
If you’ve ever been to a conference, particularly as a speaker whose submitted a paper that may or may not have been accepted, you might wonder quite how conferences choose the talks that get accepted.
I had the privilege of chairing the program committee for Current and Kafka Summit this year and curating the final program for both. Here’s a glimpse behind the curtains of how we built the program for Current 2022. It was originally posted as a thread on Twitter.
For a conference about data, you’d rightly expect that we use data when evaluating sessions and building the program for Kafka Summit and Current 2022. It starts with the 31 person program committee reviewing all the submissions to the Call for Speakers in a tool called Sessionize which uses the Elo rating system for its magic.
The output from the session reviews is a single score for each talk, which along with a ton of metadata gets loaded into Airtable. The review score then forms the basis for the first pass of building the program. Some talks are obviously great … whilst others are obviously not
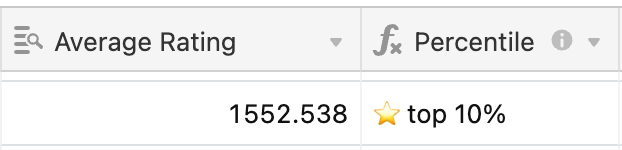
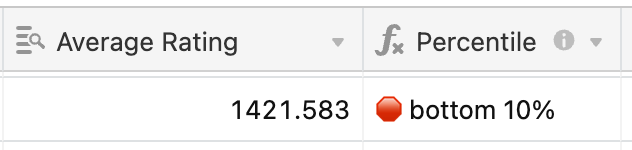
This is just the beginning of the process. If we built a program on abstract score alone it probably wouldn’t be a very balanced program. There are many more factors to take into account.

One of the things that the program committee does to help counteract the somewhat blunt "Average Rating" is provide comments for many of the submissions, which provides extra colour and context for the rating:
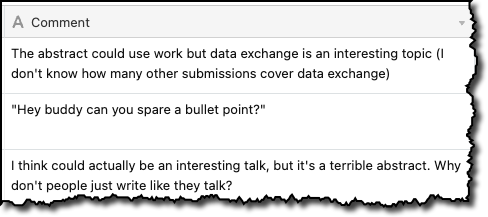
You can read an analysis of some of the patterns I saw in the comments in another article I wrote recently.
Another bit of data that I thought would be interesting to compare was the speaker ratings for the previous Kafka Summit with the abstract ratings for the same sessions. How correlated is the abstract rating with the resulting talk delivery?
First up, a huge caveat. Speaker rating data is definitely sketchy at best. For Kafka Summit it’s collected through an app (that not everyone will have installed), not everyone leaves a rating, probably people who feel most strongly will take the time to leave a rating…
…and that’s before you take into account the fact that a single number can’t convey the full gamut of opinions a person may have (the same goes for abstract scores, BTW). Perhaps you couldn’t hear the speaker and rate them down because of it (even though that’s the AV’s fault). Maybe the slides were crap but delivery great, or the delivery great but the content poor. Or maybe you had a sore head from the party the night before, or it’s nearly lunchtime and you’re impatient for the session to finish.
All these reasons and more contribute to the speaker score being a pretty crude measure. But a measure it is nonetheless, so let’s take a look at it. For Kafka Summit London the very best-rated sessions (top 10%) were all good picks based on the abstract score too

So does a top-rated abstract mean that you’re going to get an excellent talk? Well, no, no it doesn’t. Even excusing a few outliers and data burps, it’s pretty clear that a great abstract is no guarantee of a great talk.

What about if we invert this? Are there bad abstracts that end up being great talks? Well, the data here is already biased for what are—hopefully—going to be good talks (because why would you build a conference program from abstracts that were crap?).
Of the six abstracts with review scores below the median, three tanked (speaker score in bottom quartile or even bottom 10%) – but one beat the median speaker score and two were in the top quartile!
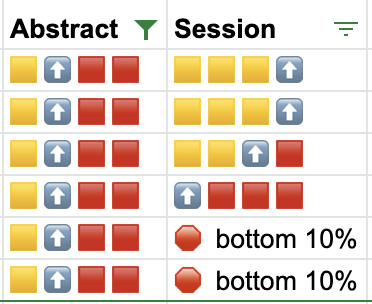
What conclusions are there to draw from this? Firstly, the abstract isn’t everything. But does that mean you can put in a crap abstract and expect to be accepted because it might turn out to be a 💎diamond in the rough? NO! 🙊 Per the above data, the really bad abstracts (bottom quartile) just don’t get accepted. Period🛑
Make sure you put your best work into a good abstract because it gives you the best fighting chance. This blog and this one gives you some advice, as does this podcast.
If we don’t pick abstracts based on score alone, then what else factors into that? The screenshot earlier in the thread gives you some clues. For example, is the subject relevant to the audience at the conference? Is there a good representation of different technologies?
Make sure you come along to Current 2022 to see what you make of the program that we’ve got for you —tickets are on sale now.
(oh, and do all the speakers and future program committee a favour and always leave session ratings for any conference you’re at if you can 😁)