
After cobbling together my own eval for Claude, I was interested to discover harbor. It’s described as:
A framework for evaluating and optimizing agents and models in container environments.
Which sounds kinda cool, right?
It ships with a bunch of pre-created tests and benchmarks, such as the mandatory hello-world to more complex and multi-task examples such as terminal-bench.
Harbor’s unit of execution is a task, which is basically a prompt for a coding agent (such as Claude Code). Harbor works with multiple coding agents, and multiple models. Which is basically what it says on the tin above, right?
Here’s an example task:
Create a file called hello.txt with "Hello, world!" as the content.Trying it out 🔗
Let’s try out hello-world:
harbor run --model anthropic/claude-sonnet-4-6 \ (1)
--agent claude-code \ (2)
--dataset hello-world \ (3)| 1 | Use Sonnet 4.6 model |
| 2 | Run the test using Claude Code |
| 3 | Run the pre-packaged "Hello, World" test |
After a short time this completes:
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Metric ┃ Value ┃
┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ Agent │ claude-code (claude-sonnet-4-6) │
│ Dataset │ hello-world │
│ Trials │ 1 │
│ Errors │ 0 │
│ │ │
│ Mean │ 1.000 │
│ │ │
│ Reward Distribution │ │
│ reward = 1.0 │ 1 │
└─────────────────────┴─────────────────────────────────┘Harbor ships (see what I did there? 😉) with a nice dashboard for exploring test runs.
Spin it up by pointing it at the output folder (jobs, in this case):
harbor view jobsStatus and timing breakdown:
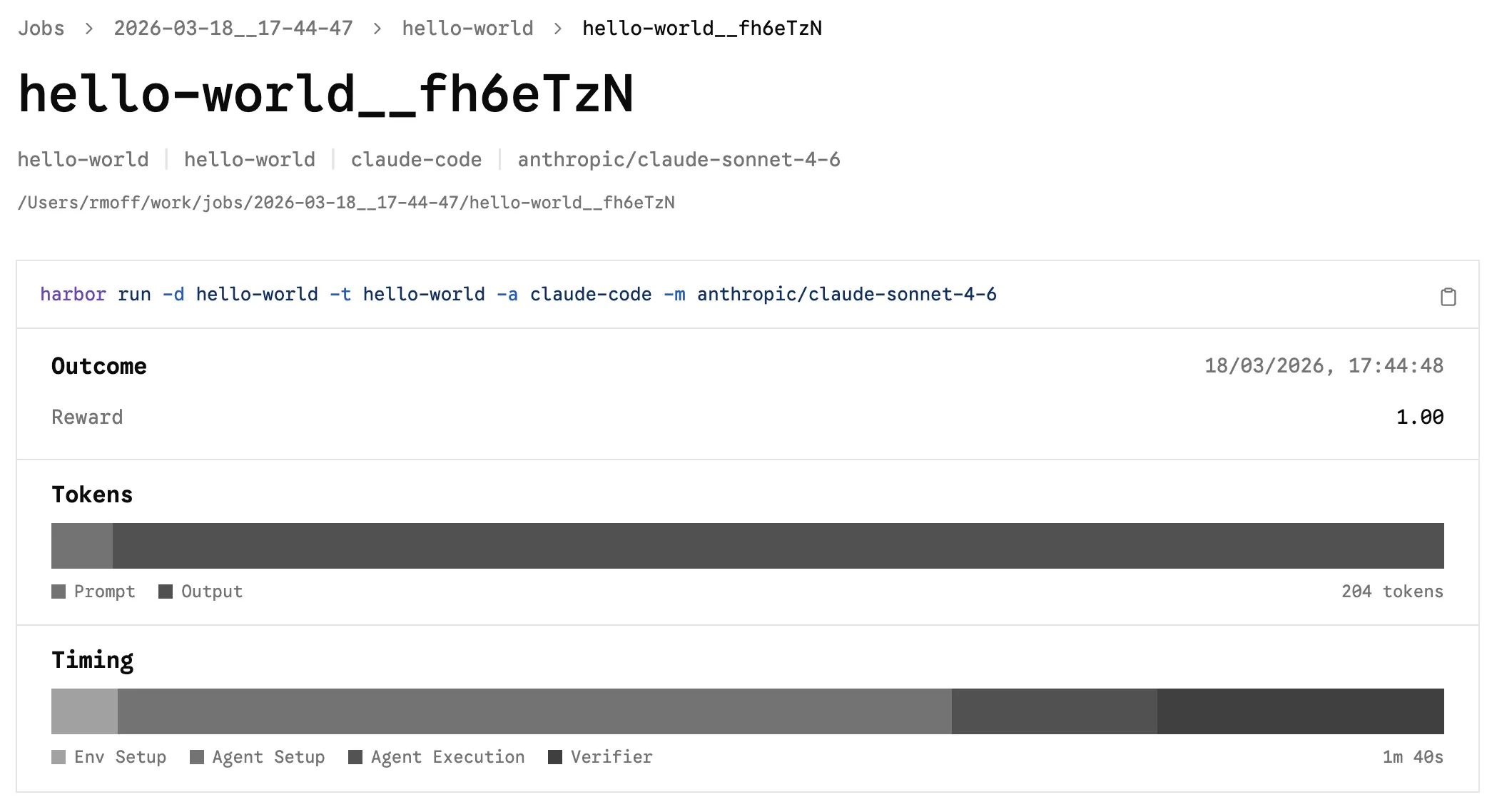
Under the covers, Harbor spins up a Docker container, within which Claude runs with --dangerously-skip-permissions so that it can go about its business without any of that pesky permission seeking.
It takes the defined task or dataset prompt, and runs it, as we can see here:
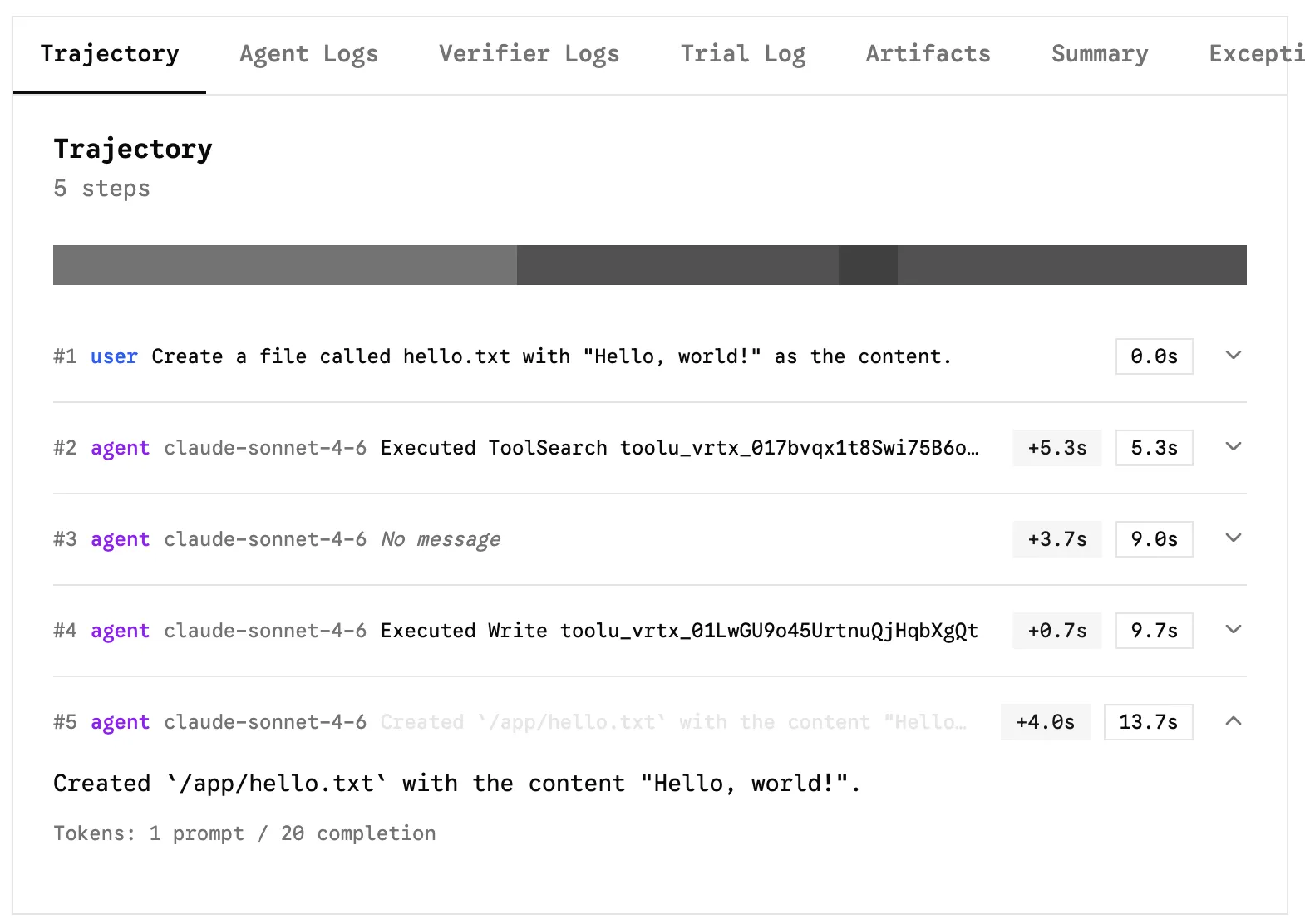
Scoring 🔗
A task’s performance is scored using a verifier that’s part of the task definition. For the above "hello world", all we need to do is check if the agent (a) created the file with the correct name and (b) with the correct content. Which is exactly what this Python script does:
def test_hello_file_exists():
hello_path = Path("/app/hello.txt")
assert hello_path.exists(), f"File {hello_path} does not exist"
def test_hello_file_contents():
hello_path = Path("/app/hello.txt")
content = hello_path.read_text().strip()
expected_content = "Hello, world!"
assert content == expected_content, (
f"File content is '{content}', expected '{expected_content}'"
)Its wrapper script gives it a pass/fail score—either it worked, or it didn’t:
if [ $? -eq 0 ]; then
echo 1 > /logs/verifier/reward.txt
else
echo 0 > /logs/verifier/reward.txt
fiIf you run the test multiple times, you’ll get scores (rewards); unsurprisingly "hello-world" doesn’t pose any challenges or show variability:
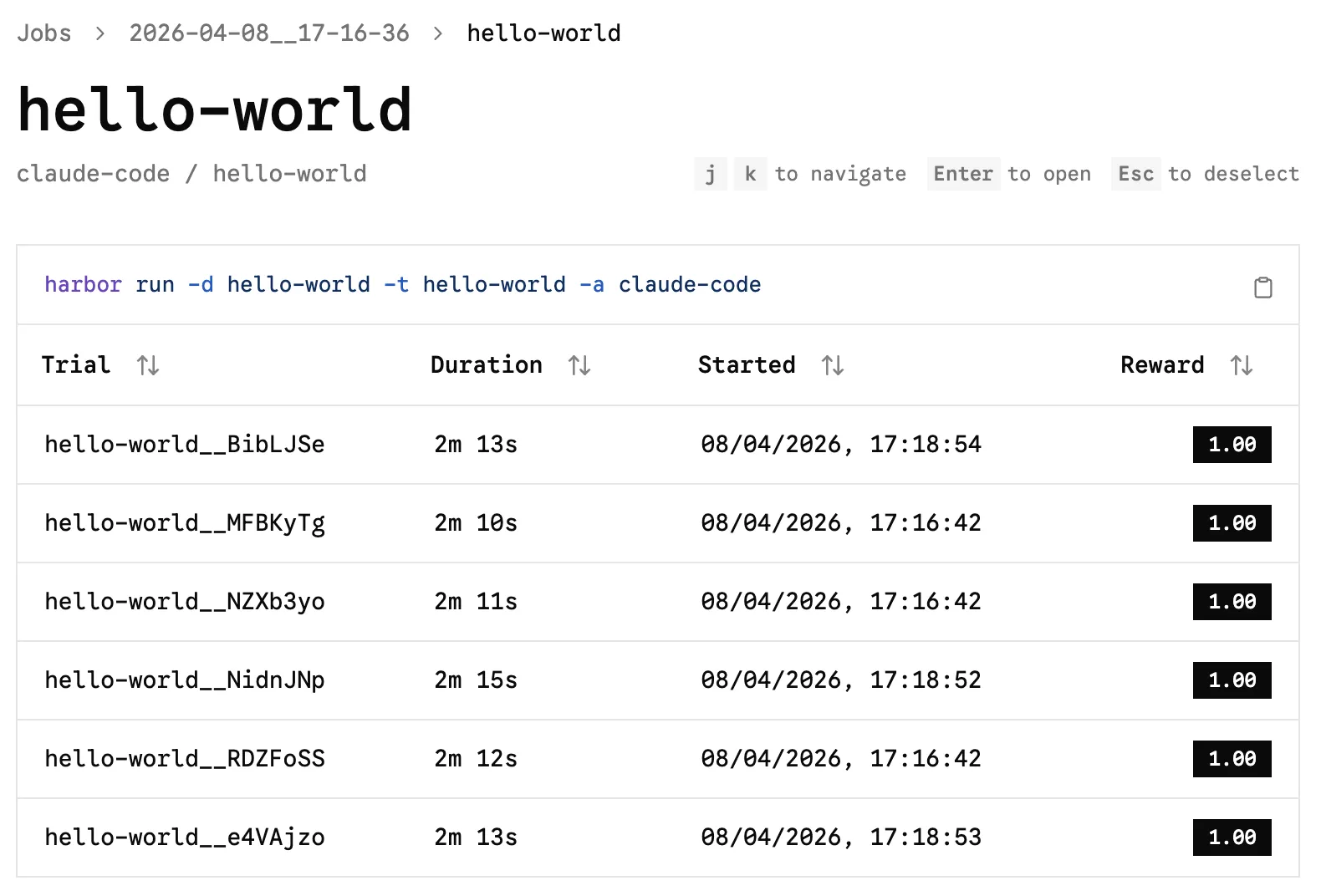
So that’s Hello World…what about the Real World?
Using it with dbt 🔗
The driver to looking at Harbor was my curiosity as to whether I could have used Harbor in place of my hacky homebrew bespoke and artisanal scripts, and if so what it would look like.
|
There is an imbalance here in that I now know more about evals, deterministic testing and LLM-as-judge than I did before creating my custom harness. If I were to write it again, it’d be a lot cleaner I’m sure. So almost by definition, something like Harbor is probably going to be better. |
As you’d expect by now, I didn’t write the dbt task myself; I told Claude about my previous work, and had it build a Harbor-compliant task. Its key components are this:
| Component | Description |
|---|---|
|
Installs |
|
The same prompt as before
|
|
Verifier script, which does several things:
|
|
Script to call out to LLM to judge the work, using the rubric provided (similar to the one used before) |
There are plenty of gaps in this, such as only using the non-deterministic score. The final Harbor reward value should probably be a weighted version of the deterministic and non-deterministic verification. However, this was more about understanding the scope of Harbor than building the perfect test.
With this in place I could then run my test:
harbor run \
--agent claude-code \
--model "claude-sonnet-4-6" \
--path "tasks/f-rich-with-plugin" \ (1)
--artifact /app \ (2)
--n-attempts 3 (3)| 1 | Custom task definition |
| 2 | Capture the output of the agent as an artifact (i.e. don’t throw it away once the test finishes) |
| 3 | Run the same task multiple times |
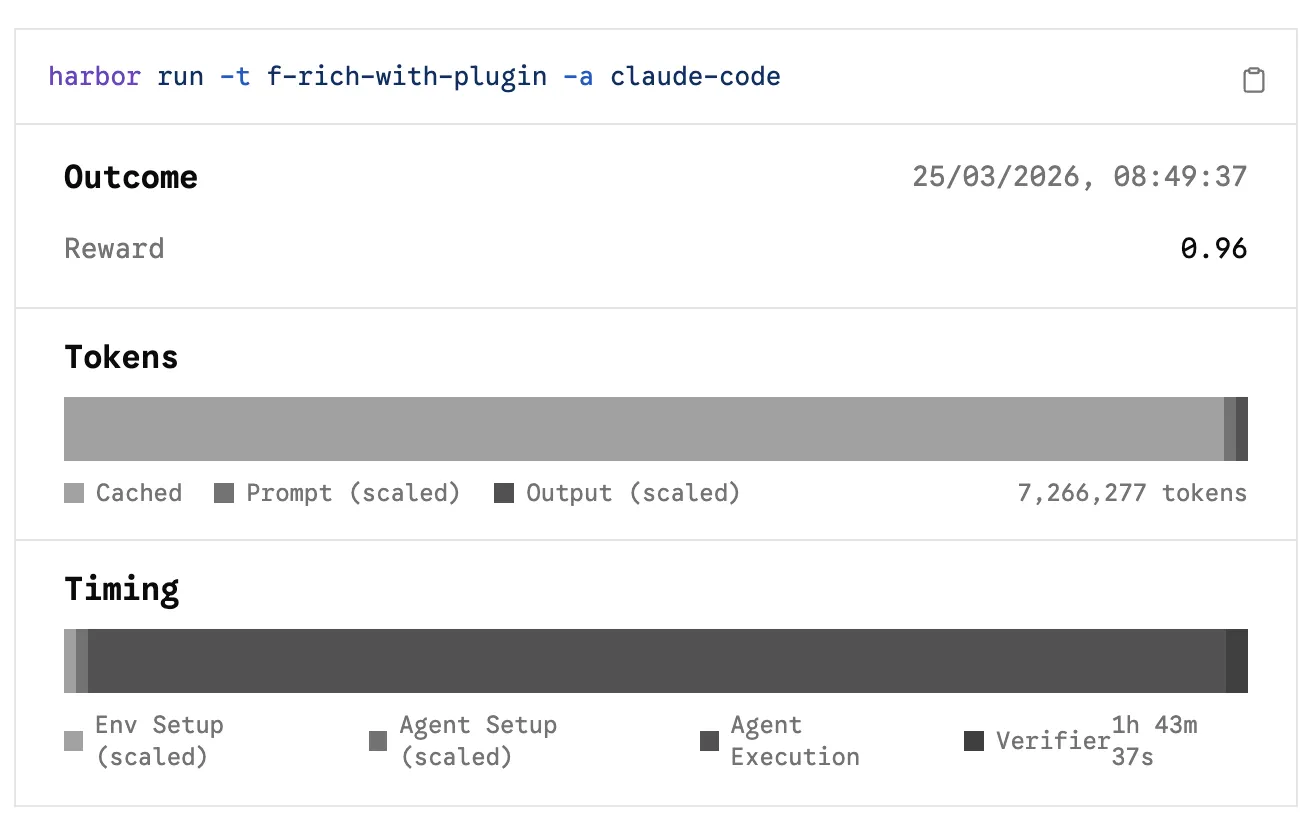
and see how multiple iterations of the same prompt and model scored, and the variance between them:
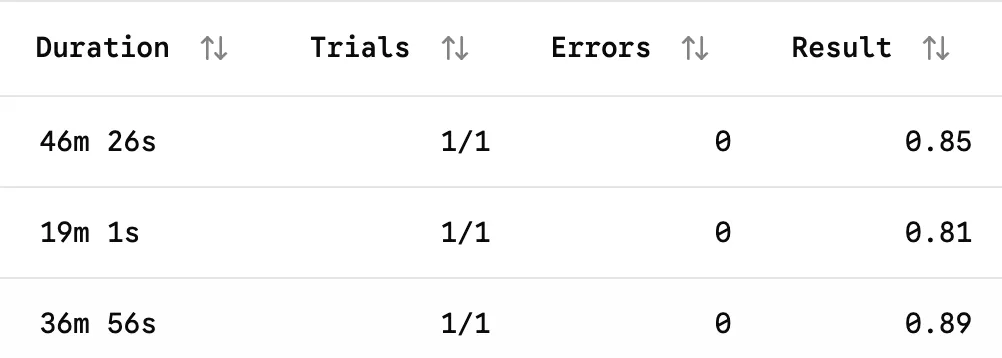
I still Harbor some doubt… 🔗
(…and not just about the scope for so many awful puns)
I think Harbor would be extremely useful for tightly defined tasks against which one wanted to evaluate new models or agentic coding tools (for example, alternatives to Claude Code). In fact, it’s perfect for that, and it’s literally what it’s designed for.
Where I’m not going to be rushing to use it though is for evaluating the effectiveness of different prompts or skills, particularly as I flail around trying all the things and randomly changing lots of stuff.
A lot of that is down to my inexperience in this area; Harbor adds a layer of complexity, and I’m almost certain my random jiggling to unbreak things would often break my Harbor test rig (or invalidate the integrity of the test results).
For example; to vary the prompt (the task’s instruction.md) means building another task (if I understand Harbor correctly), which then means duplicating the verifier.
Once that’s duplicated, it has the scope to get out of sync across tasks.
Maybe there’s a way to align it (symlinks, perhaps - but I’d need to test it, and that’s more tooling work), but maybe Harbor’s not really designed to be used in this way.
Anyway - an interesting tool, and definitely one to keep in mind as I continue to explore this bamboozling world of agents and AI :)