
Iceberg nicely decouples storage from ingest and query (yay!). When we say "decouples" it’s a fancy way of saying "doesn’t do". Which, in the case of ingest and query, is really powerful. It means that we can store data in an open format, populated by one or more tools, and queried by the same, or other tools. Iceberg gets to be very opinionated and optimised around what it was built for (storing tabular data in a flexible way that can be efficiently queried). This is amazing!
But, what Iceberg doesn’t do is any housekeeping on its data and metadata. This means that getting data in and out of Apache Iceberg isn’t where the story stops.
You can provision your object storage, choose a metadata catalog, and chuck an engine on it all (like Flink, Trino, or Spark). But you still need to think about the files that Iceberg is writing. Because under the covers of your Iceberg table is this:
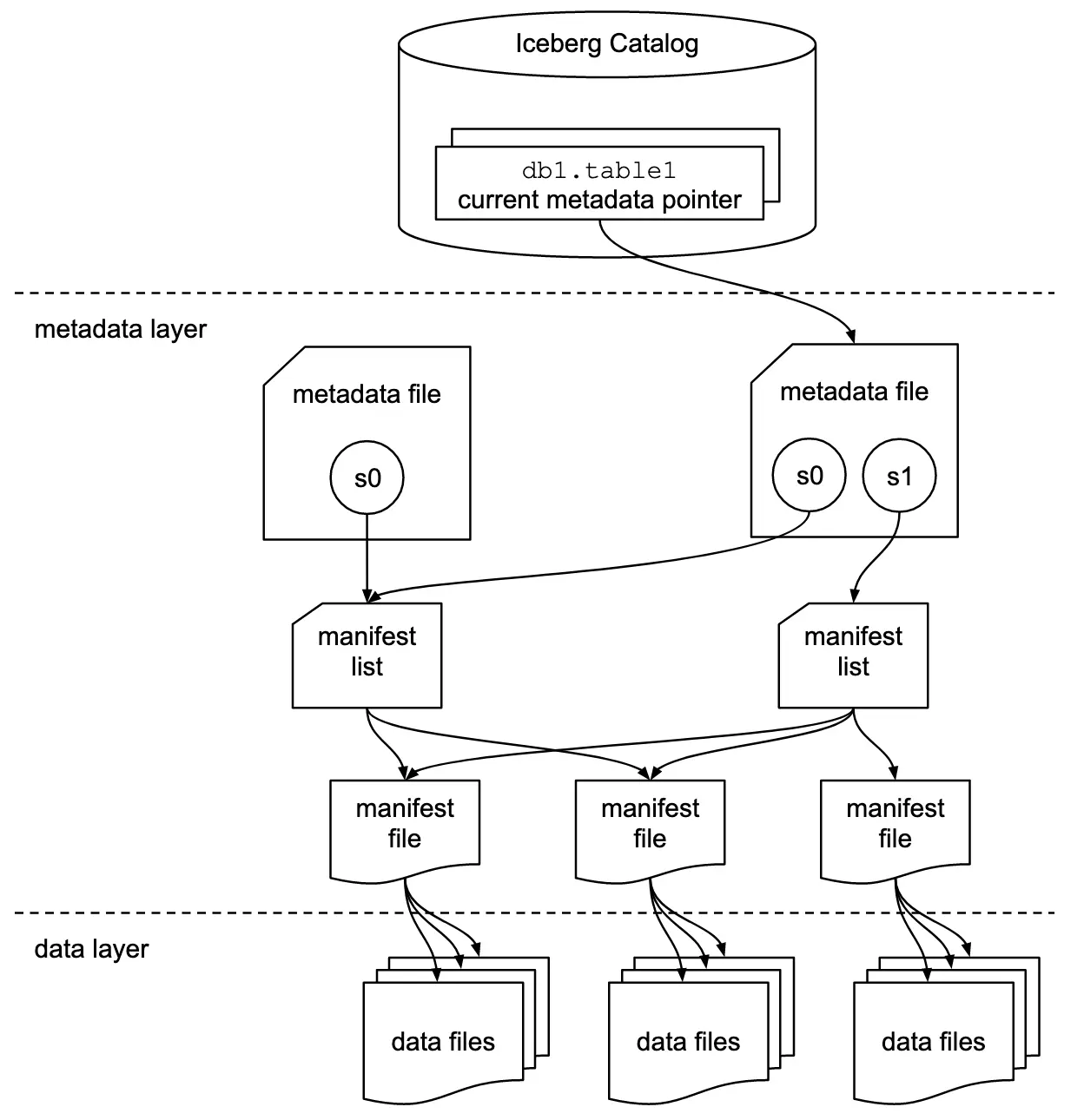
Let’s take a step back and look at what happens when you write some data to Iceberg.
Do try this at home! 🔗
What happens when you write data to Iceberg? 🔗
ℹ️ For more in-depth notes on this subject, check out Alex Merced’s article.
When you first create a table:
CREATE TABLE
IF NOT EXISTS customers (
customer_id BIGINT,
first_name VARCHAR(255),
last_name VARCHAR(255),
email VARCHAR(255)
);Iceberg writes a single metadata file holding details including the table’s location and its schema:
metadata/00000-69666f0f-2902-49ae-a717-0d8eb81c4825.metadata.json (click to expand)
{
"format-version": 2,
"table-uuid": "ee794fd1-2144-42ce-a9f3-e3807ec4c054",
"location": "s3://warehouse/rmoff/customers",
"last-sequence-number": 0,
"last-updated-ms": 1752247098598,
"last-column-id": 4,
"current-schema-id": 0,
"schemas": [
{
"type": "struct",
"schema-id": 0,
"fields": [
{
"id": 1,
"name": "customer_id",
"required": false,
"type": "long"
},
{
"id": 2,
"name": "first_name",
"required": false,
"type": "string"
},
{
"id": 3,
"name": "last_name",
"required": false,
"type": "string"
},
{
"id": 4,
"name": "email",
"required": false,
"type": "string"
}
]
}
],
"default-spec-id": 0,
"partition-specs": [
{
"spec-id": 0,
"fields": []
}
],
"last-partition-id": 999,
"default-sort-order-id": 0,
"sort-orders": [
{
"order-id": 0,
"fields": []
}
],
"properties": {
"owner": "root",
"created-at": "2025-07-11T15:18:18.570926252Z",
"write.parquet.compression-codec": "zstd"
},
"current-snapshot-id": -1,
"refs": {},
"snapshots": [],
"statistics": [],
"partition-statistics": [],
"snapshot-log": [],
"metadata-log": []
}Other than that, there’s nothing else written at this point. Now let’s write one row of data:
INSERT INTO customers (customer_id, first_name, last_name, email)
VALUES (1, 'Rey', 'Skywalker', 'rey@rebelscum.org');This causes several more files to be written by Iceberg, both /data and /metadata:
$ mc ls -r minio/warehouse/rmoff/customers/
[…] data/00000-0-e3b7a202-2481-4d9f-9b7c-9830908a425a-0-00001.parquet (1)
[…] metadata/00000-69666f0f-2902-49ae-a717-0d8eb81c4825.metadata.json (2)
[…] metadata/00001-d35fd98b-8761-4998-bd74-9677c9929e63.metadata.json (3)
[…] metadata/ab613eb0-2f90-4273-869e-ee6d1425ab9a-m0.avro (4)
[…] metadata/snap-653583197990088094-1-ab613eb0-2f90-4273-869e-ee6d1425ab9a.avro (5)| 1 | The row of data that I just wrote |
| 2 | Metadata (v00000, original, as shown above) |
| 3 | Metadata (v00001, new) |
| 4 | Manifest list |
| 5 | Manifest file |
The v00001 metadata file is similar to the first, except that it now includes snapshot details:
Extract from metadata/00001-d35fd98b-8761-4998-bd74-9677c9929e63.metadata.json
[…]
"current-snapshot-id": 653583197990088094,
"refs": {
"main": {
"snapshot-id": 653583197990088094,
"type": "branch"
}
},
"snapshots": [
{
"sequence-number": 1,
"snapshot-id": 653583197990088094,
"timestamp-ms": 1752247268656,
"summary": {
"operation": "append",
"spark.app.id": "local-1752247081867",
"added-data-files": "1",
"added-records": "1",
"added-files-size": "1367",
"changed-partition-count": "1",
"total-records": "1",
"total-files-size": "1367",
"total-data-files": "1",
"total-delete-files": "0",
"total-position-deletes": "0",
"total-equality-deletes": "0",
"engine-version": "3.5.5",
"app-id": "local-1752247081867",
"engine-name": "spark",
"iceberg-version": "Apache Iceberg 1.8.1 (commit 9ce0fcf0af7becf25ad9fc996c3bad2afdcfd33d)"
},
"manifest-list": "s3://warehouse/rmoff/customers/metadata/snap-653583197990088094-1-ab613eb0-2f90-4273-869e-ee6d1425ab9a.avro",
"schema-id": 0
}
],
"statistics": [],
"partition-statistics": [],
"snapshot-log": [
{
"timestamp-ms": 1752247268656,
"snapshot-id": 653583197990088094
}
],
"metadata-log": [
{
"timestamp-ms": 1752247098598,
"metadata-file": "s3://warehouse/rmoff/customers/metadata/00000-69666f0f-2902-49ae-a717-0d8eb81c4825.metadata.json"
}
]
[…]In the snapshot data is referenced a manifest list:
metadata/snap-653583197990088094-1-ab613eb0-2f90-4273-869e-ee6d1425ab9a.avro (converted to JSON)
{
"manifest_path": "s3://warehouse/rmoff/customers/metadata/ab613eb0-2f90-4273-869e-ee6d1425ab9a-m0.avro",
"manifest_length": 7192,
"partition_spec_id": 0,
"content": 0,
"sequence_number": 1,
"min_sequence_number": 1,
"added_snapshot_id": 653583197990088094,
"added_files_count": 1,
"existing_files_count": 0,
"deleted_files_count": 0,
"added_rows_count": 1,
"existing_rows_count": 0,
"deleted_rows_count": 0,
"partitions": {
"array": []
},
"key_metadata": null
}This in turn references a Manifest file:
metadata/ab613eb0-2f90-4273-869e-ee6d1425ab9a-m0.avro
{
"status": 1,
"snapshot_id": {
"long": 653583197990088094
},
"sequence_number": null,
"file_sequence_number": null,
"data_file": {
"content": 0,
"file_path": "s3://warehouse/rmoff/customers/data/00000-0-e3b7a202-2481-4d9f-9b7c-9830908a425a-0-00001.parquet",
"file_format": "PARQUET",
"partition": {},
"record_count": 1,
"file_size_in_bytes": 1367,
"column_sizes": {
"array": [
{
"key": 1,
"value": 43
},
{
"key": 2,
"value": 42
},
{
"key": 3,
"value": 48
},
{
"key": 4,
"value": 56
}
]
},
"value_counts": {
"array": [
{
"key": 1,
"value": 1
},
{
"key": 2,
"value": 1
},
{
"key": 3,
"value": 1
},
{
"key": 4,
"value": 1
}
]
},
"null_value_counts": {
"array": [
{
"key": 1,
"value": 0
},
{
"key": 2,
"value": 0
},
{
"key": 3,
"value": 0
},
{
"key": 4,
"value": 0
}
]
},
"nan_value_counts": {
"array": []
},
"lower_bounds": {
"array": [
{
"key": 1,
"value": "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 2,
"value": "Rey"
},
{
"key": 3,
"value": "Skywalker"
},
{
"key": 4,
"value": "rey@rebelscum.or"
}
]
},
"upper_bounds": {
"array": [
{
"key": 1,
"value": "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 2,
"value": "Rey"
},
{
"key": 3,
"value": "Skywalker"
},
{
"key": 4,
"value": "rey@rebelscum.os"
}
]
},
"key_metadata": null,
"split_offsets": {
"array": [
4
]
},
"equality_ids": null,
"sort_order_id": {
"int": 0
},
"referenced_data_file": null
}
}As you can see from the Manifest file, this points to the data file that was written, and holds some basic statistics about the data such as upper and lower bound values of each column.
Data about the metadata 🔗

Instead of poking around in object store buckets, we can get a good view of what’s happening beneath the surface of an Iceberg table using the system tables that expose this metadata.
How you access these tables depends on your query engine for Iceberg.
Trino uses a $ separator (mytable$snapshots) whilst Spark uses qualifier suffix (catalog.db.table.snapshots).
Here is the above metadata, seen through the tables in Spark:
-
metadata_log_entries:SELECT * from polaris.rmoff.customers.metadata_log_entries;timestamp file latest_snapshot_id latest_schema_id latest_sequence_number 2025-07-11 15:18:18.598000
s3://warehouse/rmoff/customers/metadata/00000-69666f0f-2902-49ae-a717-0d8eb81c4825.metadata.json
None
None
None
2025-07-11 15:21:08.656000
s3://warehouse/rmoff/customers/metadata/00001-d35fd98b-8761-4998-bd74-9677c9929e63.metadata.json
653583197990088094
0
1
-
manifests:SELECT * from polaris.rmoff.customers.manifests;content path length partition_spec_id added_snapshot_id added_data_files_count existing_data_files_count deleted_data_files_count added_delete_files_count existing_delete_files_count deleted_delete_files_count partition_summaries 0
s3://warehouse/rmoff/customers/metadata/ab613eb0-2f90-4273-869e-ee6d1425ab9a-m0.avro
7192
0
653583197990088094
1
0
0
0
0
0
[]
-
snapshotsSELECT * from polaris.rmoff.customers.snapshots;committed_at snapshot_id parent_id operation manifest_list summary 2025-07-11 15:21:08.656000
653583197990088094
None
append
s3://warehouse/rmoff/customers/metadata/snap-653583197990088094-1-ab613eb0-2f90-4273-869e-ee6d1425ab9a.avro
\{'engine-version': '3.5.5', 'added-data-files': '1', 'total-equality-deletes': '0', 'app-id': 'local-1752247081867', 'added-records': '1', 'total-records': '1', 'spark.app.id': 'local-1752247081867', 'changed-partition-count': '1', 'engine-name': 'spark', 'total-position-deletes': '0', 'added-files-size': '1367', 'total-delete-files': '0', 'iceberg-version': 'Apache Iceberg 1.8.1 (commit 9ce0fcf0af7becf25ad9fc996c3bad2afdcfd33d)', 'total-files-size': '1367', 'total-data-files': '1'}
-
Plus the data file itself for a table, in
files:SELECT file_path, record_count, file_size_in_bytes FROM polaris.rmoff.customers.files;file_path
record_count
file_size_in_bytes
s3://warehouse/rmoff/customers/data/00000-0-e3b7a202-2481-4d9f-9b7c-9830908a425a-0-00001.parquet
1
1367
Why all these files? 🔗
After a few more changes to the data on the table, what started off as five files in the bucket is now ten times that:
$ docker compose exec minio-client mc ls -r minio/warehouse/rmoff/customers
[…] data/00000-0-e3b7a202-2481-4d9f-9b7c-9830908a425a-0-00001.parquet
[…] data/00000-10-e314c682-0973-4851-a1d3-02ec2ff474d3-0-00001.parquet
[…] data/00000-11-9cc47f12-f4f9-4db0-a942-2dd67cd3b1ba-0-00001.parquet
[…] data/00000-12-1d30b129-68e1-4860-a4f5-f996916125d4-0-00001.parquet
[…] data/00000-13-fa0ef50e-e976-41dc-8335-dd67568ed81e-0-00001.parquet
[…] data/00000-14-3b349ccd-1cb1-467b-b0cd-68d98d081c62-0-00001.parquet
[…] data/00000-22-613312a3-36fa-4714-8088-217bfce711b5-0-00001.parquet
[…] data/00000-24-e0fd0048-a3c1-4acc-bac5-cbe1df00d5a0-0-00001.parquet
[…] data/00000-8-b2dad931-1680-499f-894f-2d853aa523f9-0-00001.parquet
[…] data/00000-9-8527fa9b-5d74-4edc-8620-d9a4cf73f6f4-0-00001.parquet
[…] metadata/00000-69666f0f-2902-49ae-a717-0d8eb81c4825.metadata.json
[…] metadata/00001-d35fd98b-8761-4998-bd74-9677c9929e63.metadata.json
[…] metadata/00002-9b2338d4-020e-4a9f-83cc-214c567a04e4.metadata.json
[…] metadata/00003-4dab419f-a92a-448c-b594-4c41a150c16a.metadata.json
[…] metadata/00004-dc4755fc-aecd-468c-bc1a-5475ad56b376.metadata.json
[…] metadata/00005-2e94a329-5463-44b0-bfc5-d7a70932ca54.metadata.json
[…] metadata/00006-743f8acd-b533-4f15-868a-8c8cb6531e98.metadata.json
[…] metadata/00007-f4e31526-9a63-4709-833c-2aeee0b070a3.metadata.json
[…] metadata/00008-5e69c6e7-afd0-4c76-86ef-502b6e684d5f.metadata.json
[…] metadata/00009-475e53be-14d1-4692-ba63-b736ee3289e7.metadata.json
[…] metadata/00010-99acda0d-dd1d-429e-b1a1-2d61f9ad5e0d.metadata.json
[…] metadata/00011-99c4c0cc-3454-433f-a5a2-7c3ae496e7d5.metadata.json
[…] metadata/00012-1a421573-e57e-4d12-b112-b4b226cdc939.metadata.json
[…] metadata/228ccff5-47ff-4253-94e9-eca15e40fac3-m0.avro
[…] metadata/44a08557-5c09-45af-979c-a3f6bd20f73f-m0.avro
[…] metadata/4a03f20d-a439-4f31-a903-7f3c6460918c-m0.avro
[…] metadata/7d48f2bc-3284-406d-ade6-a4acb3a449bf-m0.avro
[…] metadata/822c7500-d614-4362-9771-5a4d85fc8637-m0.avro
[…] metadata/ab613eb0-2f90-4273-869e-ee6d1425ab9a-m0.avro
[…] metadata/adaa1024-c57f-4d40-a77c-f90ae7657691-m0.avro
[…] metadata/adaa1024-c57f-4d40-a77c-f90ae7657691-m1.avro
[…] metadata/adaa1024-c57f-4d40-a77c-f90ae7657691-m2.avro
[…] metadata/adaa1024-c57f-4d40-a77c-f90ae7657691-m3.avro
[…] metadata/adaa1024-c57f-4d40-a77c-f90ae7657691-m4.avro
[…] metadata/adaa1024-c57f-4d40-a77c-f90ae7657691-m5.avro
[…] metadata/adaa1024-c57f-4d40-a77c-f90ae7657691-m6.avro
[…] metadata/adaa1024-c57f-4d40-a77c-f90ae7657691-m7.avro
[…] metadata/bed8d569-0d51-49b8-ab45-90506fa8e225-m0.avro
[…] metadata/c7835d36-f795-4972-b596-47207e01c4b3-m0.avro
[…] metadata/d4c87db9-87f4-4a0c-86be-22b280415213-m0.avro
[…] metadata/e06e486c-1679-4b8c-807e-f97771d2098e-m0.avro
[…] metadata/snap-3955300550128988035-1-adaa1024-c57f-4d40-a77c-f90ae7657691.avro
[…] metadata/snap-4323972595265181943-1-d4c87db9-87f4-4a0c-86be-22b280415213.avro
[…] metadata/snap-6183377644092012057-1-c7835d36-f795-4972-b596-47207e01c4b3.avro
[…] metadata/snap-653583197990088094-1-ab613eb0-2f90-4273-869e-ee6d1425ab9a.avro
[…] metadata/snap-6908561599456501560-1-4a03f20d-a439-4f31-a903-7f3c6460918c.avro
[…] metadata/snap-707189909035517389-1-e06e486c-1679-4b8c-807e-f97771d2098e.avro
[…] metadata/snap-7224052145290180020-1-228ccff5-47ff-4253-94e9-eca15e40fac3.avro
[…] metadata/snap-7609541883410176846-1-44a08557-5c09-45af-979c-a3f6bd20f73f.avro
[…] metadata/snap-8234548320069527226-1-bed8d569-0d51-49b8-ab45-90506fa8e225.avro
[…] metadata/snap-8447691896096706468-1-822c7500-d614-4362-9771-5a4d85fc8637.avro
[…] metadata/snap-8687338518067749463-1-7d48f2bc-3284-406d-ade6-a4acb3a449bf.avroThis is a by-product of how Iceberg provides its rich functionality. Iceberg has been designed and built so that it supports features such as branching, schema evolution, partitioning, and time travel.
Time travel in Iceberg 🔗
For example, I can query the table’s state as it was half an hour ago. In this case, Iceberg uses these files to reconstruct the data and schema of a table at a given time.
SELECT * FROM customers TIMESTAMP AS OF (NOW() - INTERVAL 30 MINUTES);| customer_id | first_name | last_name | |
|---|---|---|---|
2 |
Hermione |
Granger |
|
1 |
Rey |
Skywalker |
Time travel in Iceberg is based around the concept of snapshots. We can look up the snapshot that was current at the point in time we’re querying (30 minutes ago, in this example):
SELECT manifest_list, snapshot_id from polaris.rmoff.customers.snapshots
WHERE committed_at > NOW() - INTERVAL 30 MINUTES
ORDER BY committed_at ASC LIMIT 1| manifest_list | snapshot_id |
|---|---|
s3://warehouse/rmoff/customers/metadata/snap-707189909035517389-1-e06e486c-1679-4b8c-807e-f97771d2098e.avro |
707189909035517389 |
The manifest list for this snapshot holds the following:
{
"manifest_path": "s3://warehouse/rmoff/customers/metadata/e06e486c-1679-4b8c-807e-f97771d2098e-m0.avro",
"manifest_length": 7194,
"partition_spec_id": 0,
"content": 0,
"sequence_number": 2,
"min_sequence_number": 2,
"added_snapshot_id": 707189909035517389,
"added_files_count": 1,
"existing_files_count": 0,
"deleted_files_count": 0,
"added_rows_count": 1,
"existing_rows_count": 0,
"deleted_rows_count": 0,
"partitions": {
"array": []
},
"key_metadata": null
}
{
"manifest_path": "s3://warehouse/rmoff/customers/metadata/ab613eb0-2f90-4273-869e-ee6d1425ab9a-m0.avro",
"manifest_length": 7192,
"partition_spec_id": 0,
"content": 0,
"sequence_number": 1,
"min_sequence_number": 1,
"added_snapshot_id": 653583197990088094,
"added_files_count": 1,
"existing_files_count": 0,
"deleted_files_count": 0,
"added_rows_count": 1,
"existing_rows_count": 0,
"deleted_rows_count": 0,
"partitions": {
"array": []
},
"key_metadata": null
}The two referenced manifest files contain pointers to the data files:
e06e486c-1679-4b8c-807e-f97771d2098e-m0.avro{
"status": 1,
"snapshot_id": {
"long": 707189909035517389
},
"sequence_number": null,
"file_sequence_number": null,
"data_file": {
"content": 0,
"file_path": "s3://warehouse/rmoff/customers/data/00000-8-b2dad931-1680-499f-894f-2d853aa523f9-0-00001.parquet",
[…]ab613eb0-2f90-4273-869e-ee6d1425ab9a-m0.avro{
"status": 1,
"snapshot_id": {
"long": 653583197990088094
},
"sequence_number": null,
"file_sequence_number": null,
"data_file": {
"content": 0,
"file_path": "s3://warehouse/rmoff/customers/data/00000-0-e3b7a202-2481-4d9f-9b7c-9830908a425a-0-00001.parquet",and then the data files:
00000-0-e3b7a202-2481-4d9f-9b7c-9830908a425a-0-00001.parquet┌─────────────┬────────────┬───────────┬───────────────────┐
│ customer_id │ first_name │ last_name │ email │
│ int64 │ varchar │ varchar │ varchar │
├─────────────┼────────────┼───────────┼───────────────────┤
│ 1 │ Rey │ Skywalker │ rey@rebelscum.org │
└─────────────┴────────────┴───────────┴───────────────────┘00000-8-b2dad931-1680-499f-894f-2d853aa523f9-0-00001.parquet┌─────────────┬────────────┬───────────┬──────────────────────────┐
│ customer_id │ first_name │ last_name │ email │
│ int64 │ varchar │ varchar │ varchar │
├─────────────┼────────────┼───────────┼──────────────────────────┤
│ 2 │ Hermione │ Granger │ leviosaaaaa@hogwarts.edu │
└─────────────┴────────────┴───────────┴──────────────────────────┘These two rows of data match what is shown in the TIMESTAMP AS OF time travel query above.
Ctrl-Z for your data lakehouse 🔗
Since Iceberg builds these layers of data and metadata for a table over time, it means that you can also rollback the table to one of its former states. To do this Iceberg simply changes the pointer of the current snapshot to a previous one.
Both Spark and Trino provide rollback_to_snapshot.
The joy of open standards is that even if you’re using an engine for your Iceberg work that has not implemented this feature, you can just use one that has for this operation alone, and then go back to your other one as normal.
-- uh oh, someone forgot a predicate
DELETE FROM customers;CALL polaris.system.rollback_to_snapshot('rmoff.customers', 707189909035517389);SELECT * FROM customers; customer_id | first_name | last_name | email | phone
-------------+------------+-----------+--------------------------+-------
1 | Rey | Skywalker | rey@rebelscum.org | NULL
2 | Hermione | Granger | leviosaaaaa@hogwarts.edu | NULLSo…doesn’t this get messy? 🔗
Well, yes. Particularly if you think that typically for every commit to Iceberg, a new data file is written. That data file could be thousands of records; it could also be one.
|
If the source of your data coming into Iceberg is a streaming platform (such as Kafka Connect) then it’s more likely you could end up with smaller files if the volume of ingest is much lower than the rate. That is to say, if you want to be able to read the data sooner, you’ll set the commit period shorter. But the tradeoff of a shorter commit time is that you’re going to end up with lots of smaller data files, unless you have large volumes of data coming in during that period. |
We can look at the metadata about the files and compare the number of data files to the record_count across them all:
trino:rmoff> SELECT COUNT(*) AS data_file_ct, SUM(record_count) AS record_ct
FROM "customers$files";
data_file_ct | record_ct
--------------+-----------
1 | 3
(1 row)This means that the table has one data file, holding three records.
If I run five separate INSERT s, each of one row, we’ll find we end up adding five data files, for just five records
trino:rmoff> SELECT COUNT(*) AS data_file_ct, SUM(record_count) AS record_ct FROM "customers$files";
data_file_ct | record_ct
--------------+-----------
6 | 8
(1 row)These small files can cause challenges in several aspects, including:
-
Performance overhead of metadata management
-
Object store access request costs (more files == more requests)
To address these problems Iceberg has several housekeeping functions.
As with the rollback procedure above, not all engines provide them.
In Iceberg, Spark usually has the best support, and that’s the case here.
Trino provides capabilities in this area too.
Flink has a RewriteDataFilesAction but this isn’t exposed in Flink SQL.
Combining data files into fewer data files 🔗
Trino provides ALTER TABLE…EXECUTE optimize:
trino:rmoff> ALTER TABLE customers EXECUTE optimize;
trino:rmoff> SELECT COUNT(*) AS data_file_ct, SUM(record_count) AS record_ct FROM "customers$files";
data_file_ct | record_ct
--------------+-----------
1 | 8Note that the data file count is now one, whilst the record count is still eight.
I’ll add a few more small files:
trino:rmoff> SELECT COUNT(*) AS data_file_ct, SUM(record_count) AS record_ct FROM "customers$files";
data_file_ct | record_ct
--------------+-----------
6 | 13and then use Spark’s rewrite_data_files:
CALL polaris.system.rewrite_data_files
(table => 'rmoff.customers',
options => map ('rewrite-all', 'true')
)| rewritten_data_files_count | added_data_files_count | rewritten_bytes_count | failed_data_files_count |
|---|---|---|---|
6 |
1 |
7757 |
0 |
SELECT COUNT(*) AS data_file_ct, SUM(record_count) AS record_ct FROM polaris.rmoff.customers.files;| data_file_ct | record_ct |
|---|---|
1 |
13 |
Expiring snapshots 🔗
Being able to roll back a table’s state, or query it at a particular point in time, is rather useful—but do you need all of those snapshots? A snapshot is created for each change to the table meaning that you can end up with rather a lot of them.
To clean up snapshots you can use expire_snapshots (Spark) or ALTER TABLE … EXECUTE expire_snapshots (Trino):
trino:rmoff> SELECT * FROM "customers$snapshots";
committed_at | snapshot_id | parent_id | operation
-----------------------------+---------------------+---------------------+-----------
2025-07-14 14:37:31.531 UTC | 2403840741999442414 | NULL | append
2025-07-14 14:37:38.926 UTC | 3830932525036690208 | 2403840741999442414 | append
2025-07-14 14:37:39.916 UTC | 6409867327989167022 | 3830932525036690208 | append
2025-07-14 14:37:40.921 UTC | 325546929694535411 | 6409867327989167022 | append
2025-07-14 14:37:41.808 UTC | 269825382665437490 | 325546929694535411 | append
2025-07-14 14:37:42.757 UTC | 129306070246549703 | 269825382665437490 | append
2025-07-14 14:40:11.290 UTC | 8861050211953882166 | 129306070246549703 | replace
2025-07-14 14:42:07.828 UTC | 2371922233042001406 | 8861050211953882166 | append
2025-07-14 14:42:08.031 UTC | 5882833294520864762 | 2371922233042001406 | append
2025-07-14 14:42:08.230 UTC | 2961764211154500616 | 5882833294520864762 | append
2025-07-14 14:42:08.407 UTC | 6373025590410861521 | 2961764211154500616 | append
2025-07-14 14:42:08.600 UTC | 2039216781855207414 | 6373025590410861521 | append
2025-07-14 14:44:42.232 UTC | 4056286565502898119 | 2039216781855207414 | replace
(13 rows)trino:rmoff> SET SESSION iceberg.expire_snapshots_min_retention = '30s';
trino:rmoff> ALTER TABLE customers EXECUTE expire_snapshots(retention_threshold => '60 s');
trino:rmoff> SELECT * FROM "customers$snapshots";
committed_at | snapshot_id | parent_id | operation
-----------------------------+---------------------+---------------------+-----------
2025-07-14 14:44:42.232 UTC | 4056286565502898119 | 2039216781855207414 | replaceOther table maintenance options 🔗
Apache Amoro 🔗
Apache Amoro (incubating) is a new project that offers an Iceberg catalog with built-in optimisation.
AWS 🔗
-
S3 Tables supports built-in table maintenance.
-
AWS Glue Data Catalog provides compaction.
Nimtable 🔗
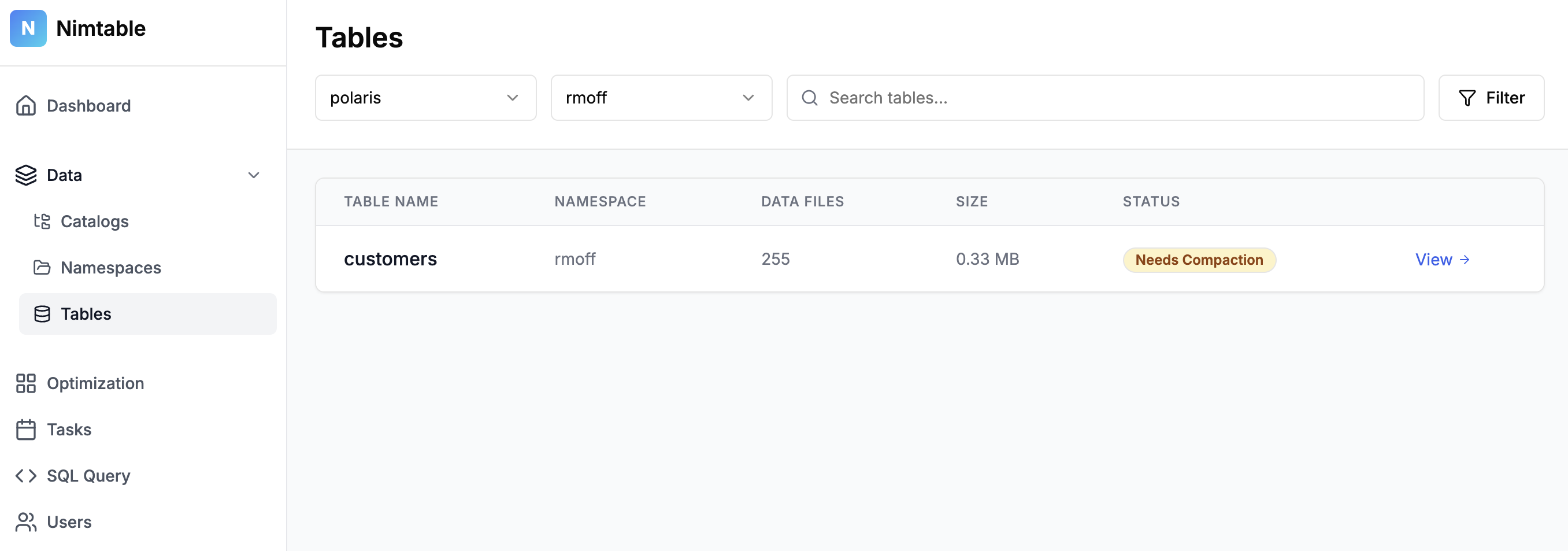
Nimtable is an Apache 2.0 licensed project that was released around June this year. It offers table compaction as part of its offering as a "Control Plane for Apache Iceberg".
Once you’ve connected it to an existing catalog (such as Polaris) it shows you the contents of the catalog:
It analyses the tables (presumably using similar heuristics as described above) to identify if they need optimising, and provides details of its analysis too:
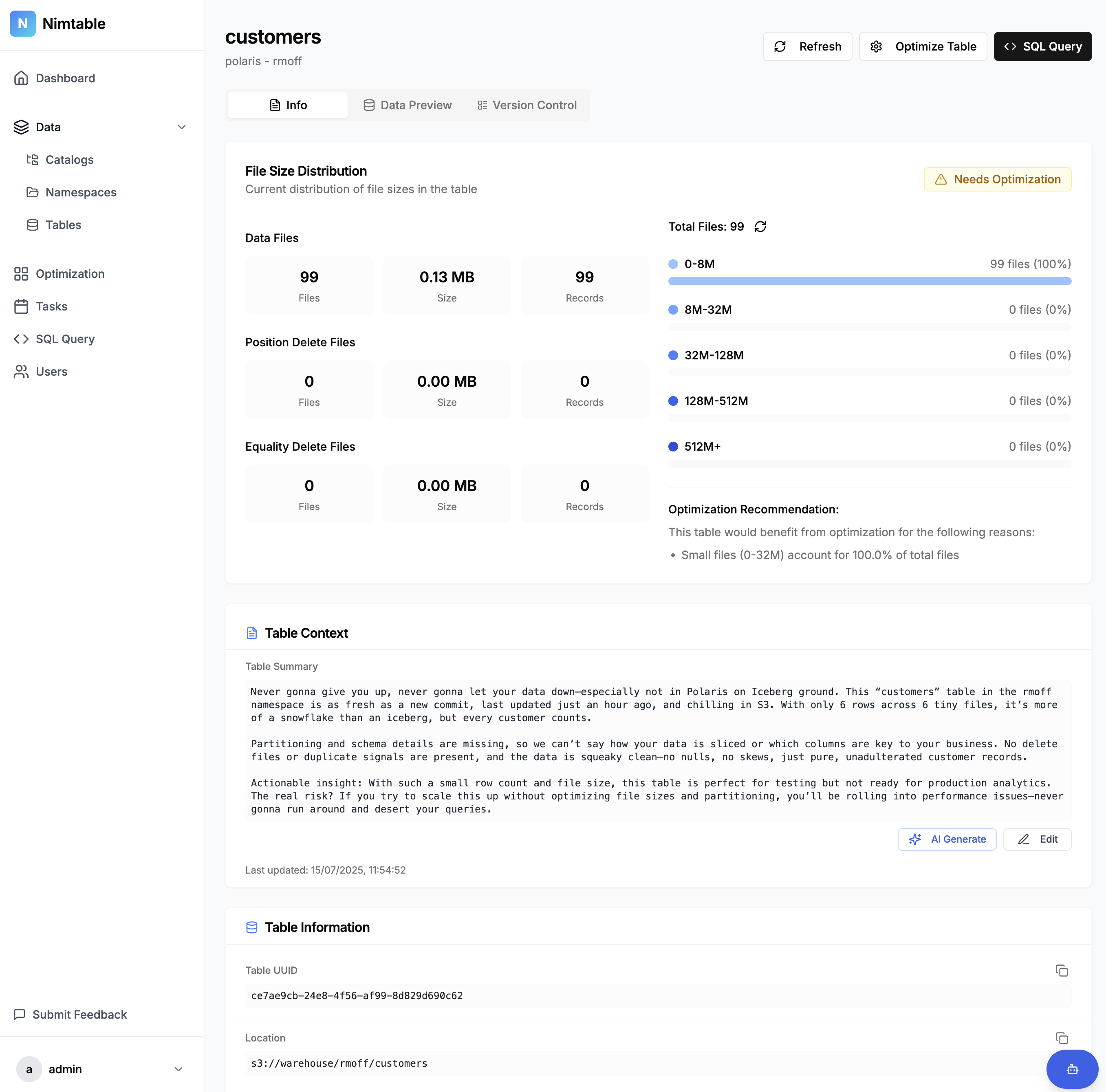
There’s also the obligatory magic fairy dust AI sprinkled onto it which puts the analysis into words.
As well as the textual analysis there’s a nice visualisation showing the rate of growth over time, broken down by type of change (insert/update/delete)
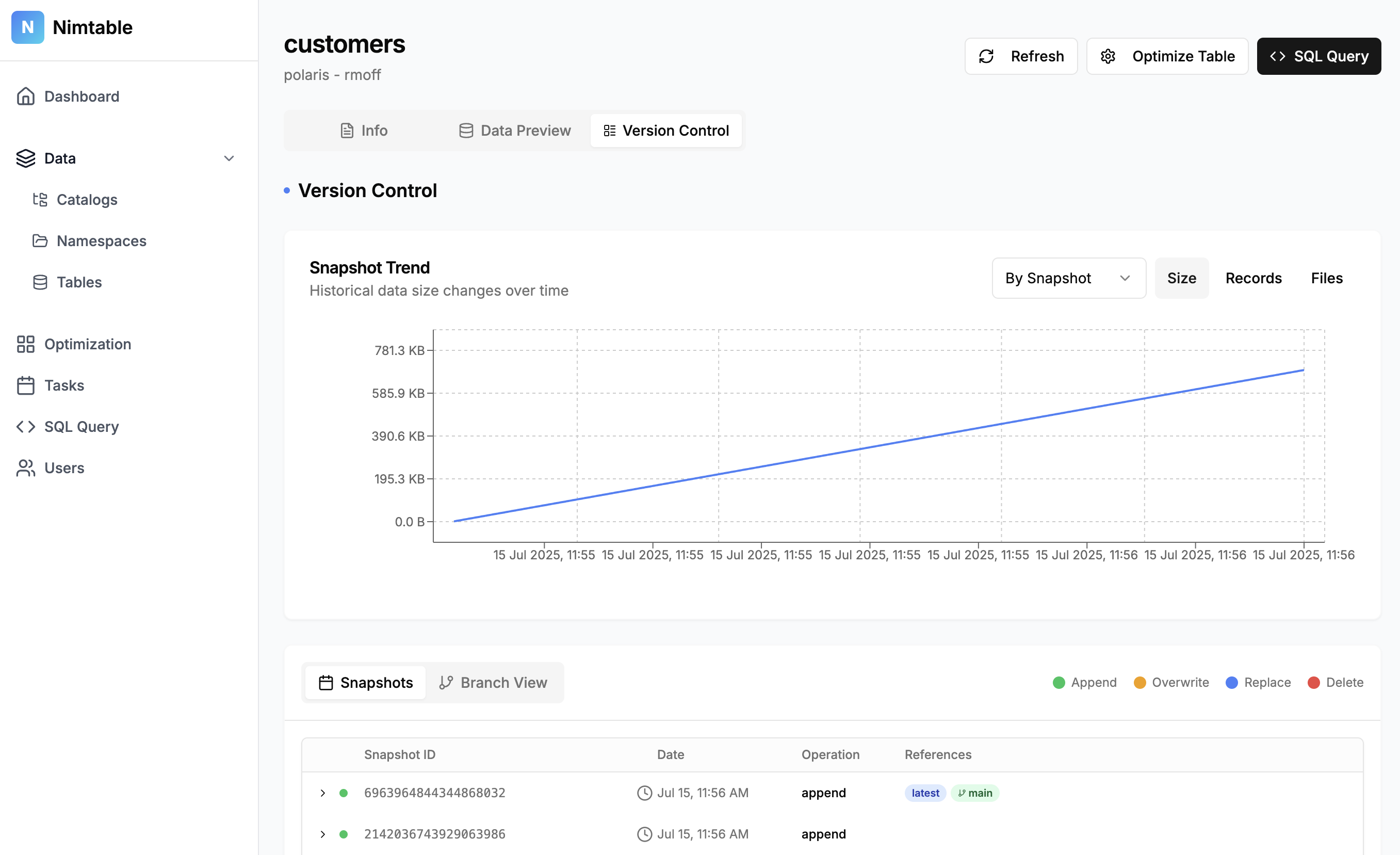
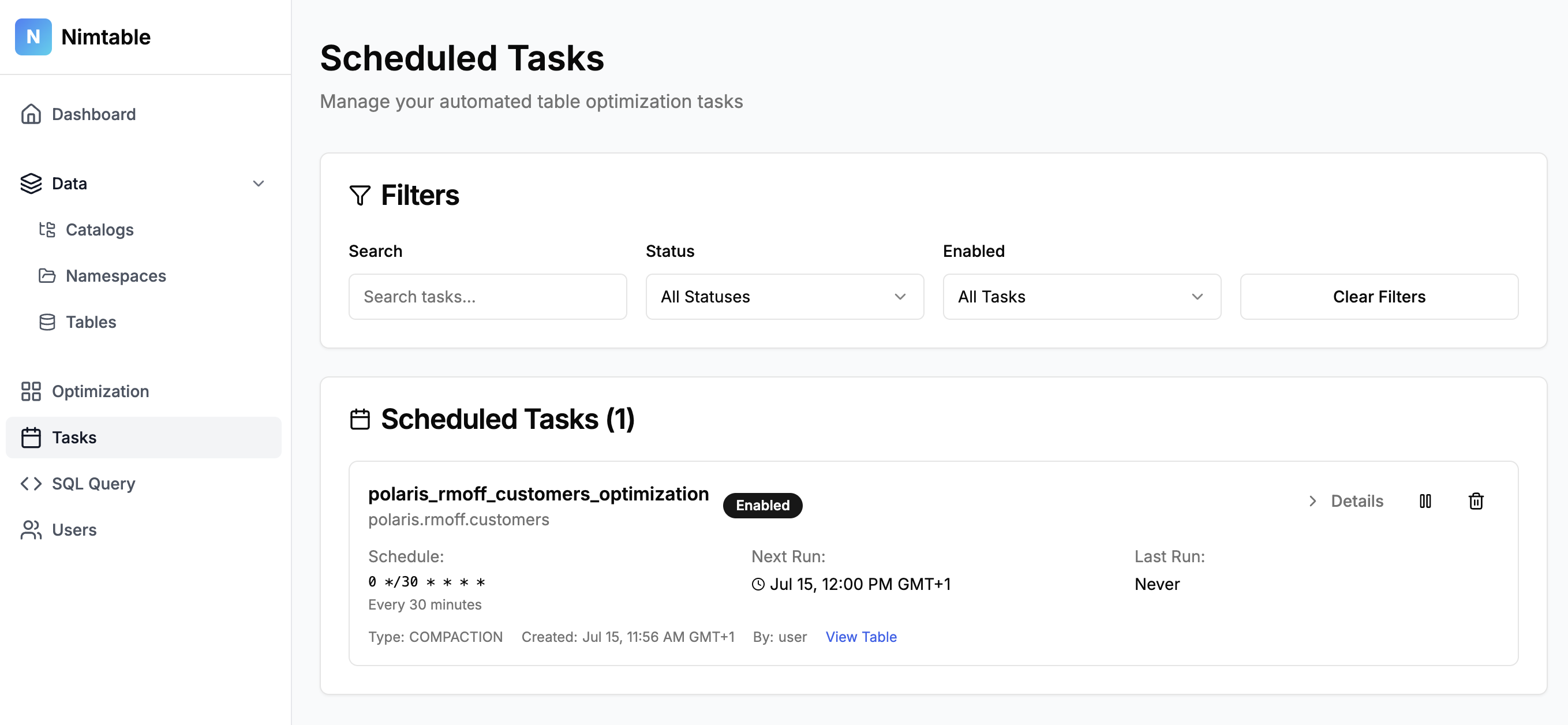
For tables that do need optimising you can run a one-off job, or set it to run on a schedule
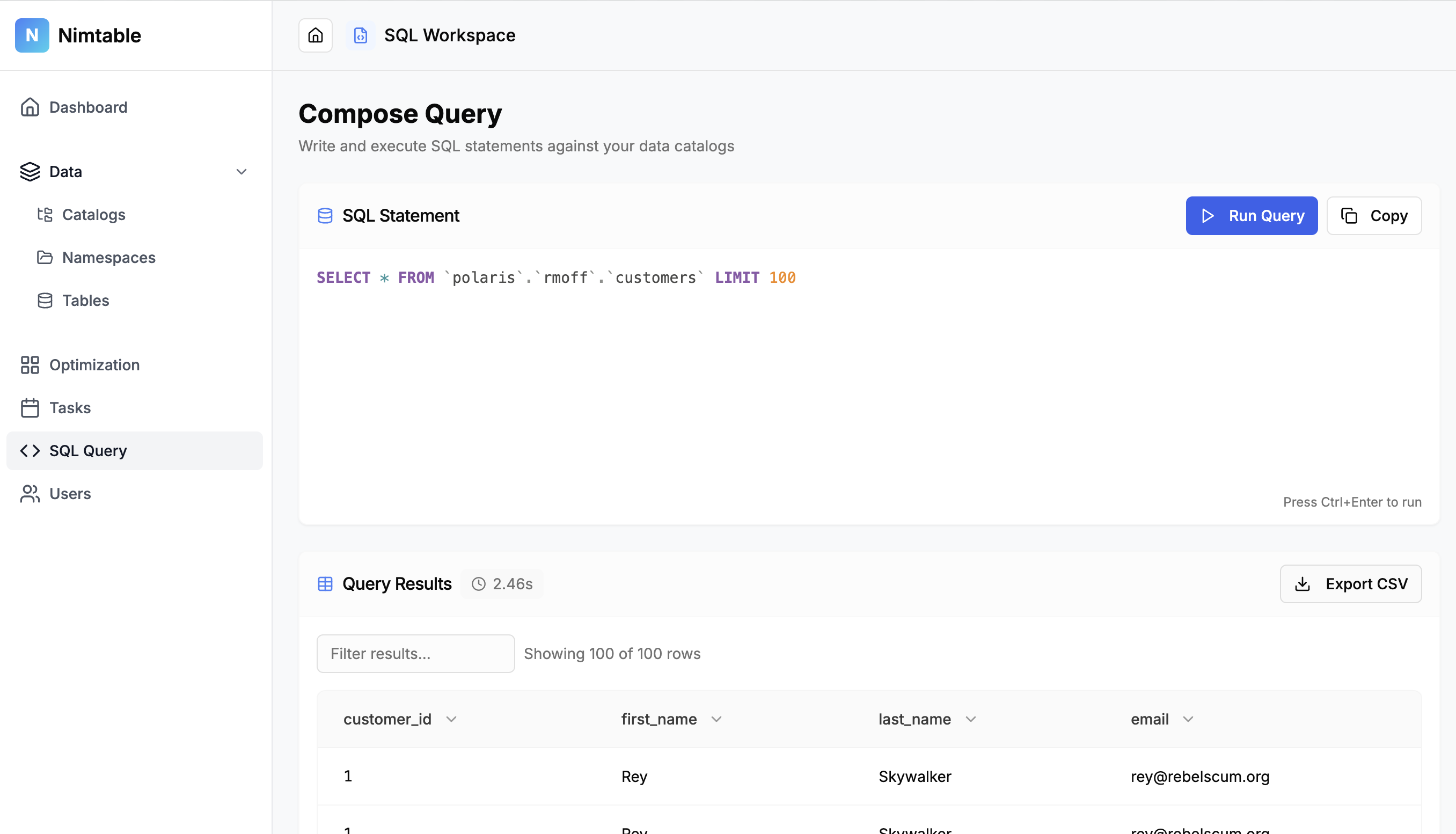
Finally, it also includes a SQL editor which is a nice touch.
I’ve only had a quick poke around, but the UI is nice and the analysis definitely useful to have. And whilst I’ve not tried it, if it behaves as claimed, the automatic optimisation could be a really nice tool if you’re self-managing your Iceberg files.
Further reading 🔗
-
Compaction in Apache Iceberg: Fine-Tuning Your Iceberg Table’s Data Files - Alex Merced
-
Solving the Small File Problem in Iceberg Tables - Thomas Cardenas
-
Apache Iceberg: The Definitive Guide - Chapter 4. Optimizing the Performance of Iceberg Tables
-
The file explosion problem in Apache Iceberg and what to do when it happens to you - Daniel Abadi