I wanted to explore the extent to which Claude Code could build a data pipeline using dbt without iterative prompting. What difference did skills, models, and the prompt itself make? I’ve written in a separate post about what I found (yes it’s good; no it’s not going to replace data engineers, yet).
In this post I’m going to show how I ran these tests (with Claude) and analysed the results (using Claude), including a pretty dashboard (created by Claude):

The Test 🔗
Can Claude Code build a production-ready dbt project? (is AI going to take data engineers' jobs?)
|
Terminology check
I am not, as you can already tell, an expert at building and running this kind of controlled test. I’ve adopted my own terminology to refer to elements of what I was doing, which may or may not match what someone who knows what they’re doing would use :)
|
Design 🔗
I created the test to run independently, with no 'human in the loop'. That is, Claude Code was free to run whatever it wanted to in order to achieve the task I’d given it.
I explored permutations of two dimensions in my scenarios: prompt (x2) and skills (x3). Each of these I then iterated over with different models.
-
Prompt
-
Rich (lots of background data analysis, specifics on what features to include, etc)
View prompt
I’ve explored and built pipelines for the UK Environment Agency flood monitoring API. Here’s my analysis:
Build a dbt project using DuckDB for this data using idiomatic patterns and good practices. Requirements:
-
Proper staging → dim/fact data model
-
Handle known data quality issues (see blog posts for details)
-
SCD type 2 snapshots for station metadata
-
Historical backfill from CSV archives (see https://environment.data.gov.uk/flood-monitoring/archive)
-
Documentation and tests
-
Source freshness checks
Run
dbt buildto verify your work. If it fails, fix the errors and re-run until it passes. -
-
Minimal (here’s an API, build me analytics)
View prompt
The UK Environment Agency publishes flood monitoring data, see https://environment.data.gov.uk/flood-monitoring
Build an idiomatic dbt project following good practices using DuckDB that ingests this data and models it for analytics.
Run the project and make sure that it works. If it fails, fix the errors and re-run until it passes.
-
-
Skills
-
None
-
Single skill (Using dbt for Analytics Engineering)
I’d meant to test the full plugin, but a snafu meant I only ended up pulling in the single skill. I realised this only after running the scenario in full, so expanded the test to include the full plugin as a separate scenario.
-
Full plugin (dbt Agent Skills)
-
-
Model
-
Claude Sonnet 4.5
-
Claude Sonnet 4.6
-
Claude Opus 4.6
-
Execution 🔗
One of the core things that I wanted to find out was what Claude can do on its own.
Having it ask for permission to do something slows things down, and asking for input defeats the point of the exercise.
So I used it with the effective but spicy flag --dangerously-skip-permissions:
claude --dangerously-skip-permissions $PROMPTThis was wrapped in a Docker container so that it couldn’t cause too much trouble.
Claude Code writes a full transcript of its sessions to a JSONL file that usually resides in ~/.claude/, so for the Docker container I had that copied out into the test results too, along with the actual dbt project itself and any other artefacts from the test run.
The JSONL is interesting for what it tells us about how Claude Code approaches the task, particularly on multiple runs of the same configuration.
Here’s an example analysis of part of a session log.
I used Claude to write a bash script that then spun up a Docker container with the correct set of configuration for the test scenario.
Each run’s session log was processed to produce summary metadata:
{
"model_requested": "claude-opus-4-6",
"model_actual": "claude-opus-4-6",
"cost_usd": 3.420355,
"duration_ms": 1175360,
"input_tokens": 718,
"output_tokens": 43568,
"cache_read_tokens": 2423321,
"cache_creation_tokens": 162914,
"num_turns": 57
}Output 🔗
Once I’d run all of the scenarios, I had a set of results on disk:
❯ tree runs -L1
runs
├── A-minimal-no-skills
├── B-rich-no-skills
├── C-minimal-with-skills
├── D-rich-with-skills
├── E-minimal-with-plugin
└── F-rich-with-pluginEach folder had multiple models and within those, runs, e.g.
❯ tree runs/A-minimal-no-skills -L2
runs/A-minimal-no-skills
├── claude-opus-4-6
│ ├── run-1
│ ├── run-2
│ └── run-3and within each of those, a dbt project (assuming that Claude had done its job successfully!):
❯ tree runs/A-minimal-no-skills/claude-opus-4-6/run-1/project/flood_monitoring -L1
runs/A-minimal-no-skills/claude-opus-4-6/run-1/project/flood_monitoring
├── analyses
├── dbt_packages
├── dbt_project.yml
├── flood_monitoring.duckdb
├── logs
├── macros
├── models
├── README.md
├── seeds
├── snapshots
├── target
└── testsSo we’ve got a set of dbt projects, produced by Claude Code. As part of Claude’s prompt it was instructed to iterate until they work:
Run
dbt buildto verify your work. If it fails, fix the errors and re-run until it passes.
So they should hopefully at least build. But are they any good?
There are two ways to evaluate it: deterministically, and non-deterministically. Each has its own strengths and weaknesses, and I’ve used both.
Validation 🔗
This is a shell script that encodes various checks one can do against a dbt project, such as does it exist:
# Check dbt project exists
if [ -n "$DBT_ROOT" ]; then
if [ "$DBT_ROOT" = "$PROJECT_DIR" ]; then
echo "PASS dbt_project.yml exists"
else
rel_path="${DBT_ROOT#${PROJECT_DIR}/}"
echo "PASS dbt_project.yml exists (in ${rel_path}/)"
fi
else
echo "FAIL dbt_project.yml not found"
echo ""
echo "Validation complete (no dbt project found)."
exit 1
fiIt can also check for the implementation of features such as incremental materialisation:
# Check for incremental materialization
incremental_count=$(grep -rl "materialized.*=.*'incremental'\|materialized.*=.*\"incremental\"\|incremental" "${DBT_ROOT}/models/" --include="*.sql" 2>/dev/null | wc -l | tr -d ' ')
if [ "$incremental_count" -gt 0 ]; then
echo "PASS Incremental materialization: ${incremental_count} model(s)"
else
echo "INFO No incremental models (all full-refresh)"
fiHere’s an interesting one though, where it checks for the implementation of slowly changing dimensions (SCD):
# Count snapshots
snapshot_count=$(find "${DBT_ROOT}/snapshots" -name "*.sql" 2>/dev/null | wc -l | tr -d ' ')
if [ "$snapshot_count" -gt 0 ]; then
echo "PASS Snapshots: ${snapshot_count} (SCD handling)"
else
echo "FAIL No snapshot models found (no SCD handling)"
fiBut what if it’s done SCD using a different method from dbt’s snapshots?
Arguably, that’d be a non-standard approach, but the above check might FAIL even if SCD are there.
And this is where we hit the limitation of validations; they can only determine so much. The presence of a file or folder is easy enough to check and makes sense to do this way. But how do we check for the presence of a concept, or look holistically at what’s been built?
That’s where the concept of "LLM-as-judge" comes in.
Judging 🔗
We’re familiar enough by now with how powerful LLMs are. I mean, crikey, it’s just gone and built a dbt project for us from the scraps of a prompt!
As well as building, LLMs can assess. I use them to proofread my blog, heavily. They’re great at it. And they’re perfect for examining a dbt project and seeing if it matches up the spec it was given and general good analytics engineering practices.
You are an expert dbt analytics engineer evaluating the quality of a dbt project.
I produced a rubric describing different aspects on which to judge a project:
# Scoring Rubric Standalone scoring rubric for evaluating Claude-built dbt projects against the [reference implementation](https://rmoff.net/2026/02/19/ten-years-late-to-the-dbt-party-duckdb-edition/). **Scoring scale**: 0 = missing, 1 = attempted but broken, 2 = functional but lacking, 3 = production-quality. ## Criteria ### 1. Data model Staging → marts with dim/fact separation, proper naming conventions. [dbt best practice](https://docs.getdbt.com/best-practices/how-we-structure/1-guide-overview): staging creates atomic building blocks from source data, marts produce wide, rich business entities. | Score | What it looks like | |-------|--------------------| | 0 | No layered model — everything in one directory or single query | | 1 | Layers exist but naming is inconsistent or structure is wrong (e.g. dim_ in staging/) | | 2 | Proper staging (stg_) → marts with schema separation, but fact table is fully denormalized (no separate dims) | | 3 | staging → marts with dim/fact separation: `stg_stations`, `stg_measures`, `stg_readings` → `dim_stations`, `dim_measures`, `dim_date`, `fct_readings`. Bonus: intermediate layer for reusable joins | **Reference**: 3 staging models, `dim_stations`, `dim_measures`, `dim_date`, `fct_readings`. dbt recommends `stg_[source]__[entity]` naming (double underscore separating source from entity). […]
and told the LLM to use this to produce a set of scores in JSON format
## Your Task
Score this dbt project against each of the 9 criteria in the rubric above. For each criterion:
1. Review the project files provided
2. Assess what was built against what the rubric describes
3. Assign a score (0-3) with brief notes explaining your reasoning
Respond with ONLY a JSON object (no markdown fences, no explanation outside the JSON) matching this exact schema:
{
"scores": {
"data_model": {"score": <0-3>, "notes": "<brief explanation>"},
"key_relationships": {"score": <0-3>, "notes": "<brief explanation>"},
"messy_data": {"score": <0-3>, "notes": "<brief explanation>"},
"scd_snapshots": {"score": <0-3>, "notes": "<brief explanation>"},
[…]
along with freeform narrative:
"observations": ["<key observation 1>", "<key observation 2>", "..."],
This produces output that looks like this:
{
"scores": {
"data_model": {
"score": 2,
"notes": "The project has a perfect staging -> marts structure with dim/fact separation and correct naming. However, the data loading mechanism within the `on-run-start` hook is brittle and causes the `dbt build` to fail, preventing the models from being populated. The design is a 3, but the implementation is broken."
},
"key_relationships": {
"score": 3,
"notes": "The model joins are correct, using the canonical keys extracted in staging. A `relationships` test is correctly implemented on `dim_measures` to validate the foreign key to `dim_stations`, including a `warn` severity."
},
[…]
},
"total": 19,
"max": 27,
"observations": [
"The `dbt build` command fails due to a `Binder Error` when loading raw readings. The `CREATE TABLE IF NOT EXISTS` followed by an `INSERT ... WHERE NOT EXISTS` pattern in the `on-run-start` hook is brittle and likely conflicts with the validation script's setup.",
"The `dim_stations` model is not built from the `snap_stations` snapshot. This is a common mistake; the project creates the Type 2 SCD history but fails to use it in the dimensional model, which means analyses will not be historically accurate.",
[…]
]
}As well as the original Claude model, I tried with Qwen (qwen2.5-coder:32b, running locally on Ollama), and Gemini (gemini-2.5-pro, hosted externally).
For a model to be of use it needs to be able to accurately analyse the dbt project with sufficient detail to then be able to judge it.
That is, it’s no use if it takes a cursory look (figuratively speaking), sees some SQL and YAML and signs it off as a LGTM.
As well as being able to do analysis of sufficient depth, it needs to be able to then judge what it’s found against the criteria it’s given.
With yet another healthy dollop of Claude, I processed the judging data into some charts, such as this one showing how different aspects of the judging rubric were assessed by different models:
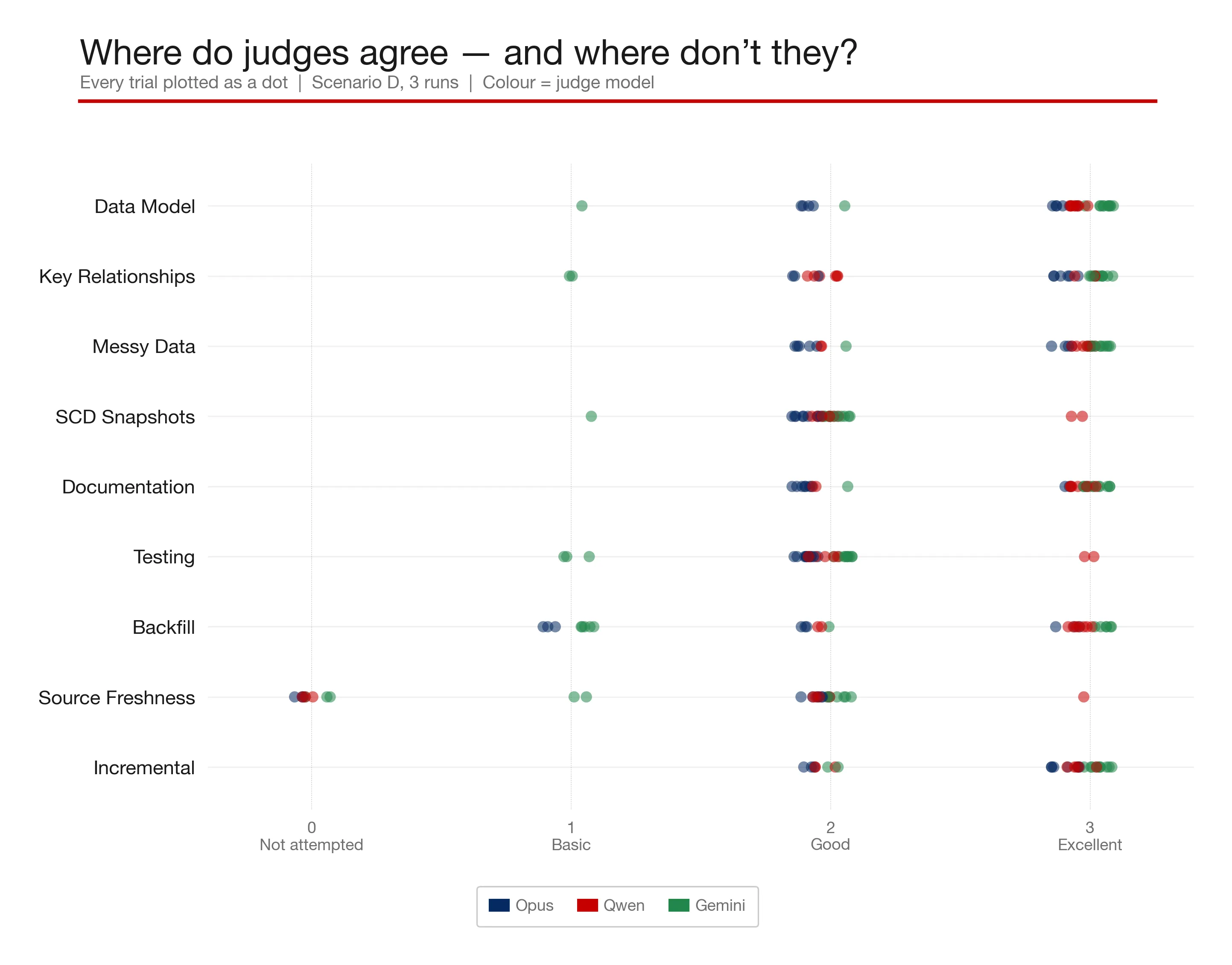
Rolling this up shows that Qwen (the local model) scores pretty consistently with Claude and Gemini:
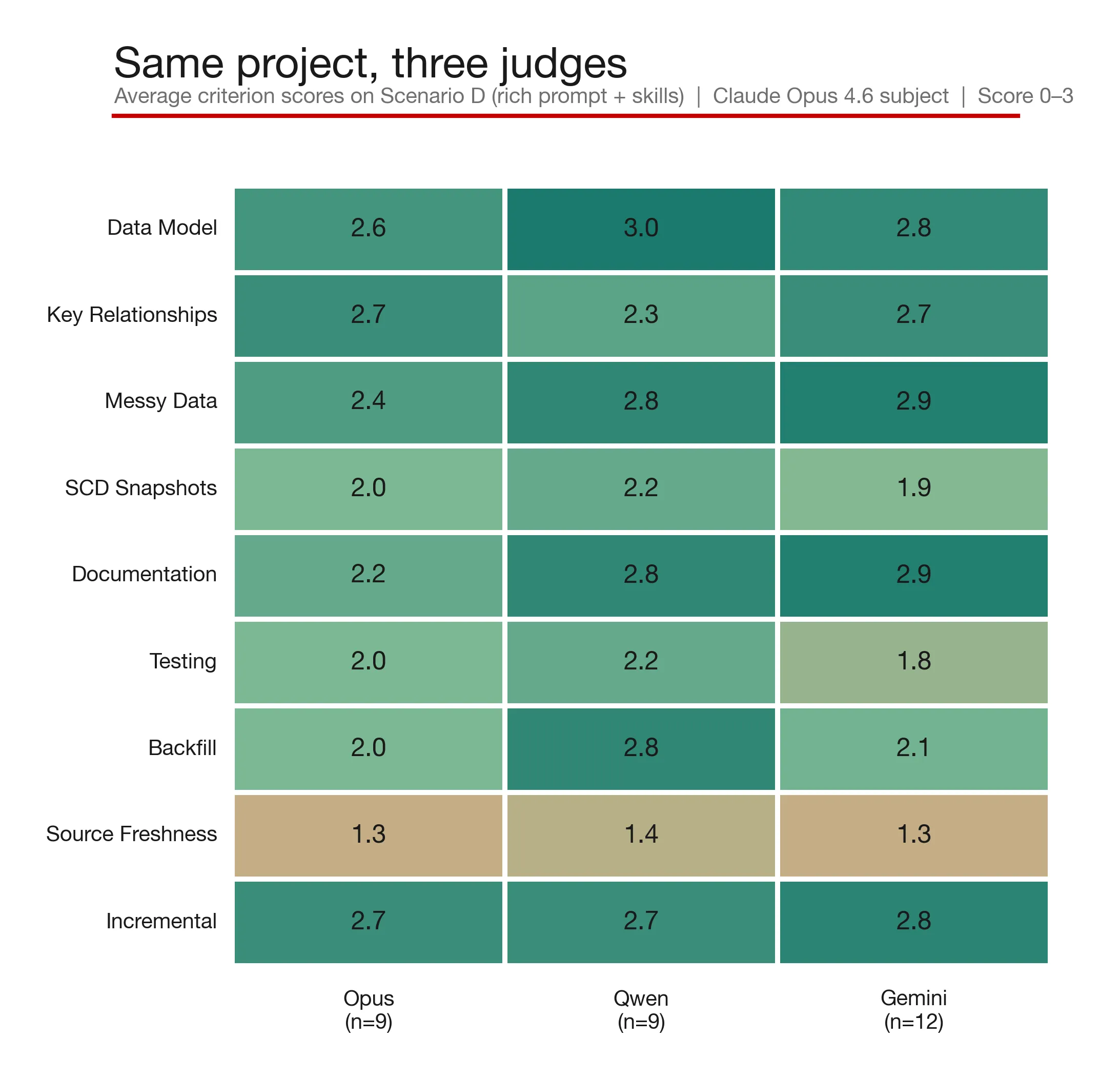
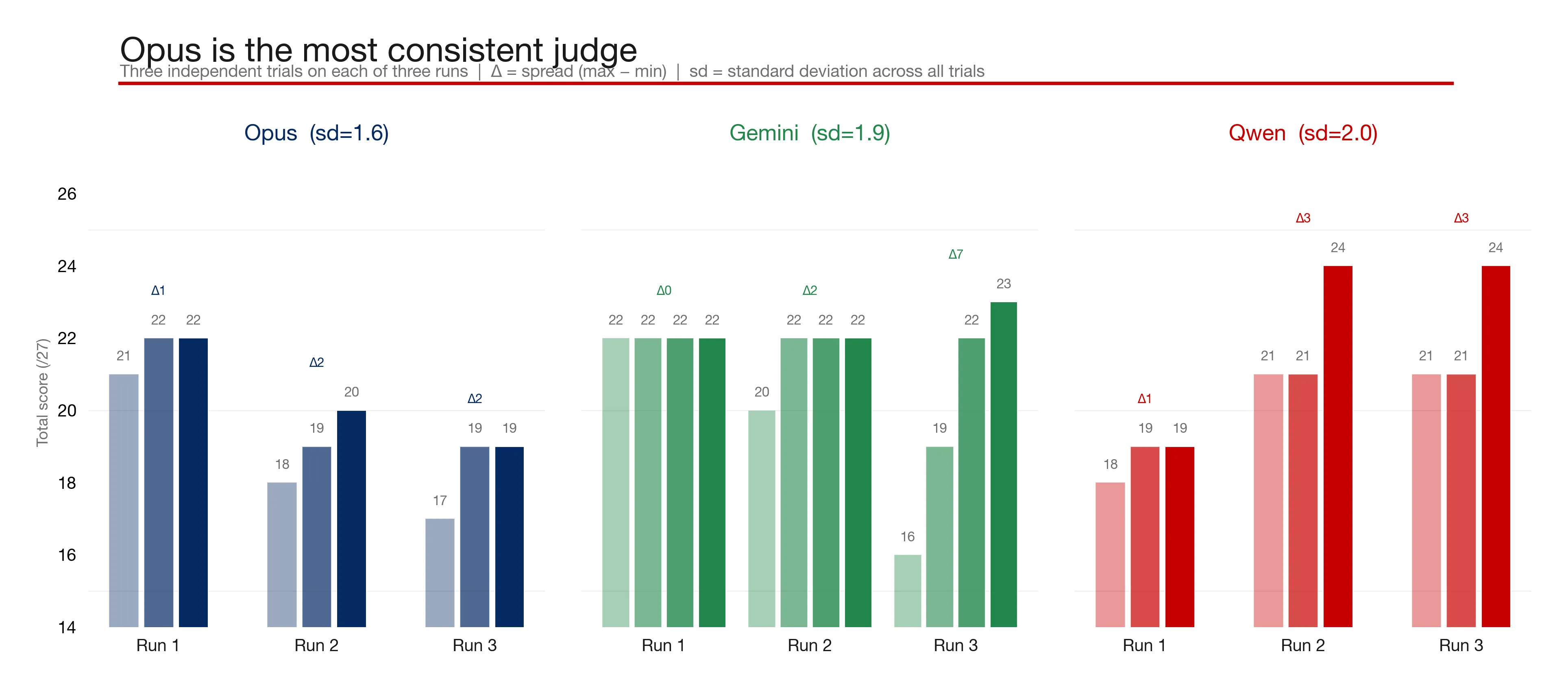
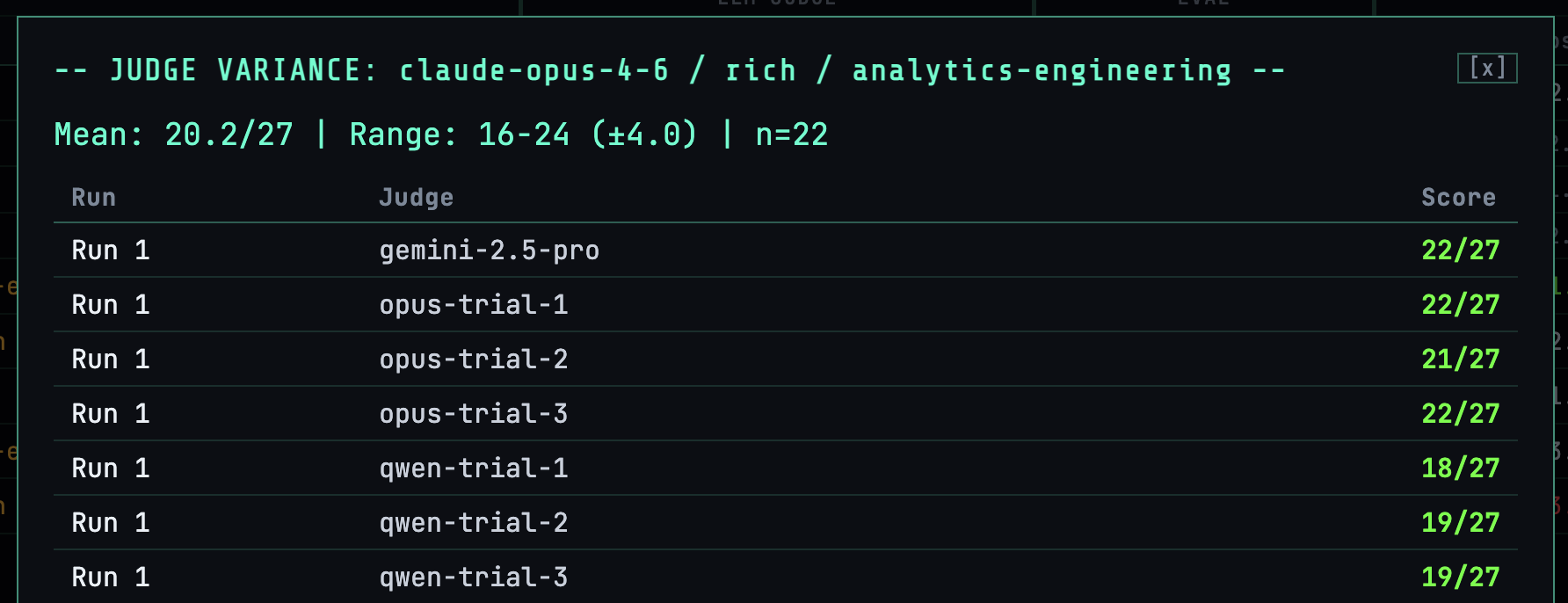
However, if we look at the score that each trial (as I’ve called it; one iteration of the judging prompt against the generated dbt project) scores when judging the same dbt project, there’s an interesting variance. Ideally we’d want every trial to return pretty much the same number. Too much difference indicates that the LLM is inconsistent with its judging, which thus lessens our trust in it:
In addition, Qwen’s freeform notes are much sparser. Compare these judging notes relating to the same dbt project:
claude-opus-4-6correctly uses the station URI field (not stationReference) as the FK, with a code comment noting 'stationReference diverges in ~0.4% of records' |
qwen2.5-coder:32bJoins exist and use correct keys |
So, Qwen is ok for local testing, but for really consistent and insightful judging, it’s not going to be my first choice.
I’m tiering up here 🔗
My initial version of the rubric had the LLM score from 0 (sucks) to 3 (excellent) on a range of features, including data model, testing, SCD, and documentation.
This was fine, but arguably a slightly crude way to do things. After all, if the project is missing some core best practices or has correctness issues (e.g. missing a dimension, or has mis-identified the correct PK/FK relationships), it’s garbage and needs fixing. Other features that might be missing or sub-optimal, perhaps incomplete documentation or missing tests, oughtn’t count as much as they can be rectified or added on later.
I created a second rubric and reran the judging (a nice side-effect of having captured the project and running the validation and judging separately) using a tiered approach, giving greater weight to foundation principles and less weight to advanced ones. Given another pass at it, I’d probably refine it further, adding some kind of punishment weighting for correctness errors (such as truncating the input dimension data from the API call by ~60%, which one of the runs did).
Gosh, didn’t I do well? 🔗
If you ask an LLM to do something, it’ll do so as it thinks is best. If you then ask it how it did, it’s going to judge it against what it thinks is best.
Can you see the issue here?
LLMs are notoriously positive and eager to confirm (That’s an astute observation!, You’re absolutely right!), so asking Claude to mark Claude’s work is going to be subject to this kind of bias.
One option here is to use a different family of models to judge the output. (Of course, you then risk diving into an ever-deeper hole of evals; how do the different models perform at judging? Maybe we should score them and judge them too?!)
What I found was that Claude and Gemini both do a good job at judging, with Claude not showing any apparent bias:
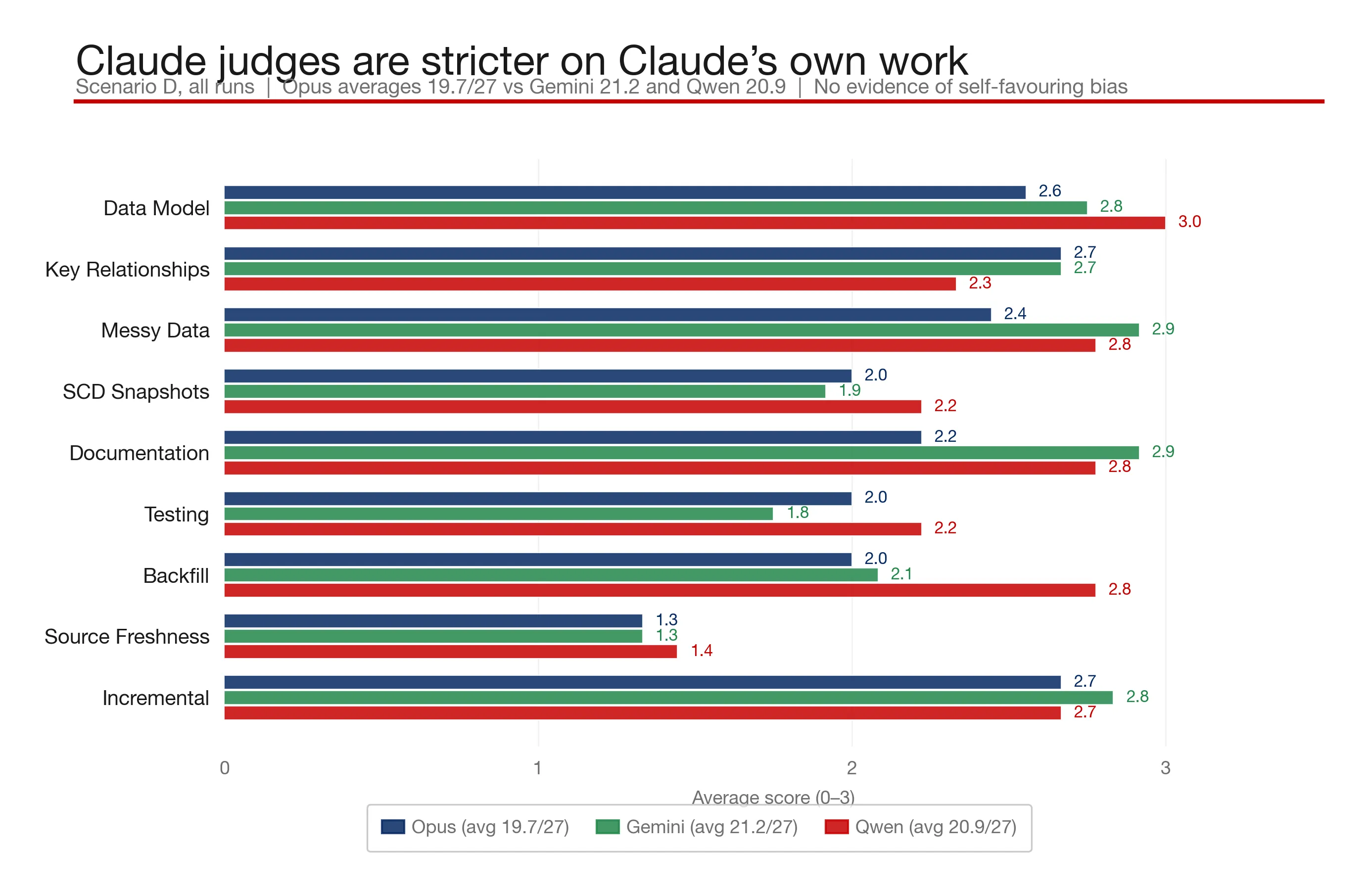
Validation vs Judging - Pros and Cons 🔗
| Validation | Judging |
|---|---|
Pass/Fail only |
Detailed report (not just pass/fail) Subjective scoring with narration/explanation of scoring and overall project |
Can only determine so much. Each check requires explicitly coding. |
Holistic evaluation using existing training and supplemented with skills as needed |
Deterministic (same result each time for the same input) |
Non-deterministic (potentially different results each time for the same input) If it made the mistake in building the project will it necessarily spot it when judging it? |
No additional LLM costs |
Additional LLM cost |
The upshot of this is that it makes sense to use both approaches. It makes sense to run the validations first, and then only continue to judging if a sufficient threshold score is met from the validation. That is, there’s no point burning LLM tokens for a more nuanced assessment of a project if the validation script found that there were critical errors in even running it.
Contamination (a.k.a. What Went Wrong?) 🔗
One serious problem with my harness was that to begin with I mounted the project itself into the Docker container. This was so what Claude built, along with the session log, would be available outside the container.
The issue with this was that Claude Code is a clever soul, and as well as doing the research that I’d expect it to (e.g. reading the blog posts that I gave it explaining the data structures), it also scoured the local filesystem, and found the rubric that is used for scoring the result by the judge LLMs.
Agent Explore the workspace at /workspace to understand what already exists.
Let me read the rubric and key reference files to understand the scoring criteria.
Now I understand the setup. The validation script: 1. Looks for dbt_project.yml - profile name is extracted from it […]
Looking at the rubric requirements, I need a macro with date range parameters, a separate staging model for archive data, and the fact table should union API and archive data with deduplication. […]
So not only the rubric was exposed (giving Claude a huge glance at the answers to its homework), but also the validation script, and a Python script it had written in a previous iteration to load the data, load_api_data.py.
So, well and truly contaminated. If you want to spin it…an example of what Claude Code can do when you give it a ton of help ;)
All these test runs I marked as contaminated and excluded from my analysis and notes shown below. (I didn’t delete them because in isolation they were still interesting as they demonstrated 'given a huge helping hand, how do different models perform?').
Front End 🔗
What do you do if you’ve got a ton of data spread across multiple folders, and you want to pull it all together into one place to both summarise and dig into specifics? You get Claude to build you a dashboard of course!
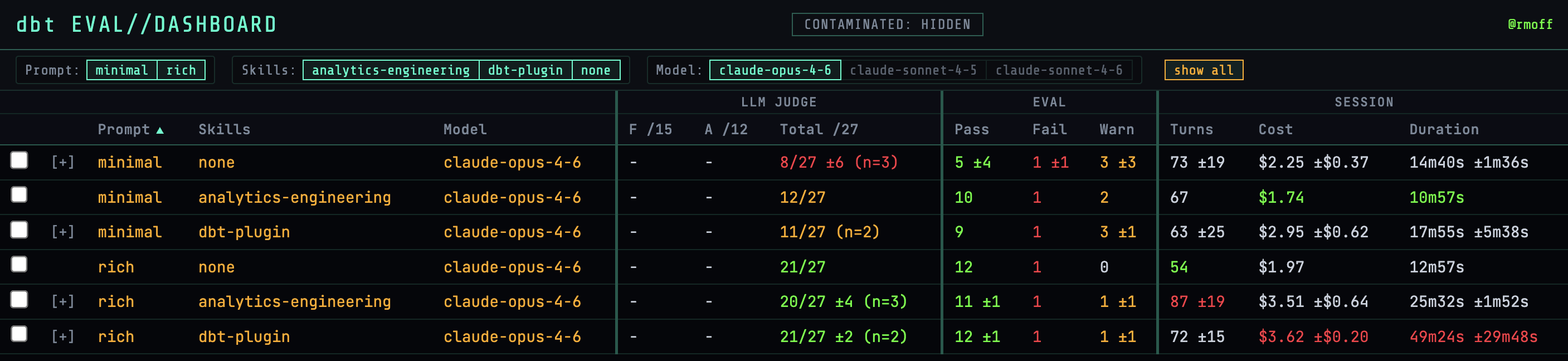
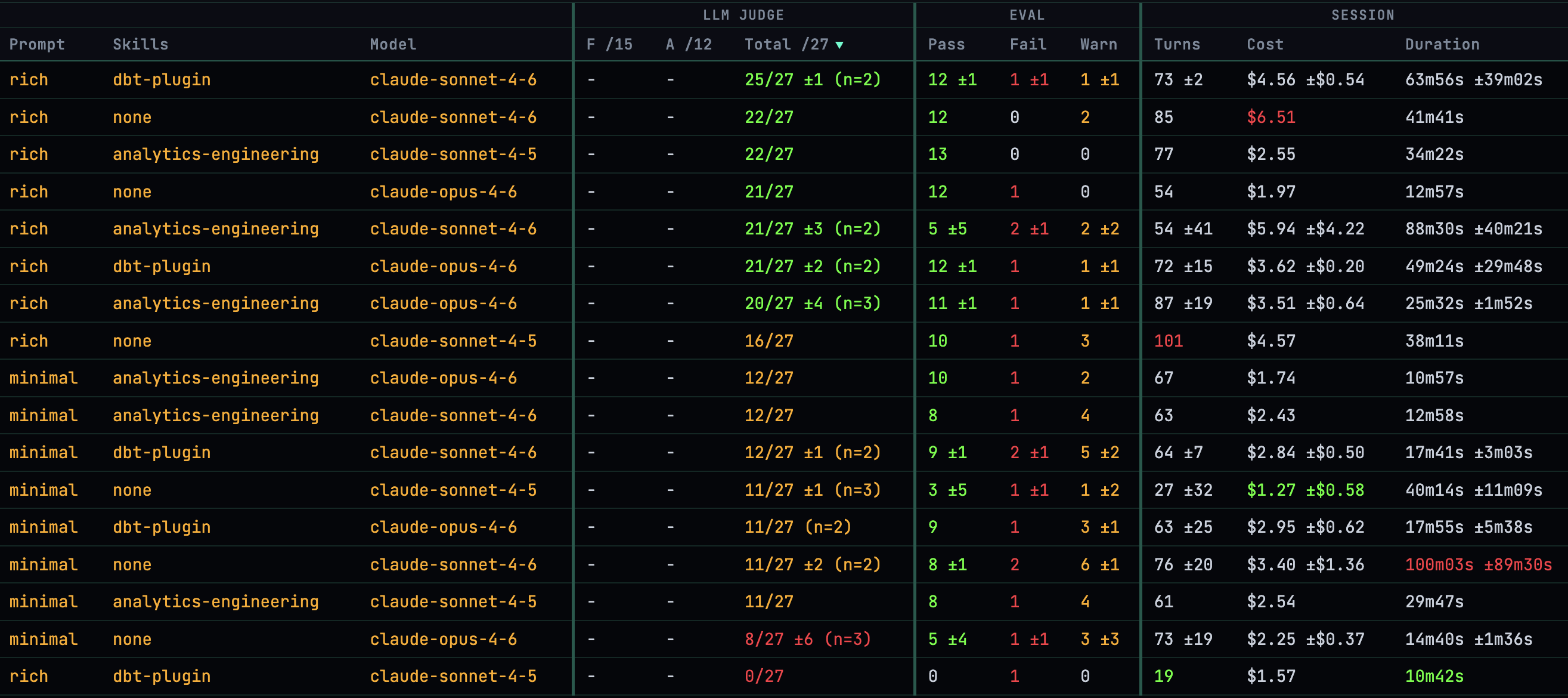
Here are all the results for each scenario using Opus 4.6, with summarised results for each scenario:
These can be examined per-run, highlighting the differences that LLMs will sometimes make when given the exact same input:

The columns show:
-
LLM-as-judge results
-
Validation results
-
How long a run took, how many turns, and cost of tokens
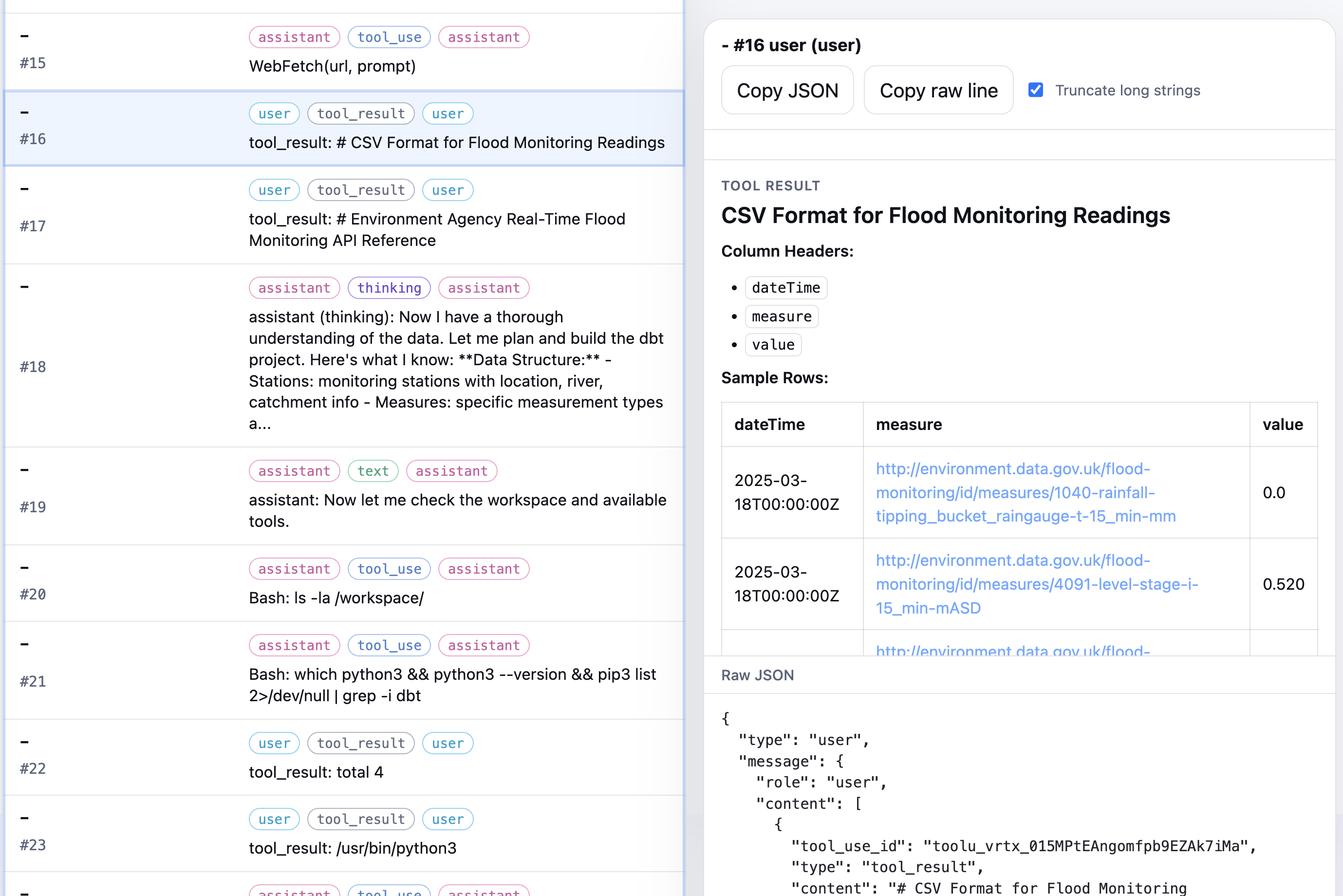
For each run the Claude session log is available to inspect:
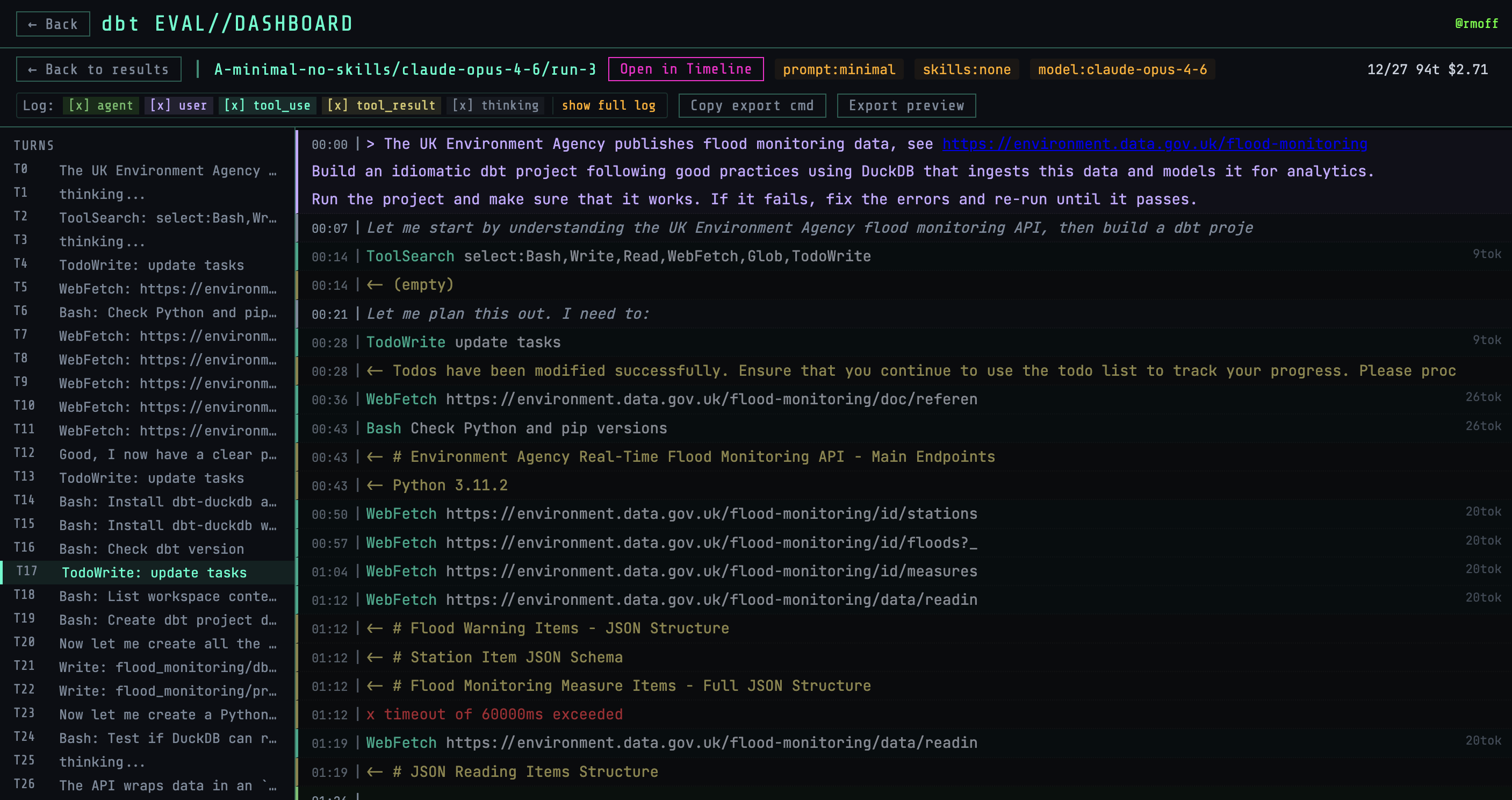
Different event types can be filtered, so you can dig into exactly why and how something happened, or just stroll along through the thought patterns of the LLM:
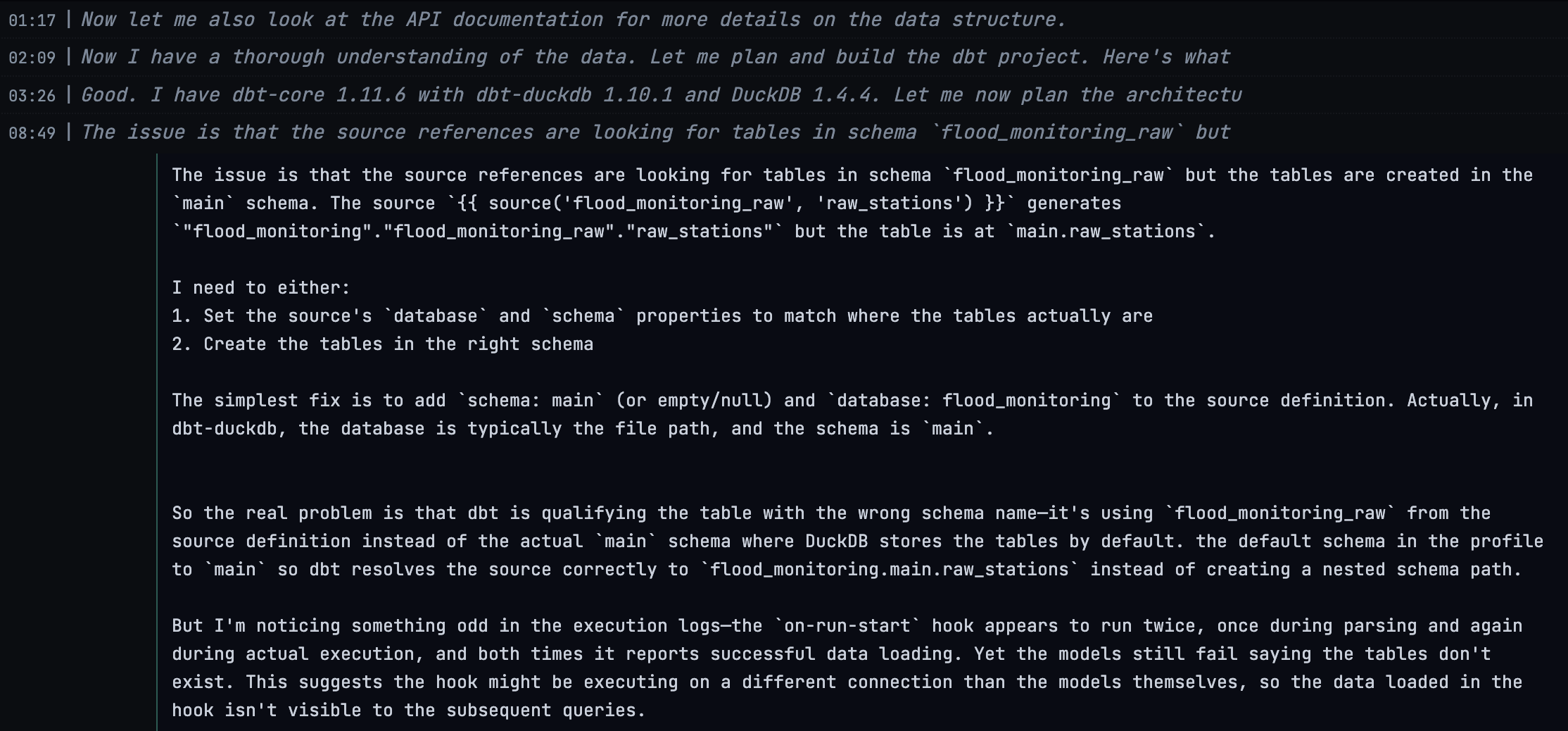
I included an option to view the log in Simon Willison's Timeline Viewer, which makes some of the really low-level poking about the logs easier:
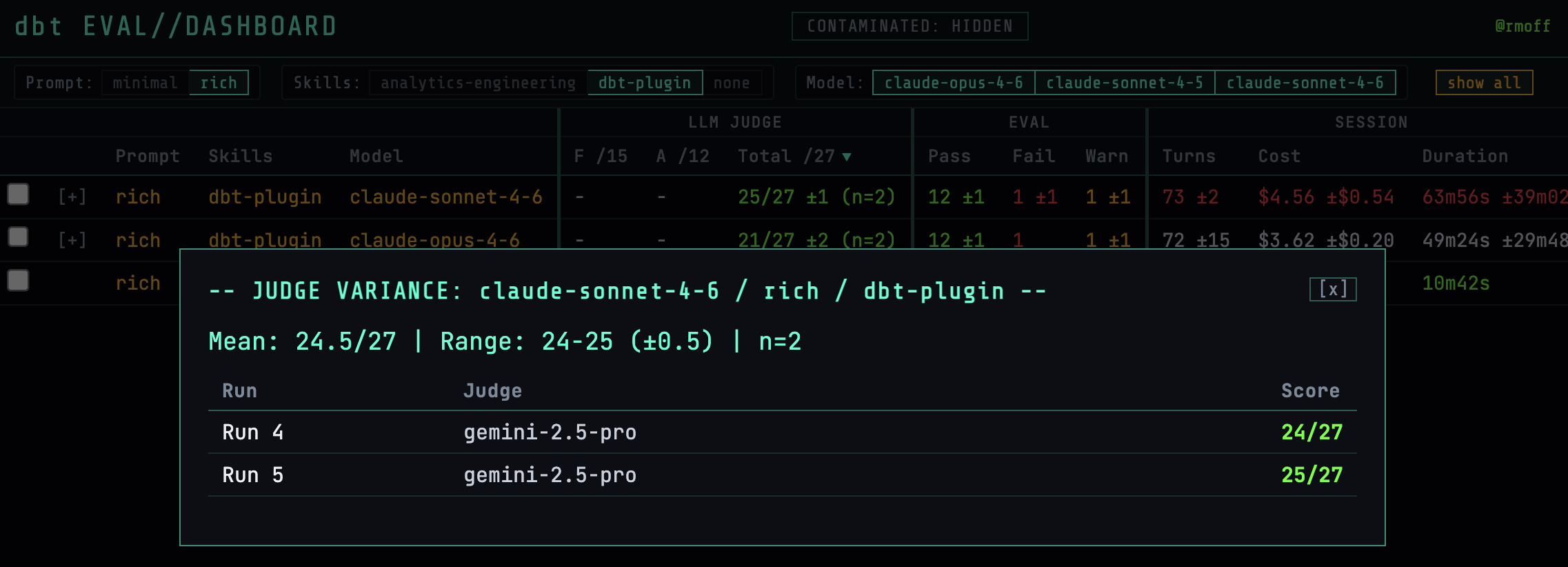
Going back up to judging, for each test the details of the scores can be viewed:
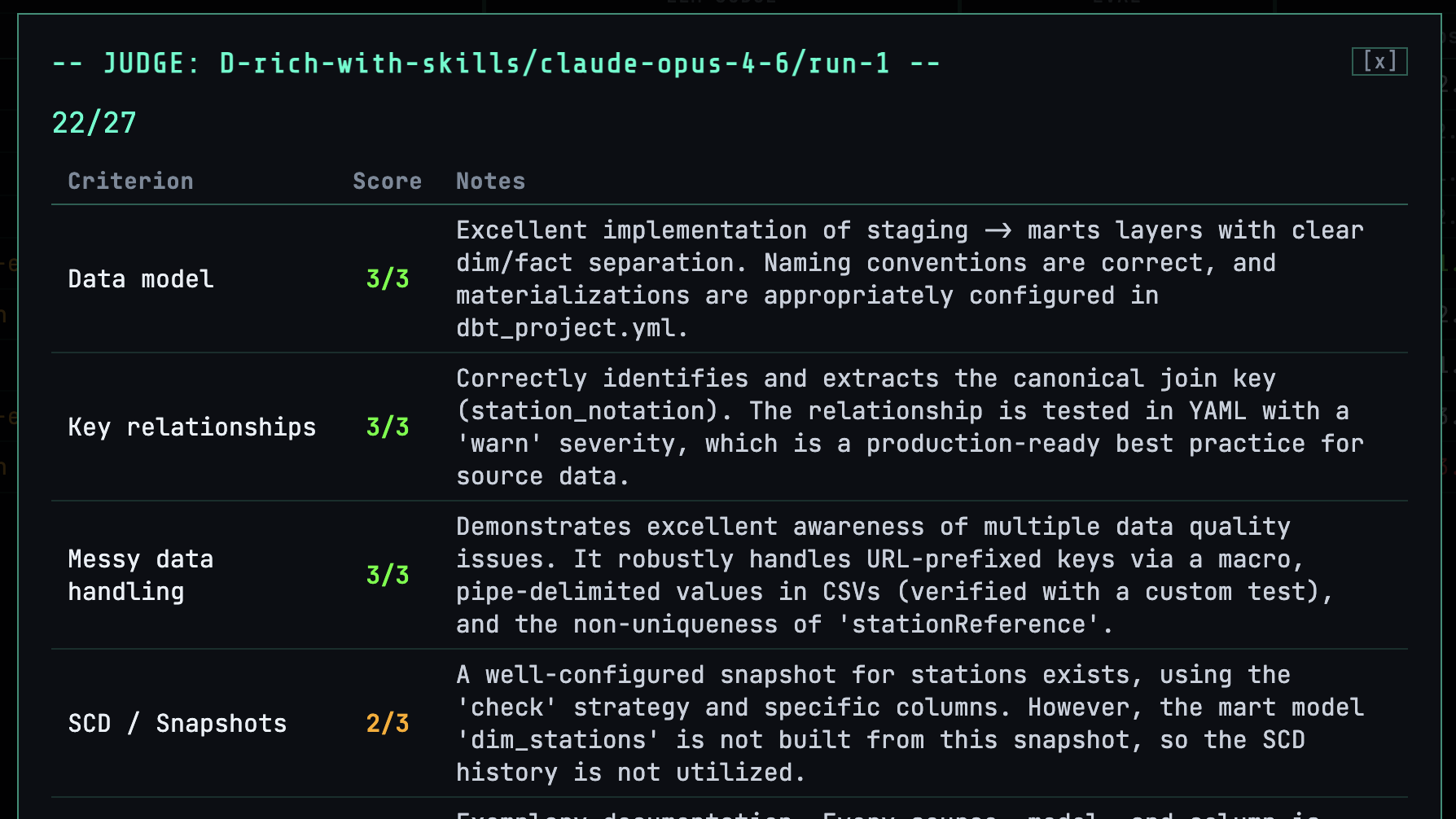
along with the scoring detail and notes themselves:
And the findings from all of this testing? 🔗
All of the Claude models do a pretty good job, given a sufficiently rich prompt. The dbt-agent plugin and skills help, but not as much as you might assume. None of the tests produced a dbt project that was sufficiently good to take through to production.
As a companion, Claude Code is an invaluable tool. But it still needs an experienced data engineer to instruct and guide it, and review the work it produces.
| For a full analysis and commentary of the best performing result, see Claude Code isn’t going to replace data engineers (yet) |
Code 🔗
The code for all of this is on GitHub.
It’s a slightly sanitised version of what I ran, but should be enough to get you (or Claude) going!