2026
-
 19 Feb 2026 Ten years late to the dbt party (DuckDB edition)dbt
19 Feb 2026 Ten years late to the dbt party (DuckDB edition)dbt
2025
-
 02 Jun 2025 Digging into DucklakeDuckDB
02 Jun 2025 Digging into DucklakeDuckDB -
 20 Mar 2025 Building a data pipeline with DuckDBDuckDB
20 Mar 2025 Building a data pipeline with DuckDBDuckDB -
 19 Mar 2025 Exporting Notebooks from DuckDB UIDuckDB
19 Mar 2025 Exporting Notebooks from DuckDB UIDuckDB -
 14 Mar 2025 Kicking the tyres on the new DuckDB UIDuckDB
14 Mar 2025 Kicking the tyres on the new DuckDB UIDuckDB -
 DuckDB
DuckDB
-
 DuckDB
DuckDB
2024
-
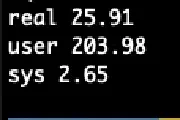 03 Jan 2024 1️⃣🐝🏎️🦆 (1BRC in SQL with DuckDB)DuckDB
03 Jan 2024 1️⃣🐝🏎️🦆 (1BRC in SQL with DuckDB)DuckDB
2023
-
 14 Mar 2023 Quickly Convert CSV to Parquet with DuckDBDuckDB
14 Mar 2023 Quickly Convert CSV to Parquet with DuckDBDuckDB -
 03 Mar 2023 Aligning mismatched Parquet schemas in DuckDBDuckDB
03 Mar 2023 Aligning mismatched Parquet schemas in DuckDBDuckDB
2022
-
 dbt
dbt
-
 Data Engineering
Data Engineering
-
 DuckDB
DuckDB