
 Kafka Connect
Kafka Connect
-
 Kafka Connect
Kafka Connect
-
 12 Nov 2019 Running Dockerised Kafka Connect worker on GCPKafka Connect
12 Nov 2019 Running Dockerised Kafka Connect worker on GCPKafka Connect -
 Kafka Connect
Kafka Connect
-
 Kafka Connect
Kafka Connect
-
 07 Oct 2019 Kafka Connect and ElasticsearchKafka Connect
07 Oct 2019 Kafka Connect and ElasticsearchKafka Connect -
 15 Aug 2019 Reset Kafka Connect Source Connector OffsetsKafka Connect
15 Aug 2019 Reset Kafka Connect Source Connector OffsetsKafka Connect -
 Kafka Connect
Kafka Connect
-
 09 Aug 2019 Resetting a Consumer Group in KafkaKafka Connect
09 Aug 2019 Resetting a Consumer Group in KafkaKafka Connect -
 23 Jun 2019 Manually delete a connector from Kafka ConnectKafka Connect
23 Jun 2019 Manually delete a connector from Kafka ConnectKafka Connect -
 Kafka Connect
Kafka Connect
-
 Kafka Connect
Kafka Connect
-
 Kafka Connect
Kafka Connect
-
 Kafka Connect
Kafka Connect
-
 02 May 2019 Reading Kafka Connect Offsets via the REST ProxyKafka Connect
02 May 2019 Reading Kafka Connect Offsets via the REST ProxyKafka Connect -
 Kafka Connect
Kafka Connect
2018
-
 docker
docker
-
 03 Dec 2018 Kafka Connect CLI trickskafka connect
03 Dec 2018 Kafka Connect CLI trickskafka connect -
 21 May 2018 Kafka Connect and Oracle data typeskafka connect
21 May 2018 Kafka Connect and Oracle data typeskafka connect -
 mongodb
mongodb
-
 debezium
debezium
-
 06 Mar 2018 Streaming data from Kafka into Elasticsearchkafka connect
06 Mar 2018 Streaming data from Kafka into Elasticsearchkafka connect
2017
-
 goldengate
goldengate
-
06 Sep 2017 Kafka Connect - JsonDeserializer with schemas.enable requires “schema” and “payload” fieldskafka connect
-
 Apache Kafka
Apache Kafka
2016
-
ogg
-
Apache Kafka
-
Kafka Connect
-
Kafka Connect
-
Apache Kafka
-
 19 Jul 2016 Kafka Connect - HDFS with Hive Integration - SchemaProjectorException - Schema version requiredApache Kafka
19 Jul 2016 Kafka Connect - HDFS with Hive Integration - SchemaProjectorException - Schema version requiredApache Kafka