
I was exploring some new data, joining across multiple tables, and doing a simple SELECT * as I’d not worked out yet which columns I actually wanted.
The issue was, the same field name existing in more than one table.
This meant that in the results from the query, it wasn’t clear which field came from which table:
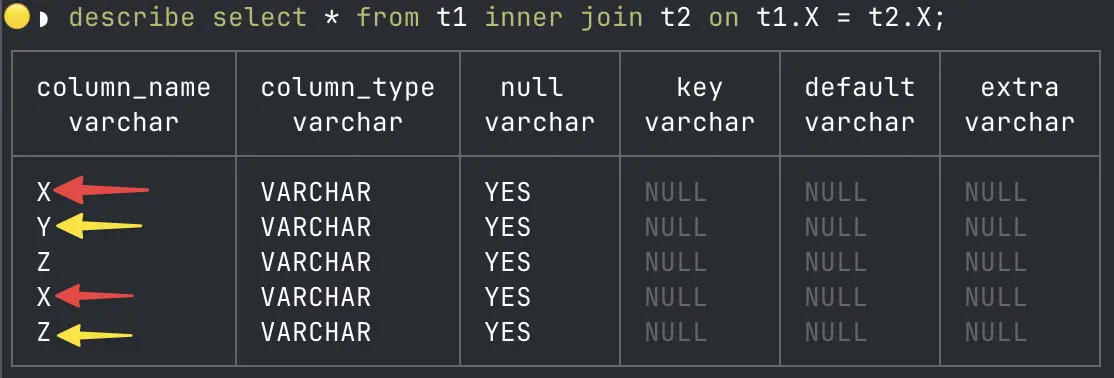
describe select *
from t1 inner join t2 on t1.X = t2.X;So, how to avoid ending up with ambiguous fields? In my example X is the same value because it’s the JOIN predicate, but Z could have a different value in each table but the result set has two fields called "Z".
I could alias each field by hand:
describe select t1.X as t1_X, t1.Y as t1_Y, t1.Z as t1_Z,
t2.X as t2_X, t2.Z as t2_Z
from t1 inner join t2 on t1.X = t2.X;┌─────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├─────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ t1_X │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t1_Y │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t1_Z │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t2_X │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t2_Z │ VARCHAR │ YES │ NULL │ NULL │ NULL │
└─────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┘But I’ve got a wide table so don’t want to hand-code the aliases for each field; I want to use SELECT *.
I could DESCRIBE each table, scrape the fields into a text editor, and use a search and replace or block edit to prefix the fields and build my SQL that way. But it’s manual and not reusable.
DuckDB COLUMNS to the rescue 🔗
Thanks to Alex Monahan on Bluesky (#dataBS FTW!), who pointed me at the COLUMNS expression.
This nice example illustrates it in action.
Applied to my query above, it looks like this:
describe select columns(t1.*) as "t1_\0",
columns(t2.*) as "t2_\0"
from t1 inner join t2 on t1.X = t2.X;┌─────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├─────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ t1_X │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t1_Y │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t1_Z │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t2_X │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t2_Z │ VARCHAR │ YES │ NULL │ NULL │ NULL │
└─────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┘Perfect!
The t1_ is the literal prefix added to the field name, and \0 a regex identifier for the field name.
You can do more fancy renaming of fields with regex too with the COLUMNS expression; check out the docs for more examples.
You can also use the new prefix aliases (added in DuckDB 1.20) if you prefer:
describe select "t1_\0": columns(t1.*),
"t2_\0": columns(t2.*)
from t1 inner join t2 on t1.X = t2.X;┌─────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├─────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ t1_X │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t1_Y │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t1_Z │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t2_X │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ t2_Z │ VARCHAR │ YES │ NULL │ NULL │ NULL │
└─────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┘