
Ten years late (but hopefully not a dollar short) I recently figured out what all the fuss about dbt is about.
Well that’s cute, Robin, you might be saying. Congratulations for catching up on what data/analytics engineers have been doing for years now. But you see, coding by hand is so 2025. Didn’t you hear? AI is going to replace data engineers.
No it’s not (at least, not yet). In fact, used incorrectly, it’ll do a worse job than you. But used right, it’s a kick-ass tool that any data engineer should be adding to their toolbox today *. In this article I’ll show you why.
I’d already used Claude to teach me dbt, and so I was very curious to see to what extent Claude Code (at the beginning of March 2026) could actually write a dbt project. Not only that, but:
-
Can Claude build a credible dbt project from real data?
-
How much help (prompting) does it need; can I just give it the API source, or does it need the analysis work done for it?
-
What difference do the skills that dbt labs recently published make?
-
How do the different Claude models perform?
-
How do you actually evaluate these different factors? (tl;dr crash-course in evals and LLM-as-judge assessment of what was built each time)
|
I’ve deliberately split this write-up into two posts as they each address different points and interests:
|
Building a dbt project with Claude Code 🔗
Here’s the prompt that I gave Claude Code, running with model Opus 4.6:
I've explored and built pipelines for the UK Environment Agency flood
monitoring API. Here's my analysis:
- Data exploration: https://rmoff.net/2025/02/28/exploring-uk-environment-agency-data-in-duckdb-and-rill/
- Pipeline build: https://rmoff.net/2025/03/20/building-a-data-pipeline-with-duckdb/
Build a dbt project using DuckDB for this data using idiomatic patterns
and good practices. Requirements:
- Proper staging → dim/fact data model
- Handle known data quality issues (see blog posts for details)
- SCD type 2 snapshots for station metadata
- Historical backfill from CSV archives (see https://environment.data.gov.uk/flood-monitoring/archive)
- Documentation and tests
- Source freshness checks
Run `dbt build` to verify your work.
If it fails, fix the errors and re-run until it passes.As well as the above prompt, I also gave Claude access to the newly-shipped dbt-agent-skills from dbt Labs.
It built me a working dbt project!
.
├── dbt_packages
├── dbt_project.yml
├── macros
│ └── generate_archive_urls.sql
├── models
│ ├── marts
│ │ ├── _marts__models.yml
│ │ ├── dim_date.sql
│ │ ├── dim_measures.sql
│ │ ├── dim_stations.sql
│ │ ├── fct_readings.sql
│ │ └── station_freshness.sql
│ └── staging
│ ├── _flood_monitoring__models.yml
│ ├── _flood_monitoring__sources.yml
│ ├── stg_flood_monitoring__measures.sql
│ ├── stg_flood_monitoring__readings_archive.sql
│ ├── stg_flood_monitoring__readings.sql
│ └── stg_flood_monitoring__stations.sql
├── profiles.yml
├── snapshots
│ └── snap_stations.sql
└── tests
└── assert_recent_readings.sqlIt compiles and it runs:
1 of 37 START sql table model main.dim_date .................................... [RUN]
2 of 37 START sql view model main.stg_flood_monitoring__measures ............... [RUN]
3 of 37 START sql view model main.stg_flood_monitoring__readings ............... [RUN]
4 of 37 START sql view model main.stg_flood_monitoring__stations ............... [RUN]
[…]
37 of 37 PASS unique_station_freshness_station_id .............................. [PASS in 0.01s]
36 of 37 PASS not_null_station_freshness_station_id ............................ [PASS in 0.01s]
Finished running 1 incremental model, 1 snapshot, 4 table models, 26 data tests, 2 unit tests, 3 view models in 0 hours 0 minutes and 0.61 seconds (0.61s).and writes data successfully to DuckDB:
🟡◗ SELECT * from fct_readings LIMIT 5;
┌─────────────────────┬───────────────────────────────────────────┬────────┬──────────────┐
│ date_time │ measure_id │ value │ reading_date │
│ timestamp │ varchar │ double │ date │
├─────────────────────┼───────────────────────────────────────────┼────────┼──────────────┤
│ 2026-03-09 12:00:00 │ 52119-level-stage-i-15_min-mASD │ 0.637 │ 2026-03-09 │
│ 2026-03-09 12:00:00 │ E72639-level-tidal_level-Mean-15_min-mAOD │ 2.982 │ 2026-03-09 │
│ 2026-03-09 12:00:00 │ 730506-level-stage-i-15_min-m │ 1.319 │ 2026-03-09 │
│ 2026-03-09 12:00:00 │ 2095-level-stage-i-15_min-mASD │ 1.087 │ 2026-03-09 │
│ 2026-03-09 12:00:00 │ 3015TH-level-stage-i-15_min-mASD │ 0.178 │ 2026-03-09 │
└─────────────────────┴───────────────────────────────────────────┴────────┴──────────────┘The prompt 🔗

|
This blog post is not about testing different permutations of a prompt. I’ve done that, and have written about it separately. This blog post is looking at an approximation of the best effort I could get from Claude. There’ll always be "yes, but did you try `$thing`" and I discuss that below. |
Let’s look a bit more closely at the prompt that I gave Claude to understand what we’re giving it to work with.
I've explored and built pipelines for the UK Environment Agency flood monitoring API. Here's my analysis: (1)
- Data exploration: https://rmoff.net/2025/02/28/exploring-uk-environment-agency-data-in-duckdb-and-rill/ (2)
- Pipeline build: https://rmoff.net/2025/03/20/building-a-data-pipeline-with-duckdb/ (3)
Build a dbt project using DuckDB for this data using idiomatic patterns and good practices. Requirements: (4)
- Proper staging → dim/fact data model (5)
- Handle known data quality issues (see blog posts for details) (5)
- SCD type 2 snapshots for station metadata (5)
- Historical backfill from CSV archives (see https://environment.data.gov.uk/flood-monitoring/archive) (5)
- Documentation and tests (5)
- Source freshness checks (5)
Run `dbt build` to verify your work. If it fails, fix the errors and re-run until it passes. (6)| 1 | Background context |
| 2 | Tell Claude where to go and find out the nitty-gritty detail about the data, its relationships, and its quirks |
| 3 | Show Claude what I built myself using just SQL and no dbt |
| 4 | Lay out the requirements. |
| 5 | Skeleton spec, as one might give to a junior engineer |
| 6 | "Secret sauce". This is where agentic coding kicks in. It will literally sit there and fix its own errors. |
My yardstick for this prompt was:
What would a senior data engineer write if they were giving this to someone else to build?
That is, how much does AI help a data engineer today without them having to get into the guts of prompt engineering?
I also tested with a much more minimal prompt:
The UK Environment Agency publishes flood monitoring data,
see https://environment.data.gov.uk/flood-monitoring
Build an idiomatic dbt project following good practices using DuckDB that ingests this data and
models it for analytics.
Run the project and make sure that it works. If it fails, fix the errors and re-run until it passes.This didn’t do very well beyond the absolute basics, and I’m not covering it in the rest of this article.
Agentic coding in action 🔗
At the heart of using Claude Code rather than a "chat bot" like ChatGPT is the idea of agentic AI. That is, it understands what it needs to do, and it has access to tools to achieve it. Tools can include looking up documentation on the web, amending files, invoking binaries, and so on.
Here’s an example of it in action, debugging a problem with the project as it goes. Remember, it’s doing everything I’m showing here on its own—no input, prompting, or guidance from me.
We join Claude part-way through its journey.
It’s already built out the dbt models, and is testing it for the first time.
On its own, it invokes dbt build:
Bash cd /workspace/flood_monitoring && dbt build --profiles-dir . 2>&1
x Exit code 2
Full error output
Exit code 2
Running with dbt=1.11.7
Registered adapter: duckdb=1.10.1
Unable to do partial parsing because saved manifest not found. Starting full parse.
[WARNING][MissingArgumentsPropertyInGenericTestDeprecation]: Deprecated
functionality
Found top-level arguments to test `accepted_values` defined on 'stg_measures' in
package 'flood_monitoring' (models/staging/_staging.yml). Arguments to generic
tests should be nested under the `arguments` property.
Encountered an error:
"'dateTime'"
Traceback (most recent call last):
File "/usr/local/lib/python3.11/dist-packages/dbt/cli/requires.py", line 182, in wrapper
result, success = func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/cli/requires.py", line 128, in wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/cli/requires.py", line 276, in wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/cli/requires.py", line 321, in wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/cli/requires.py", line 391, in wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/cli/requires.py", line 368, in wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/cli/requires.py", line 407, in wrapper
setup_manifest(ctx, write=write, write_perf_info=write_perf_info)
File "/usr/local/lib/python3.11/dist-packages/dbt/cli/requires.py", line 434, in setup_manifest
ctx.obj["manifest"] = parse_manifest(
^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/parser/manifest.py", line 2257, in parse_manifest
manifest = ManifestLoader.get_full_manifest(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/parser/manifest.py", line 323, in get_full_manifest
manifest = loader.load()
^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/parser/manifest.py", line 459, in load
patcher.construct_sources()
File "/usr/local/lib/python3.11/dist-packages/dbt/parser/sources.py", line 87, in construct_sources
parsed = self.parse_source(patched)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/parser/sources.py", line 204, in parse_source
parsed_source.relation_name = self._get_relation_name(parsed_source)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/parser/sources.py", line 338, in _get_relation_name
return str(relation_cls.create_from(self.root_project, node))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/adapters/duckdb/relation.py", line 27, in create_from
return cls.create_from_source(quoting, relation_config, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/dbt/adapters/duckdb/relation.py", line 62, in create_from_source
ext_location = ext_location_template.format_map(source_config.as_dict())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyError: "'dateTime'"
[WARNING][DeprecationsSummary]: Deprecated functionality
Summary of encountered deprecations:
- MissingArgumentsPropertyInGenericTestDeprecation: 6 occurrences
To see all deprecation instances instead of just the first occurrence of each,
run command again with the `--show-all-deprecations` flag. You may also need to
run with `--no-partial-parse` as some deprecations are only encountered during
parsing.You can expand the Full error output log line above in full if you want, but the salient messages are these:
[WARNING][MissingArgumentsPropertyInGenericTestDeprecation]: Deprecated functionality Found top-level arguments to test `accepted_values` defined on 'stg_measures' in package 'flood_monitoring' (models/staging/_staging.yml). Arguments to generic tests should be nested under the `arguments` property. Encountered an error: "'dateTime'"
Claude figures out it has two problems, as you can see from its internal 'thinking':
Two errors:
1. The `accepted_values` test has the wrong format - it needs to use `arguments` property
2. The `external_location` in sources.yml is being parsed as a format string, and the `\{dateTime\}` part is being interpreted as a placeholder. I need to escape the braces. Let me fix both issues. For the `external_location`, I need to escape the curly braces in the SQL. DuckDB uses `column=\{'dateTime': 'TIMESTAMPTZ', ...\}` which has `\{` and `\}`. The dbt-duckdb source parser is trying to format this string with the source config dict. I'll escape the braces with double braces so `\{\{` becomes `\{` and `\}\}` becomes `\}` in the format string. For the `accepted_values` test, I need to restructure it so the values and severity are nested under an `arguments` property, which is the format dbt 1.11+ expects. I see the issue now—the deprecation warning about test syntax is separate from the actual error. The real problem is the `external_location` format string with the curly braces, which is causing the `KeyError`. I should prioritize fixing that first since it's what's actually breaking the code, and I can address the test syntax update separately if needed.
It summarises this up into two distinct tasks:
Two issues to fix: (1) curly braces in `external_location` need escaping for dbt's format string interpolation, and (2) test syntax deprecation. Let me fix both:
and then sets about updating the external_location references like this:
Write /workspace/flood_monitoring/models/staging/_sources.yml
[…]
meta:
# Curly braces in the DuckDB columns dict must be doubled to escape
# dbt-duckdb's format_map() interpolation.
external_location: >
read_csv(
'https://environment.data.gov.uk/flood-monitoring/archive/readings-2026-03-07.csv',
columns={{'dateTime': 'TIMESTAMPTZ', (1)
'measure': 'VARCHAR', 'value': 'VARCHAR'}}, (1)
header=true,
ignore_errors=true
)| 1 | Double curly braces |
← The file /workspace/flood_monitoring/models/staging/_sources.yml has been updated successfully.
After also updating the test syntax, it runs dbt build again:
Bash cd /workspace/flood_monitoring && dbt build --profiles-dir . 2>&1
x Exit code 2
Exit code 2
17:34:54 Running with dbt=1.11.7
17:34:54 Registered adapter: duckdb=1.10.1
17:34:54 Unable to do partial parsing because saved manifest not found. Starting full parse.
17:34:55 Encountered an error:
Compilation Error
Could not render read_csv(
'https://environment.data.gov.uk/flood-monitoring/archive/readings-2026-03-07.csv',
columns={{'dateTime': 'TIMESTAMPTZ', 'measure': 'VARCHAR', 'value': 'VARCHAR'}},
header=true,
ignore_errors=true
): expected token 'end of print statement', got ':'
line 3
columns={{'dateTime': 'TIMESTAMPTZ', 'measure': 'VARCHAR', 'value': 'VARCHAR'}},This time it’s a different problem, which it identifies and figures out how to work around:
The external_location goes through Jinja2 rendering - can’t use {{}} for literal braces. I’ll use read_csv_auto instead which needs no column type dict:
Write /workspace/flood_monitoring/models/staging/_sources.yml
Bash cd /workspace/flood_monitoring && dbt build --profiles-dir . 2>&1
This time the build works, failing only on data tests:
[…]
Done. PASS=27 WARN=2 ERROR=2 SKIP=17 NO-OP=0 TOTAL=48Good progress! The build almost works. Two real data quality issues: - 631 stations lack lat/long coordinates in the API (genuine EA data gap) - Need to downgrade those tests to `warn` severity so they don't cascade-skip downstream models
Check this out for what it does next—fires up DuckDB and starts checking the data:
python3 << 'EOF'
import duckdb
conn = duckdb.connect()
result = conn.execute("""
SELECT count(*) as missing_coords_count
FROM (
SELECT UNNEST(items) as item
FROM read_json_auto('https://environment.data.gov.uk/flood-monitoring/id/stations.json?_limit=10000')
) WHERE item.lat IS NULL
""").fetchone()
print('Missing lat/long:', result)
EOF631 stations genuinely have no coordinates in the EA API. Downgrade those tests to warn:
Edit /workspace/flood_monitoring/models/staging/_staging.yml
diff
- name: latitude
description: WGS-84 latitude in decimal degrees.
tests:
- not_null
- name: longitude
description: WGS-84 longitude in decimal degrees.
tests:
- not_null - name: latitude
description: >
WGS-84 latitude in decimal degrees. Known data quality issue: ~631
stations in the EA API have no coordinates (newly-commissioned or
administrative stations). Test is warn-only for this reason.
tests:
- not_null:
config:
severity: warn
- name: longitude
description: WGS-84 longitude in decimal degrees. See latitude note.
tests:
- not_null:
config:
severity: warnand so on and so on, until it gets to:
dbt build passes with 0 errors. All 38 tests pass; 10 warnings document known EA data quality issues.
The above autonomous debugging session is just one example of the numerous ways in which Claude Code makes things easier for a data engineer.
Here’s another narrated session log from a different run using the same prompt, in which Claude realises the data has a bunch of quirks, enumerates them, and codes for them.
Truly invaluable.
Okay…but is it any good? 🔗
As the content of many LinkedIn posts and comments is testament to: infinite AI monkeys with infinite tokens will crap out as much material as you want—but most of it is garbage. Is that what Claude is doing here? Is it garbage?
Actually, the dbt project that Claude built is pretty good.
What I love about dbt is that it makes it easy to adhere to a ton of good practices that have always been true when working with data including staging layers, slowly-changing dimensions (SCD), and dimensional modelling as well as "newer" (but equally important) concepts such as documentation (gasp!), testing (imagine!) and a smooth integration with source control and CI/CD (how modern!).
How much of these good features did Claude use, and use successfully?
Not bad… 🔗

-
✅ Plausible data model

-
✅ Correct key relationships enforced with dbt constraints
config: contract: enforced: true columns: - name: station_id data_type: varchar description: "Unique station identifier (e.g. '1029TH')" tests: - not_null - uniqueOne point to note is that it didn’t include tests to check the keys in the loaded data. This is arguably 'belt and braces' anyway.
-
✅ Incremental fact table load
config( materialized='incremental', unique_key=['date_time', 'measure_id'], ) -
✅ Handle messy source data (e.g. multiple values where only one expected)
-- Value cleaning: handle pipe-delimited values (e.g. "0.770|0.688") -- by taking the first value, then cast to double try_cast( case when value like '%|%' then split_part(value, '|', 1) else value end as double ) as reading_value, -
✅ Handles Slowly Changing Dimensions (SCD)
from {{ ref('snap_stations') }} where dbt_valid_to is nullFor some reasonClaude only implemented this for the stations dimension, not measures. Turns out, I literally told it to do this in the prompt! (SCD type 2 snapshots for station metadata). So it stuck to that literally, omitting measures. But it’d have been nice for it to perhaps challenge me on that. Measure definitions shouldn’t change…but they might? -
✅ Documentation
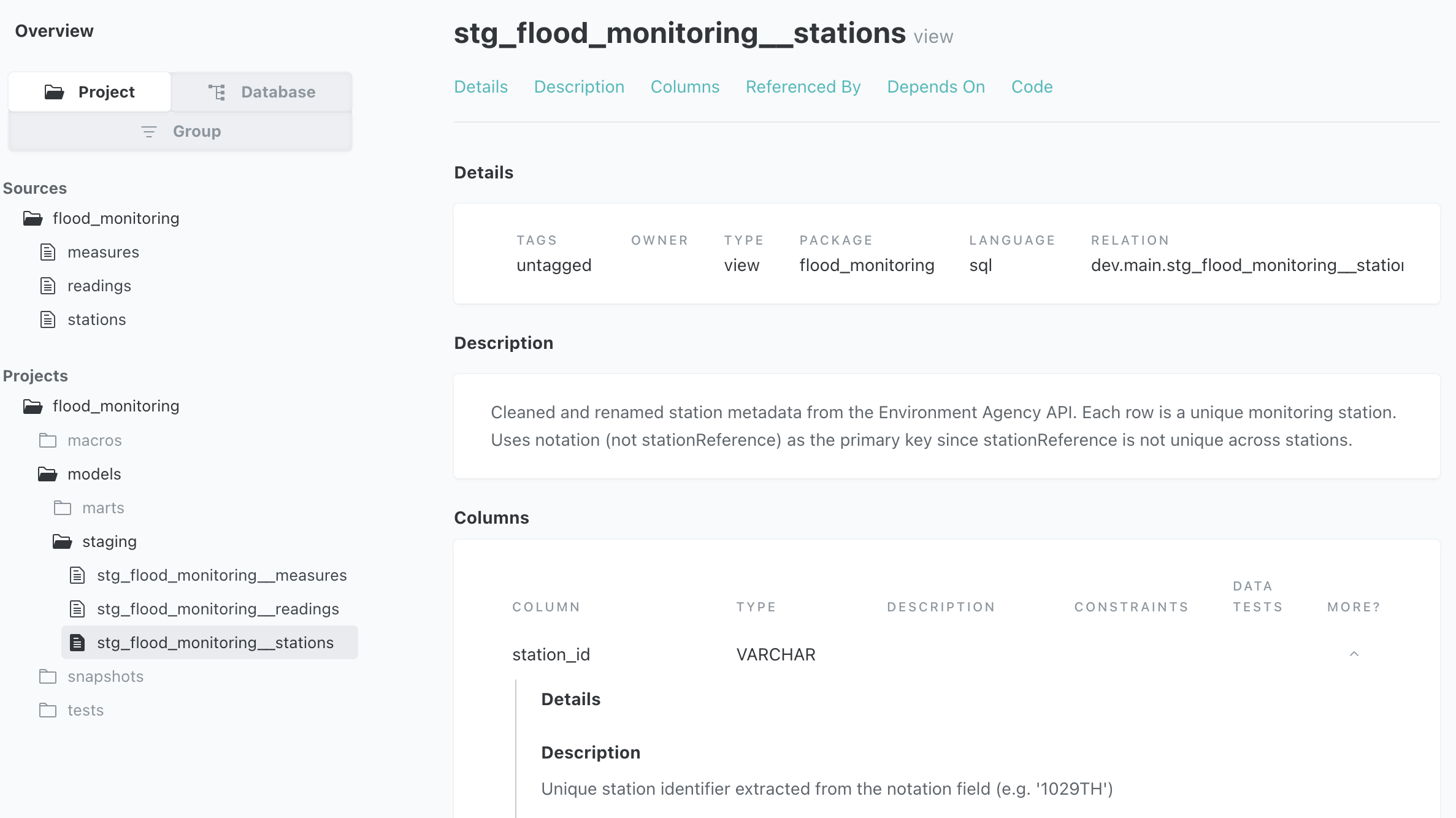
-
✅ Tests
- name: status tests: - not_null - accepted_values: arguments: values: ['Active', 'Closed', 'Suspended', 'ukcmf', 'Unknown']- name: flood_monitoring_api freshness: warn_after: count: 1 period: hour error_after: count: 6 period: hour loaded_at_field: "loaded_at" -
✅ Backfill
{% macro generate_archive_urls(start_date, end_date) %} {%- set start = modules.datetime.datetime.strptime(start_date, '%Y-%m-%d') -%} {%- set end_dt = modules.datetime.datetime.strptime(end_date, '%Y-%m-%d') -%} {%- set day_count = (end_dt - start).days -%} {%- set ns = namespace(urls=[]) -%} {%- for i in range(day_count + 1) -%} {%- set d = start + modules.datetime.timedelta(days=i) -%} {%- do ns.urls.append("'https://environment.data.gov.uk/flood-monitoring/archive/readings-" ~ d.strftime('%Y-%m-%d') ~ ".csv'") -%} {%- endfor -%} [{{ ns.urls | join(', ') }}] {%- endmacro %}select cast("dateTime" as timestamp) as date_time, regexp_replace(coalesce(measure, ''), '.+/', '') as measure_id, try_cast(split_part(cast(value as varchar), '|', 1) as double) as value from read_csv( {{ generate_archive_urls(start_date, end_date) }} -
General good practice and nice surprises
-
✅ Doesn’t use
SELECT *but instead hardcodes column names. Generally a better pattern for creating less brittle pipelines. -
✅ Parses out the station
statusfield cleanlyregexp_replace(coalesce(status, ''), '.+/', '') as statusRather than storing the source which looks like this
http://environment.data.gov.uk/flood-monitoring/def/core/statusActive -
✅ More elegant date logic:
extract(isodow from date_day) in (6, 7) as is_weekendvs
CAST(CASE WHEN dayofweek(range) IN (0,6) THEN 1 ELSE 0 END AS BOOLEAN) AS date_is_weekend
-
So, pretty solid work, if the alternative is starting from a blank slate of a dbt project. What about the downsides?
…but not that good 🔗
All you Claude Code fans out there, hold your horses on the "yes, but…" until the "yes, but" section below :p
In the version that I built by hand, I pull the raw API data into a DuckDB table using a Jinja macro.
Claude approached it differently, writing a Python script, load_api_data.py.
Arguably more elegant, but I have three issues with it, as follows.
-
The first of these is personal preference. I’m a SQL guy, and I’d rather not be on the hook to support a pipeline that leans on Python. After all, it’s one thing to generate code with AI, but ultimately someone’s left holding the support baby.
-
The next two issues are the code itself. There’s one silly flaw in it, and an insidiously bad one.
-
The silly flaw is easily spotted and easily fixed: it only does a
CREATE TABLEand so falls over if the table exists already (like, the second time you run it). Easily spotted (the job falls over) and easily fixed (CREATE OR REPLACE TABLE). -
The really bad problem is this, in Claude’s own mea culpa words:
load_api_data.pyfetches stations with?_limit=2000, but the API itself has a maximum response size of 2000 items (it silently caps at that). The actual total number of stations is ~5,458, so the script only gets 1,493 rows back (fewer than the limit because the API returns a paginated subset — probably the first page).Let that sink in. We have a huge hole in our data, that’s not evident until we wonder why a ton of our facts are without corresponding dimension entries.

-
|
Wrong is worse than absent because you can’t trust it.
If Claude just doesn’t build a feature, that’s ok because I can add it (or tell it to). But if it confidently builds it and it turns out to be wrong, that’s a trust issue. |
Yes, but Robin, you could <do this thing>! → See yes, but below
Other things that look off from just eyeballing the code include:
-
dim_stationsdrops several columns (stageScale,datumOffset,gridReference,downstageScale). Two of these arguably extend the data model beyond what I’ve manually investigated myself before (stageScale/downstageScale) but two definitely hold relevant reference data (datumOffset,gridReference) which is getting silently dropped. -
dim_measuresdropsunit. Arguably a decent optimisation given the repetition betweenunitand the human-friendlyunitName:🟡◗ select unit, unitName,label, parameter,parameterName,valueType from measures using sample 5 rows;┌──────────────────────────────────────┬──────────┬──────────────────────────────────────────────┬───────────┬───────────────┬───────────────┐ │ unit │ unitName │ label │ parameter │ parameterName │ valueType │ │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ ├──────────────────────────────────────┼──────────┼──────────────────────────────────────────────┼───────────┼───────────────┼───────────────┤ │ http://qudt.org/1.1/vocab/unit#Meter │ m │ LAVERSTOCK - level-stage-i-15_min-m │ level │ Water Level │ instantaneous │ │ http://qudt.org/1.1/vocab/unit#Meter │ m │ KNETTISHALL GS GSM - level-stage-i-15_min-m │ level │ Water Level │ instantaneous │ │ http://qudt.org/1.1/vocab/unit#Meter │ mASD │ Keadby TL B - level-tidal_level-i-5_min-mASD │ level │ Water Level │ instantaneous │ │ http://qudt.org/1.1/vocab/unit#Meter │ m │ Riding Mill - level-stage-i-15_min-m │ level │ Water Level │ instantaneous │ │ http://qudt.org/1.1/vocab/unit#Meter │ mASD │ Clomoney Way LVL - level-stage-i-15_min-mASD │ level │ Water Level │ instantaneous │ └──────────────────────────────────────┴──────────┴──────────────────────────────────────────────┴───────────┴───────────────┴───────────────┘But that’s not the point is it; silently dropping data fields is not what I want my robot to do.
-
fct_readingsduplicates thedate_timefield:select date_time, measure_id, value, cast(date_time as date) as reading_date (1) from deduped1 y, tho? -
Claude builds the SCD (nice!) but
check_colsonly lists some of the values that might change:check_cols=[ 'station_name', 'town', 'river_name', 'catchment_name', 'latitude', 'longitude', 'status', ],So if
latitude/longitudeare in there, why notnorthing/easting? As with themeasuresdecisions above, these are real data issues that a human should be involved in reviewing, or the AI surfacing for review.
Yes, but… 🔗
All of the mistakes and errors that Claude made and which I discuss above, I could, of course, get Claude to fix. This would be an iterative process: Claude builds → I review → Claude fixes, etc.
But…that isn’t what I wanted to determine in this article. It changes Claude from a means of production into a means of assistance (which is, BTW, what I conclude in this post that its most effective role is today). It’s the difference between giving a junior (or senior!) colleague a piece of work to do and being confident that it will be ready for testing, versus knowing that it will need a lot of checking and reworking.
Another option would be to build the prompt defensively up-front (encode everything I’ve seen it do here into a better prompt for next time, make no mistakes, etc).
The point remains, that I would have had to do that.
The prompt I already gave it was designed to give it enough hints, without having to hold its hand through every step.
Could I create an improved version, based on what it’s learnt? Sure. But that’s not having Claude build it for me is it. It’s building it with me. Which is my whole argument here.
| Claude Code is an amazing productivity companion. |
| Do not, if you value your job, use it to one-shot a dbt project! |
Prompt tweaking is a mug’s game 🔗
LLMs are non-deterministic, so even given the same prompt it might behave differently next time, let alone when a newer model comes along. Then you end up building a spaghetti bowl of sticking plasters ("don’t do this", "remember to do this"), and it’s still not necessarily going to do it right each time—as the technology currently stands.
I’m reminded of this example of a ChatGPT prompt I earnestly bookmarked in August 2023. It was the magic incantation! It was amazing! It was cargo culting.
Relying on prompting alone is cute for tricks, but it’s not a viable strategy for reliable hands-off dbt code generation (or even hands-on, but trusted, for that matter).
How did you test this? Did you try technique $wibble? What about model $foo? 🔗
The best thing about using AI agents to make you more productive is that they make you more productive at the thing you’re building.
The worst thing about using AI agents to make you more productive is that they make you more productive at any random stupid idea that pops into your lizard brain.
Thus, in figuring out what Claude Code could do with dbt, I also stumbled into the worlds of evals, LLM-as-judge, and a whole bunch more. Oh, and of course, having Claude Code build a bespoke dashboard to track all of my results :)
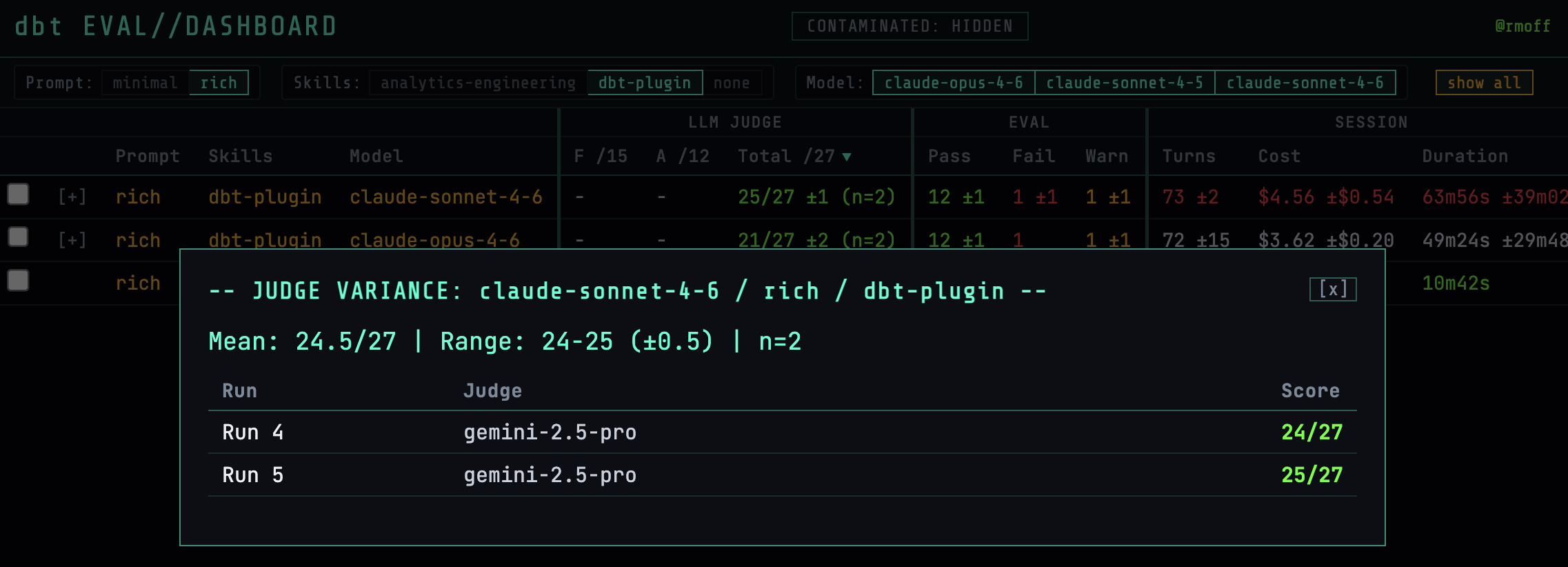
I’ve written all about this in a separate blog post, because I learnt a lot of stuff—some of it useful too.
For now, the headline:
|
The prompt and the skills matter more than the model. Sonnet 4.5 can produce respectable results given the necessary context. Opus 4.6 isn’t a silver bullet.
|

A fantastic productivity booster for data engineers 🔗
What does even replacing a data engineer with AI mean? 🔗
To truly suggest that AI can replace a data engineer you’d be talking about a tool that a business user could tell to build a pipeline and have it do it with sufficient quality and robustness that it could be thrown over the wall to a general IT ops team to run.
Perhaps in the same way that business users these days eat Excel sheets for breakfast whereas 40 years ago they’d have a specialist in IT to do that for them.
We’re not there with AI yet.
DE + AI > DE 🔗
What agentic coding tools such as Claude Code are doing is making data engineers vastly more productive. We saw above that it’s not going to build the whole pipeline in one go, hands-off. And in fact, there are chances it’s going to be a drag on productivity to do so because you won’t have built up the mental map of what’s been built to then be able to verify and troubleshoot it. But Claude Code excels at specific tasks, and iteration. It can troubleshoot a failing build, as well as figure out nuances in the data.
Whilst it does need coaching through some tasks, and reprimanding and correcting, and whilst it does make mistakes…so do humans! My experience is that it is so shit-hot—and fast as f…errari—the vast majority of the time that the nett gain over just doing it yourself manually is still great.
My mental model for not using Claude Code is currently something like this:
Deterministic vs non-deterministic is irrelevant here; my point is that AI is a tool to enable you to get something done more easily than you used to be able to. |
You don’t have to use agentic coding tools…but you’re going to get left behind and have to catch up at some point.
| Oh…and if you honestly think AI is just ChatGPT writing haikus about Linux and other chatbot-esque simplicity…you’re maybe missing the point about AI. |