I’ve recently been playing around with the ELK stack (now officially known as the Elastic stack) collecting data from an IRC channel with Elastic’s Logstash, storing it in Elasticsearch and analysing it with Kibana. But, this isn’t an “ELK” post - this is a Kafka post! ELK is just some example data manipulation tooling that helps demonstrate the principles.
As I wrote about last year, Apache Kafka provides a handy way to build flexible “pipelines”. Today I’m writing up a short real-world example of this in practice. There are three elements to the flexibility that I really want to highlight:
- Decoupling the consumption of data from its production at the previous stage
- Because the consumer is decoupled, being able to stop and start it and have it continue ingesting data from the point at which it previously stopped
- The ability to replay the ingest phase of a pipeline repeatedly into multiple consumers, with no change required to the configuration from source
The simplest form of the pipeline I was using looks like this:
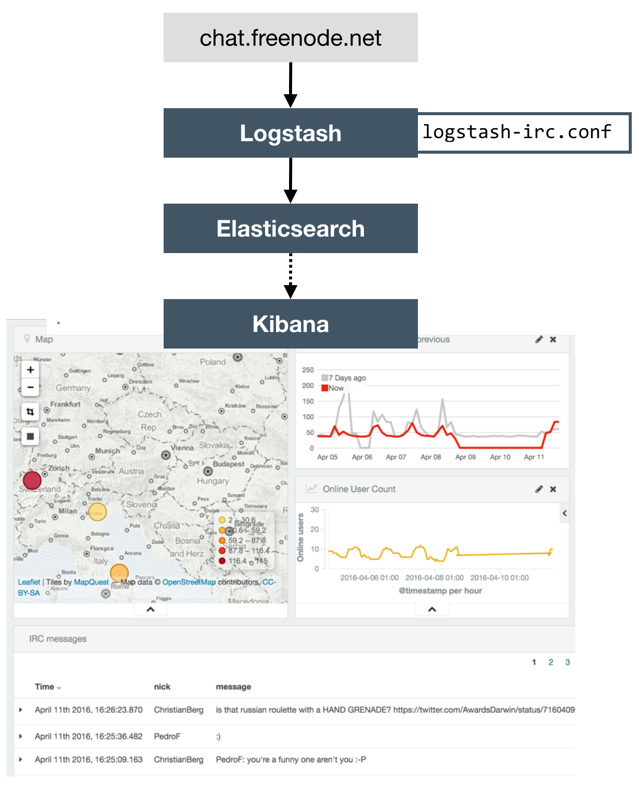
A logstash configuration (logstash-irc.conf) gets Logstash to connect to the IRC server and send messages received to Elasticsearch. From here they can be displayed and analysed within Kibana. Read more about the details here if you’re interested.
From a “pipeline” point of view this is a pretty typical pattern. A tool (Logstash here, but could be ODI, Informatica, etc) runs with a set of “code” (a very simple .conf here, elsewhere it could be mappings and load plans), reading data from a source. Obviously in full-blown system there’s a dozen more moving parts than this simple example, but the point stands.
Let’s think a bit more about what a pipeline does, as this will give us the basis for understanding why and how Kafka fits in so nicely. Overlaying some labels onto the above diagram shows all the processing that we’re doing:
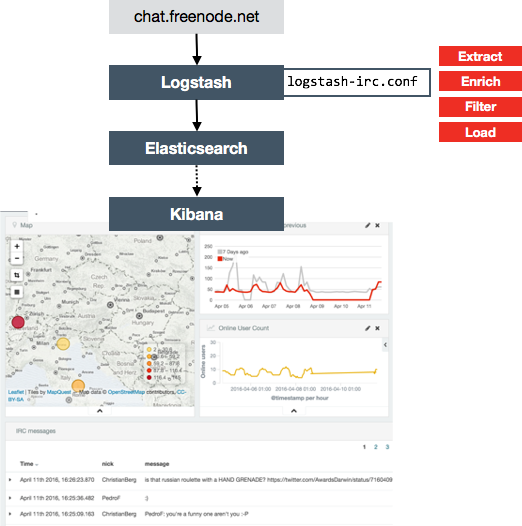
If any of this needs reconfiguring, restarting, or rerunning, it’s an all-or-nothing job. Given that we’re streaming data in near-real-time (or conceptually, designing something that could if needed with minimal-to-no rework), shutting down the pipeline just to change one of these bits is a problem because we’ll lose the data that the source system is spitting out whether we’re there to gather it or not.
Why would we need to change the pipeline configuration? Consider:
- Reconfiguring - Adding in additional enrichment functionality (eg GeoIP lookup), or filtering out duff records, or fixing a bug in the logic, or a dozen other easy examples - in all these cases it’s great if we can reprocess the existing backlog of processed data and then continue processing data as it’s available from the source system.
- Restarting - if the load fails, ideally we don’t want to be hitting the source system again for our data if we’ve extracted it once already. Similarly if the load process needs to be stopped, maybe for maintenance of the target load system, it’s useful to be able to restart the processing exactly from where it left off.
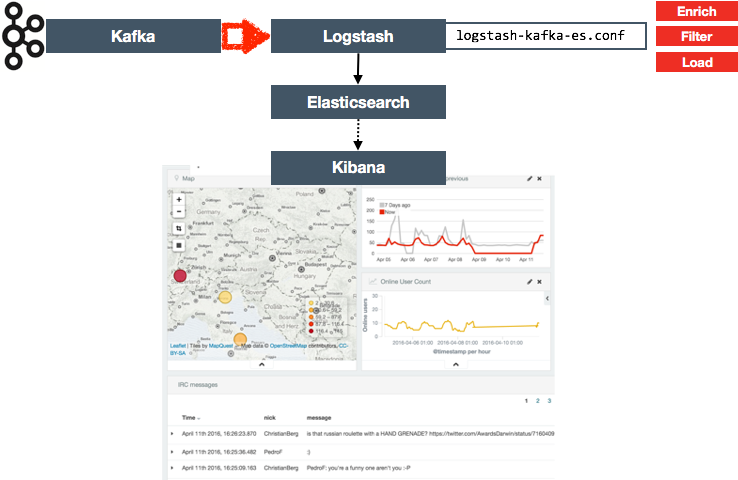
So I decoupled the source extract from any subsequent processing with a very simple Logstash configuration (logstash-irc-kafka.conf) that pulls the data from IRC as before and just sends it straight to Kafka:

The data lands in Kafka, which becomes our ‘staging’ area in effect, taking advantage of Kafka’s “durable buffer” concept. The data extracted is ideally as raw as possible - because we don’t know what subsequent processing we want to do with it, maybe now, or at some future date. Kafka can be configured to retain data based on age or volume - since the data I was working with was low volume I set the topic to retain it for 90 days:
./kafka-topics.sh --zookeeper localhost:2181 --topic irc --alter --config retention.ms=7776000000
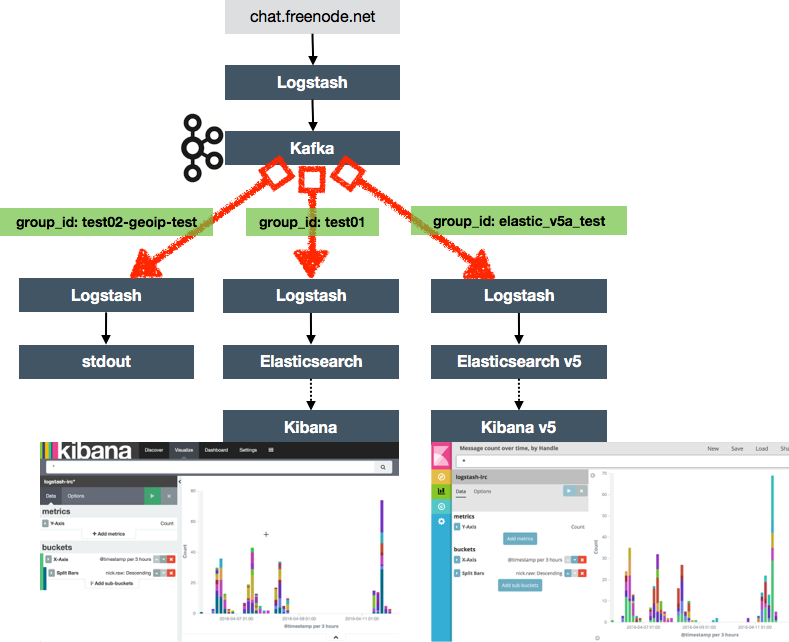
With the data streaming into Kafka and building up there we can then set up one or more consumers of that data. Note that I’m using consumers in the logical sense, not the Kafka “Consumer” specific terminology. My consumer here is Logstash using logstash-kafka-es.conf, which is a variant of the original configuration, this time pulling from Kafka instead of the live IRC feed. And since Kafka is so low-latency, a side-benefit of this setup is that I can both catch up on and replay past records, as well as stream live ones in near-real-time. Result!
At this point I’m where I was before; streaming IRC content in near-real-time to Elasticsearch and analysing it with Kibana. The only difference is that I’ve added in Kafka as a buffer, decoupling the reading messages from IRC with the processing and subsequent storage of them.
Now here’s the money shot – I can add new consumers of this data that’s in Kafka, whenever I want, without needing to know about them at the time that I extracted the source data. I can pick up from the end of the feed, or I can reprocess the whole lot, per consumer. I’ve used this in a couple of instances recently:
- Add and refine a GeoIP lookup step to the Logstash processing (see example config), without affecting the existing Logstash->Elasticsearch->Kibana flow
- Testing the Elastic stack v5 alpha release by processing the same source data again but with a different version of the downstream tools, enabling a proper like-for-like comparison of the pipeline. This is similar in concept to an idea that Gwen Shapira wrote about in an article in 2015.
In both of these cases the existing original consumer remains running and untouched. This kind of concurrent running is a great way to work with a single feed from the source system, keep the data pipeline running for subsequent analytics, whilst also developing and validating new functionality.
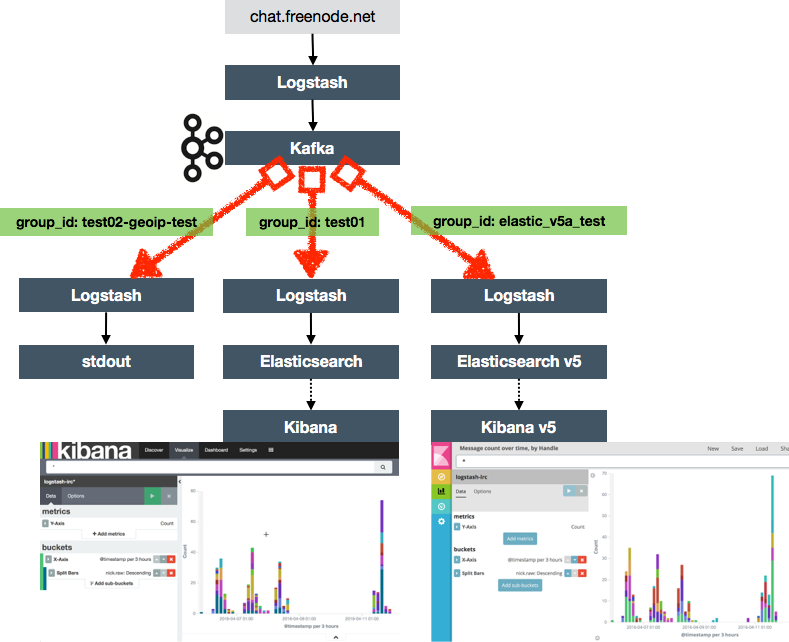
Consumer Groups and Offsets 🔗
One of the key concepts in all of this is that of the Kafka consumer group, which is a unique identifier for a given consumer (or group of consumers for the same logical entity if you want to parallelise the consumption). In Kafka 0.8 Zookeeper is used by default to keep track off the offset of the last record that a given consumer group received. So in my development environment I can look on my Kafka server at Zookeeper and see for each consumer group the latest offset: (reference)
$ bin/kafka-run-class.sh kafka.tools.ExportZkOffsets --zkconnect localhost:2181 --output-file >(cat)
/consumers/console-consumer-32467/offsets/irc/0:4145
/consumers/kafka-ubuntu03/offsets/irc/0:1035
/consumers/logstash/offsets/irc/0:4145
/consumers/logstash-5-testing/offsets/irc/0:4143
A brief note on the command above - I’m using bash process substitution to send the output to stdout (via cat) instead of the asked-for output file.
From the above output you can see that there are four consumer groups. Two are at the same offset (4145) which happens to be the latest, and therefore have consumed all the available messages. A third (logstash-5-testing) is almost caught up (4143, vs 4145), and the final one (kafka-ubuntu03) is way behind at 1035. By running the command periodically you can see if a consumer is actually reading records, or just offline (or maybe stuck).
To see more information about a given consumer, including the lag (current vs maximum offset) use ConsumerOffsetChecker and specify the consumer group:
$ bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper localhost:2181 --group logstash-5-testing
Group Topic Pid Offset logSize Lag Owner
logstash-5-testing irc 0 4143 4148 5 none
Summary 🔗
Building a successful data pipeline requires that it is flexible to changing requirements, as well as unknown future ones. This is as true for little local PoCs such as this one as it is for large-scale implementations. The pipeline needs to be able to have minimal impact on source systems whilst being able to satisfy multiple destinations, some or all of which may want to batch process instead of stream the data. In addition, being able to re-stream the raw data repeatedly and on-demand into adhoc applications without affecting the primary ‘productionised’ consumers is a powerful enabler of the ‘data discovery lab’ concept, which I write about in more detail here.
Kafka enables the above, summarised in the following benefits:
-
Stream or batch the data from source once, consume by multiple hetrogenous applications many times.
-
Offset tracking distinct for each consuming application
-
Processing can be re-run, which is useful for:
- Development process - iterative improvements / bug fixing against the same streamed data set
- Production data - data discovery/advanced analytics
You can read more about this in detail over here.