
I’ve had a huge amount of fun this month exploring quite what AI (in the form of Claude Code) can do for a data engineer. Rather than just hack around at a prompt, I took a bit more of a considered approach to it, building a harness to test out different prompts and skills. You can read my write-up here, the headline of which is that literally Claude Code isn’t going to replace data engineers (yet).
I’ve also written up an AI Disclosure for my blog which I’ll keep up to date as my use of AI evolves, along with a sweary rant about why you basically have to get on board with AI if you value your career.
|
Kafka and Event Streaming 🔗
-
🔥 A fascinating deep-dive from the Apache Iggy team looking at their migration journey to thread-per-core architecture powered by io_uring.
-
Simone Esposito at Bitrock looks at the new Queues for Kafka feature that was released recently.
-
"Unknown magic byte" is an error that has sent many a Kafka user running for the comforting (if unsuitable) embrace of plain JSON for their message serialisation, but no longer! David Araujo describes how schema IDs can now be stored in the header of a Kafka message - this is huge.
-
An interesting thread on Reddit looking at how to give external partners access to Kafka topics without direct broker access.
-
I’ve mentioned Tansu before, and here’s another write-up of it, covering a talk by its author at QCon London 2026.
Stream Processing 🔗
-
🔥 Feldera’s Mihai Budiu explains Why incremental aggregates are difficult.
-
🔥 My colleague Gustavo de Morais has shared his slides from Flink Forward 2025: The Big State Monster: Taming State Size in Multi-Way Joins with FLIP-516.
-
A nice step-by-step guide from the Apache Gravitino project showing how to use Gravitino with Apache Flink.
-
The recording of LinkedIn’s Stream Processing meetup (February 2026) is now available with three good talks:
-
A very nice tool from Tom Cooper for tracking KIPs and FLIPs: OSSIP.
-
My colleague Florian Eiden has published flink-unittest, a Python unit testing framework for Flink SQL.
-
Gordon Murray built a Flink Connector for Apache Iggy.
-
Zalando’s Maryna Kryvko looks at the impact of joins using the Table API on Flink’s state store in 1.20, and optimisations that they made to reduce it by 75%. They rightly note that improvements are already available in Flink 2.1.
Analytics 🔗
-
Reddit’s Neven Miculinic describes how they built their logging platform around Clickhouse and Kafka.
-
DuckDB 1.5.1 includes support for Lance lakehouse format, improvements to Iceberg v3 support, and more.
-
Autotrader’s Tom Armitage has a very cool article looking at data visualisation and how one goes about splitting the UK into ten perfectly balanced regions.
-
🔥 My colleague Elijah Meeks (who did all the cool animations on Flink Watermarks…WTF) has a dataviz library which he rewrote to be streaming-first. You can find the Semiotic repo here and lots of very pretty examples on the main site.
-
Kartik Khare from StarTree has a good two part series looking at real-time ingestion in Apache Pinot (part 1, part 2).
-
Prithwish Nath took a look at how far you can push DuckDB on Commodity Hardware, whilst Gábor Szárnyas tried out DuckDB on the new MacBook Neo.
Data Platforms, Architectures, and Modelling 🔗
-
Swiggy’s Sundaram Dubey looks at the demand for real-time dashboards at Swiggy, and how they implemented it.
-
A good primer from Milan Mosny on Ontology, Taxonomy, Data Model, Context Graph & Friends.
-
A recording of Anurag Kale’s QCon talk about their experience with Data Mesh.
-
🔥 Chris Hillman has a great post here Your Data Model Isn’t Broken, Part I: Why Refactoring Beats Rebuilding.
-
Yoshnee Raveendran from Spotify explains how they generate "Spotify Wrapped" for each user.
-
🔥 Nice write up from Edijs Drezovs and team describing in good detail the lakehouse that Yggdrasil Gaming built.
-
🔥 Joe Reis' Practical Data Modeling book is nearing completion, and you can access significant chunks of the early chapters already on his Substack.
-
A VLDB paper from 2021 by Google’s Pavan Edara and Mosha Pasumansky describing BigQuery’s metadata management system and how it supports performance at scale.
-
Tim Castillo has a good piece discussing the three layers in which business logic lives (AI context, semantic, and dimensional model): Analytics Engineering’s Unfinished Work.
Data Engineering, Pipelines, and CDC 🔗
-
Confluent have just launched their dbt adapter for Confluent Cloud Flink SQL (it also works with Apache Flink too via this gateway).
-
🔥 I dug into what Claude Code could do with dbt and concluded that Claude Code isn’t going to replace data engineers (yet).
-
Following on from my baby-steps above, here’s a thorough examination from Mark Rittman of what it looks like when you actually put LLMs to work alongside you.
-
Goldsky’s Jeff Ling has details of how they got a 12x improvement by reading data directly from Clickhouse as Arrow instead of Kafka (Warpstream) with Avro.
-
Chris Gambill puts into clear words what anyone my age has also been thinking: Medallion Architecture Isn’t As New As You Think. I took a similar run at it previously, looking at how Oracle’s Big Data (lol, this was 2016, ok) reference architecture compared to it too.
-
Hila Turi from Riskified has a fascinating article about their 1 billion row table in Snowflake for 3rd-parties, and how they handled the data modelling, cost, and retroactive changes.
-
A set of three excellent, hands-on, posts about building really high-quality data pipelines:
-
🔥 The nitty-gritty of actual data engineering isn’t in the fancy dashboard for the stakeholders, but making sure that you’re actually processing all the data and not losing any. Robert Sahlin has a great article all about monitoring for silent data loss.
-
🔥 As well as guarding against data loss, a data engineer also needs to have a clear picture of the performance of their estate, which Rodrigo Molina describes in this practical article looking at Measuring Latency in Data Platforms.
-
🔥 Good stuff from Jeremy Chia and Justina Šakalytė at Vinted looking at how they handle data quality issues without stalling their pipelines. Also available as a recording.
-
-
A practical primer from Ben Rogojan (a.k.a. SeattleDataGuy) on Full Refresh vs Incremental Pipelines.
-
Joe Reis mulls over the state of the data engineering job market.
-
Dan Beach has a list of Data Engineering Blogs to Follow that’s very good. But then I would say that, cos I’m on it ;)
-
Phi Vu Trinh has an excellent writeup of a VLDB paper from engineers at YouTube describing how they do CI/CD for data pipelines.
Open Table Formats (OTF), Catalogs, Lakehouses etc. 🔗
-
Details of pg_duckpipe, which streams Postgres tables into DuckLake.
-
Grigorii Osipov considers whether DuckLake can fix the Lakehouse.
-
A good article from Reetika Agrawal looking at Iceberg Branches and Tags with Presto.
-
If you need to read and write across table formats (Iceberg/Delta/Hudi) then you’ll be interested in this article from Junaid Effendi in which he explains how Delta UniForm works.
-
🔥 My colleague Gunnar Morling has released v1.0 of Hardwood: A New Parser for Apache Parquet. Much as we all love shovelling a ton of Hadoop dependencies every time we want to use Parquet, something tells me that this approach might be a better one :D
-
🔥 Some lovely Iceberg deep-dive detail and performance analysis from Chris Douglas part 1 / part 2.
-
I wrote previously about alternatives to the now-abandoned MinIO project. One of my favourite replacements is SeaweedFS, which now supports Amazon S3 Table so you can write Iceberg tables directly to it.
-
Andrew Lamb’s recent talk, "Column Storage for the AI Era", looked at the proliferation of column storage formats and what is driving it recording / slides.
RDBMS 🔗
-
🔥 Elizabeth Christensen (a.k.a. SQLLIZ) recently published a whole day’s worth of free Postgres training material.
-
A summary from InfoQ’s Leela Kumili of Uber’s work improving their MySQL Cluster uptime with consensus replication.
-
🔥 A nice troubleshooting diagnostics story from Anthonin Bonnefoy at DataDog about Postgres upserts that don’t update but still write and the problems this can cause at scale.
-
Staying with DataDog, they recently made available a free online explain plan visualizer, which Tanel Poder put through its paces with Oracle execution plans.
-
🔥 I love this post from Nile’s Jan Nidzwetzki about his tool
pg_plan_alternatives, which uses eBPF for tracing Postgres query plan alternatives. -
Fun stuff from Radim Marek showing how to manipulate Postgres optimizer stats to help evaluate query behaviour in different environments.
-
Ergest Xheblati explains why you should still learn SQL (despite LLMs being able to do a rather good job of writing it for you these days).
-
Etsy’s Ella Yarmo-Gray describes how they migrated Etsy’s database sharding to Vitess.
-
A couple of good blog posts from the folk at PlanetScale. First a serious one: Ben Dicken with an excellent interactive explainer of Database Transactions. Second, a silly one, in which Nick Van Wiggeren shows how to do Video Conferencing with Postgres (seriously).
AI 🔗
I warned you previously…this AI stuff is here to stay, and it’d be short-sighted to think otherwise. As I read and learn more about it, I’m going to share interesting links (the clue is in the blog post title) that I find—whilst trying to avoid the breathless hype and slop.
-
🔥 A fascinating podcast episode of Dwarkesh Podcast with Anthropic’s Dario Amodei. Pleasantly BS-free and easy enough for a non-expert like me to not feel completely lost listening to :)
Big Picture & Culture 🔗
|
There’s a theme running through this section. I’m going to crudely summarise it thus:
|
-
🔥 Brittany Ellich’s blog post was my favourite one this month with this excellent post, from which I’ll quote verbatim:
Nobody knows what the future of software engineering looks like, and that’s incredibly uncomfortable. But instead of waiting for someone to hand us the answer, I think the move is to embrace the uncertainty, because these moments of deep uncertainty have historically been moments of extraordinary opportunity.
-
Annie Vella has an accessible and unfussy way of clearly communicating, and I really enjoyed both of her recent posts, Finding Comfort in the Uncertainty and The Middle Loop.
-
I wrote a ranty post to get stuff off my chest, but not nearly as articulately nor considered as many others in this section: AI will f**k you up if you’re not on board.
-
Chris Gambill’s post is in a similar vein to mine: If You Aren’t Using AI, You Are Already Legacy.
-
🔥 Nolan Lawson’s post We mourn our craft may sound hyperbolic but there is genuinely a sense of grief that I sense amongst engineers at something that is being taken from them whether they like it or not (and regardless of whether they themselves adopt it or not).
-
The concept of grief and loss and its corresponding stages (anger, denial, bargaining, etc) actually fit well with many of the emotions that I’m seeing play out at the moment, and Andrew Murphy explores it in exactly this framing: The five stages of losing our craft.
-
Some of the folk in the "denial" camp need to read Charity Majors' latest post, in which she addresses head-on the point that AI now is not what it was when people dismissed it even last year.
When the facts change, I change my mind
-
Outside of the pondering and realisation that the world has changed for software engineers comes the refreshing and entertaining reactions against one of the downsides of AI:
-
🔥 Kirill Bobrov - Stop Feeding Me AI Slop.
-
Brent Ozar - I’m Not Gonna Waste Time Debunking Crap on LinkedIn.
-
See also Brandolini’s law.
-
-
Open Source Licensing and AI Policies 🔗
The ability of LLMs to write code has blown wide open the debate on software licensing and what constitutes a 'copy'.
-
Simon Willison analyses the recent events on the chardet project that ignited the latest round of this debate and Thomas Claburn in El Reg has commentary from Bruce Perens (who created the original Open Source Definition).
-
antirez has an excellent commentary piece on the subject, as well as details of implementing a clean room Z80 / ZX Spectrum emulator with Claude Code (not specific to OSS per se, but interesting to understand the concepts being used).
Meanwhile, projects and foundations are trying to rapidly keep up with what LLMs can do, and codify what role they should play in contributions:
-
Phil Eaton - Source-available projects and their AI contribution policies.
-
Kate Holterhoff - The Generative AI Policy Landscape in Open Source.
Building with AI 🔗
-
Thoughtworks' Rahul Garg discusses Context Anchoring.
-
Cat Hicks has a neat idea for Claude Code - a
learning-opportunitiesskill that has it teach you and build your expertise of what you’re building with it. I tried something very (very) crudely along the same lines in Claude the Instructor and found it very useful. -
Hajime Takeda has a thorough explainer of How to Build a Production-Ready Claude Code Skill.
-
Daniel D. McKinnon has some home-truths for PMs having fun vibe-coding features for their products, such as:
If the feature is actually important, fix the system for prioritization (your real job) rather than circumventing it.
He’s also got good advice on writing GenAI evals.
-
Geoff Cisler and team at Whoop have written about their use of evaluations to test and track the performance of their Agents.
-
Joe Hellerstein discusses AI and the Mixed-Consistency Future (files instead of databases isn’t gonna work for everything).
-
Rajanikant Vellaturi discusses RAG and Data Engineering.
-
As people get past the "omg this is magic" initial experience of coding agents, understanding exactly what they’re doing is often the next question. tapes is one tool that aims to address this, sitting between your agent and the model provider and giving a bunch of instrumentation and insight.
-
Fascinating exploration from Mitchell Turner of the idea of promptware: Brainworm - Hiding in Your Context Window.
The MCP Debate 🔗
MCP was hot (you don’t need CLI access!), and then it wasn’t (it burns context!), and now…It Depends ;)
-
Allen Hutchison has a good article explaining why MCP Isn’t Dead You Just Aren’t the Target Audience (tl;dr MCP is still vastly important for agents not running with CLI access).
-
Samir Amzani - Your MCP Server Is Eating Your Context Window. There’s a Simpler Way.
-
🔥 Charles Chen - MCP is Dead; Long Live MCP!.
-
Ben Davis - "The current 'MCP is dead discourse' is my current favorite example of the really annoying "simplicity" brainrot that’s been plaguing tech for a while" (Twitter thread).
AI in Practice 🔗
-
🔥 Instacart’s Moein Hasani describes how they improved their recommendations engine using tools and techniques including LLMs and Evals.
-
Tao Ruangyam at Zalando has a good blog post about using LLM-as-judge to ensure the quality of their search results.
-
Fascinating detail of how Uber are using AI for development (blog, talk), as well as an agentic system for writing design specs.
-
Tan Wang at Pinterest has practical details of how they’re implementing an MCP ecosystem.
-
Overview from Aman Gupta and Daniel Braithwaite at Nubank of how they’re building AI agents, doing evals, and semantic versioning of prompts.
-
Surabhi Gupta details how Klaviyo are approaching AI-driven engineering.
-
Sneh Agrawal and team at Grab built AI agents to help them support users of their data warehouse.
-
If you’re still not convinced that AI is out there right now delivering value for businesses, check out this list from Allen Hutchison of real-world AI agent examples.
And finally… 🔗
Nothing to do with data, but stuff that I’ve found interesting or has made me think (or smile).
-
🔥 A great piece from Chris Hillman, the tldr of which is the title (but read the article too!) Your Friends Will Be There for You. Your Work Won’t.
-
Dan Carlin (he of Hardcore History) is one of my absolute favourite podcasters. His style of presenting and depth of historical material is just wonderful. That’s why this post hit me harder than I’d expected:
I think it is just hard to talk with passion and enthusiasm […] about events thousands of years ago on the history show when such momentous ones are occurring to all of us right now. […] We ARE living through absolutely momentous times (and dangerous ones). Don’t allow yourself to be gaslit about that. Any fan of History can see it.
-
The concept of "managing up" is important at work, and Lara Hogan describes it well in Managing your manager.
-
🔥 Almog Gavra has created a very nifty tool called YuzuDraw which lets you create—and edit—ASCII-art style diagrams. It works with coding agents too.
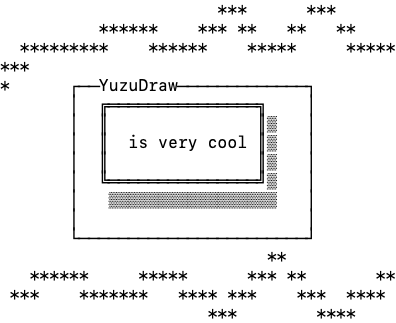
-
Kagi Translate includes a target language of LinkedIn Speak ;)
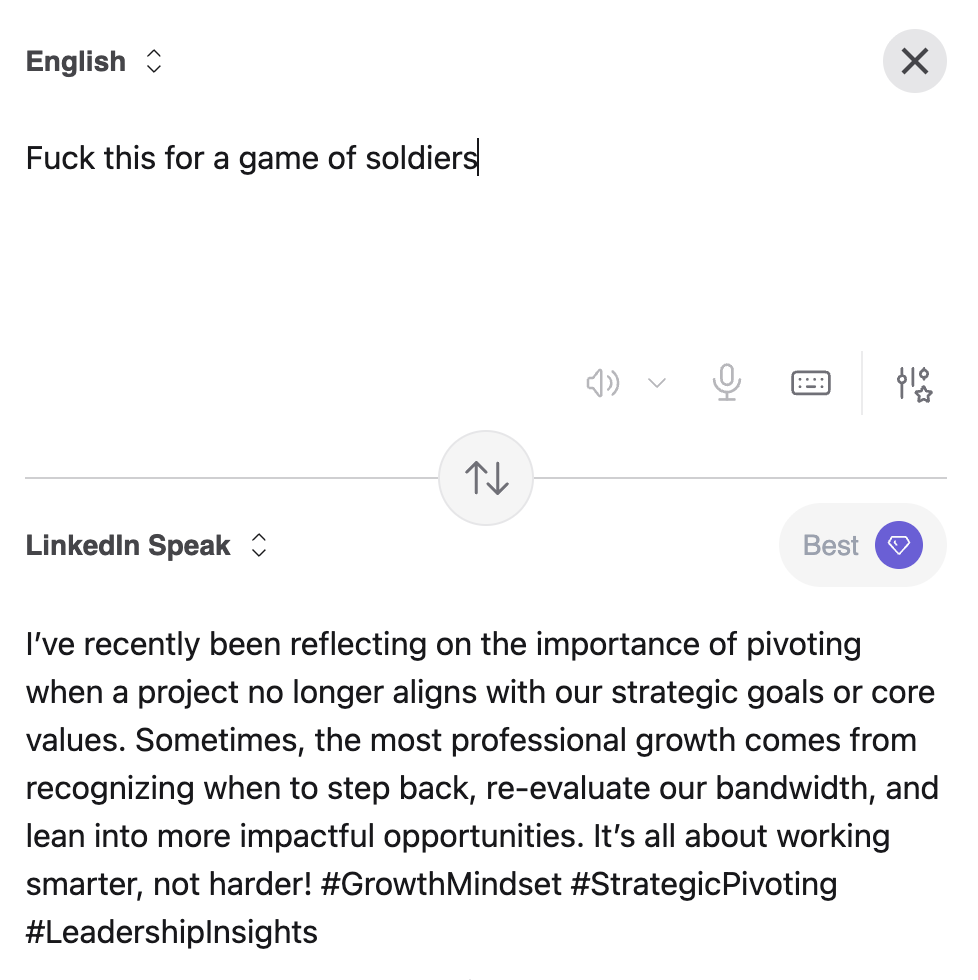
In all seriousness though, Kagi is a set of applications that I rather like for its focus on functionality and respect, not growth hacking and enshittification. Their small web is a joyful reminder of how the internet used to be before walled gardens and karma-farming, and the search engine lets you wrest back control of your search results from the spam and shit (sorry, "sponsored listings").
-
🔥 I Taught My Dog to Vibe Code Games. No notes.
|