2025
-
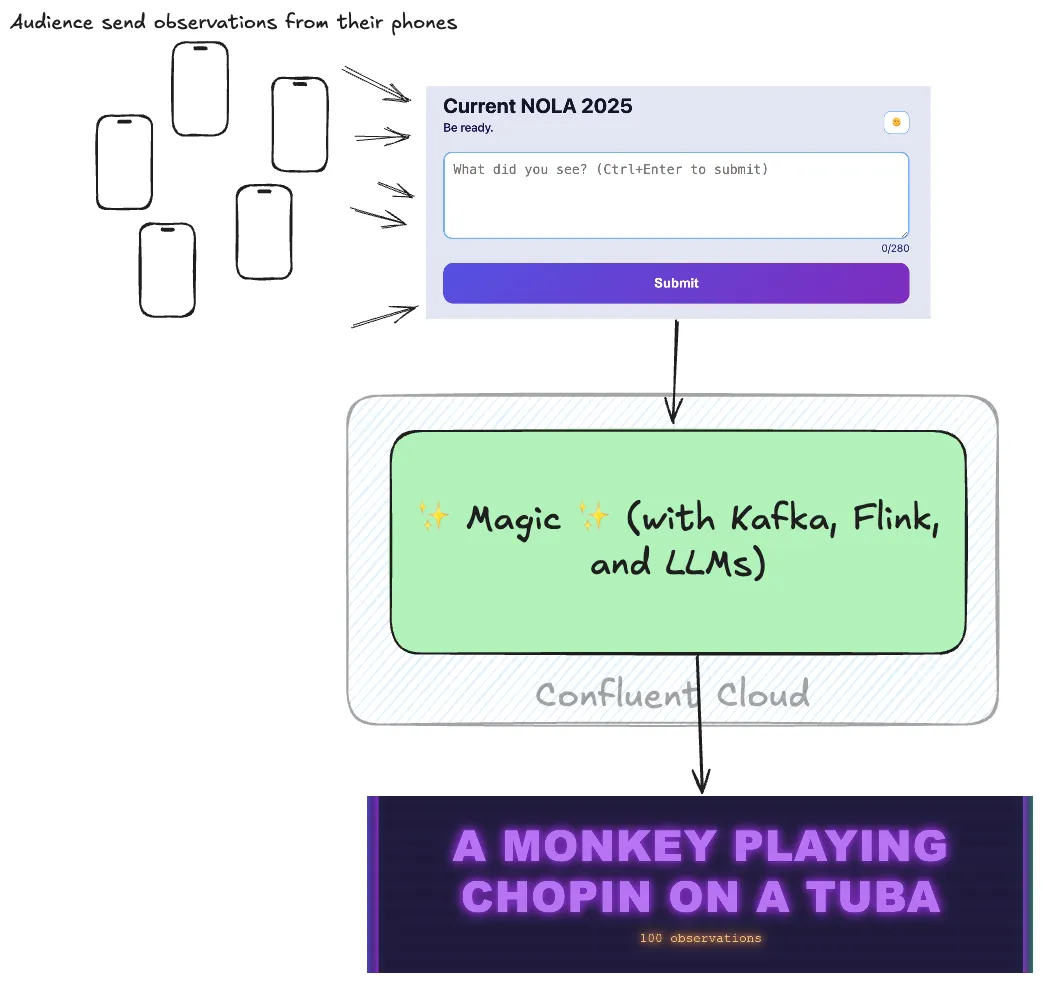 Stumbling into AI
Stumbling into AI
-
 Apache Flink
Apache Flink
-
 Apache Flink
Apache Flink
-
 Confluent Cloud
Confluent Cloud
2021
-
 ksqlDB
ksqlDB
-
 Confluent Cloud
Confluent Cloud
-
 ksqlDB
ksqlDB
-
 Kafka Connect
Kafka Connect
2020
-
 Confluent Cloud
Confluent Cloud
-
 Raspberry pi
Raspberry pi
2019
-
 Kafka Connect
Kafka Connect
-
 12 Nov 2019 Running Dockerised Kafka Connect worker on GCPKafka Connect
12 Nov 2019 Running Dockerised Kafka Connect worker on GCPKafka Connect -
 Kafka Connect
Kafka Connect
-
 kcat (kafkacat)
kcat (kafkacat)
-
 12 Apr 2019 Connecting KSQL to a Secured Schema RegistryksqlDB
12 Apr 2019 Connecting KSQL to a Secured Schema RegistryksqlDB