Food Pr0n 02 - Devon & Dorset
On a family holiday in South Devon last week I had some good food experiences. Top of the pile was a Lardy Cake, a delicacy new to me but which I’ll be sure to be searching out again. It …

On a family holiday in South Devon last week I had some good food experiences. Top of the pile was a Lardy Cake, a delicacy new to me but which I’ll be sure to be searching out again. It …

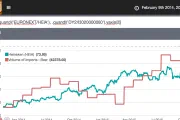

 OBIEE
OBIEE
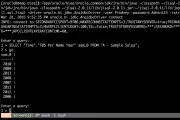
 logstash
logstash
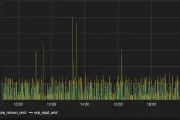

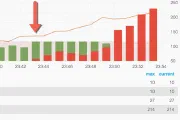
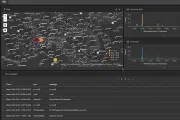
 Monitoring
Monitoring

 OBIEE
OBIEE
 OBIEE
OBIEE
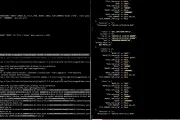
 Apache Kafka
Apache Kafka
 OBIEE
Apache Kafka
OBIEE
Apache Kafka
 OBIEE
OBIEE
 OBIEE
OBIEE
 OBIEE
OBIEE
 Elasticsearch
Elasticsearch
 Elasticsearch
OBIEE
OBIEE
Elasticsearch
Elasticsearch
Linux
Linux
OBIEE
OBIEE
Elasticsearch
Elasticsearch
Linux
Elasticsearch
OBIEE
Monitoring
Elasticsearch
OBIEE
OBIEE
Elasticsearch
Elasticsearch
Linux
Linux
OBIEE
OBIEE
Elasticsearch
Elasticsearch
Linux
Elasticsearch
OBIEE
Monitoring