2025
-
 Confluent Cloud
Confluent Cloud
-
 13 Mar 2025 Why is kcat showing the wrong topics?kcat (kafkacat)
13 Mar 2025 Why is kcat showing the wrong topics?kcat (kafkacat)
2021
-
 Data
Data
-
 kcat (kafkacat)
kcat (kafkacat)
-
 02 Feb 2021 Performing a GROUP BY on data in bashData Engineering
02 Feb 2021 Performing a GROUP BY on data in bashData Engineering
2020
-
 XML
XML
-
 jq
jq
-
 08 Sep 2020 Counting the number of messages in a Kafka topickcat (kafkacat)
08 Sep 2020 Counting the number of messages in a Kafka topickcat (kafkacat) -
 kcat (kafkacat)
kcat (kafkacat)
-
 20 Apr 2020 How to install kafkacat on Fedorakcat (kafkacat)
20 Apr 2020 How to install kafkacat on Fedorakcat (kafkacat) -
 Kafka
Kafka
-
 Raspberry pi
Raspberry pi
-
 07 Feb 2020 Primitive Keys in ksqlDBksqlDB
07 Feb 2020 Primitive Keys in ksqlDBksqlDB -
 Kafka Connect
Kafka Connect
-
 ksqlDB
ksqlDB
2019
-
 Kafka Connect
Kafka Connect
-
 Kafka Connect
Kafka Connect
-
 kcat (kafkacat)
kcat (kafkacat)
-
 15 Aug 2019 Reset Kafka Connect Source Connector OffsetsKafka Connect
15 Aug 2019 Reset Kafka Connect Source Connector OffsetsKafka Connect -
 23 Jun 2019 Manually delete a connector from Kafka ConnectKafka Connect
23 Jun 2019 Manually delete a connector from Kafka ConnectKafka Connect -
 Kafka Connect
Kafka Connect
2018
-
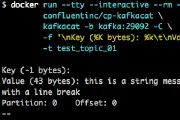 04 Sep 2018 Sending multiline messages to Kafkakcat (kafkacat)
04 Sep 2018 Sending multiline messages to Kafkakcat (kafkacat) -
 Apache Kafka
Apache Kafka