
In this post I want to build on my previous one and show another use of the Syslog data that I’m capturing. Instead of looking for SSH attacks, I’m going to analyse the behaviour of my networking components.
| You can find all the code to run this on GitHub. |
Getting Syslog data into Kafka 🔗
As before, let’s create ourselves a syslog connector in ksqlDB:
CREATE SOURCE CONNECTOR SOURCE_SYSLOG_UDP_01 WITH (
'tasks.max' = '1',
'connector.class' = 'io.confluent.connect.syslog.SyslogSourceConnector',
'topic' = 'syslog',
'syslog.port' = '42514',
'syslog.listener' = 'UDP',
'syslog.reverse.dns.remote.ip' = 'true',
'confluent.license' = '',
'confluent.topic.bootstrap.servers' = 'kafka:29092',
'confluent.topic.replication.factor' = '1'
);Check that it’s running :
ksql> DESCRIBE CONNECTOR SOURCE_SYSLOG_UDP_01;
Name : SOURCE_SYSLOG_UDP_01
Class : io.confluent.connect.syslog.SyslogSourceConnector
Type : source
State : RUNNING
WorkerId : kafka-connect-01:8083
Task ID | State | Error Trace
---------------------------------
0 | RUNNING |
---------------------------------
ksql>Configuring Unifi devices to send Syslog data to Kafka 🔗
Now configure my networking equipment (switches, access points, routers) to route their syslog data to this machine
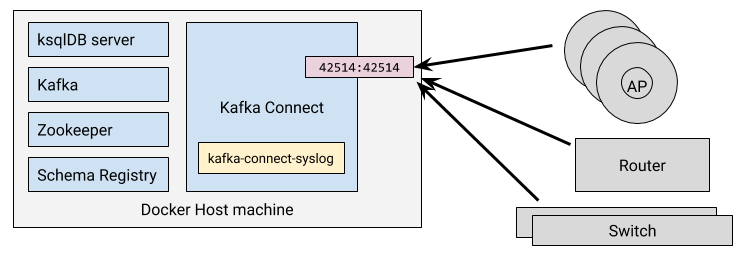
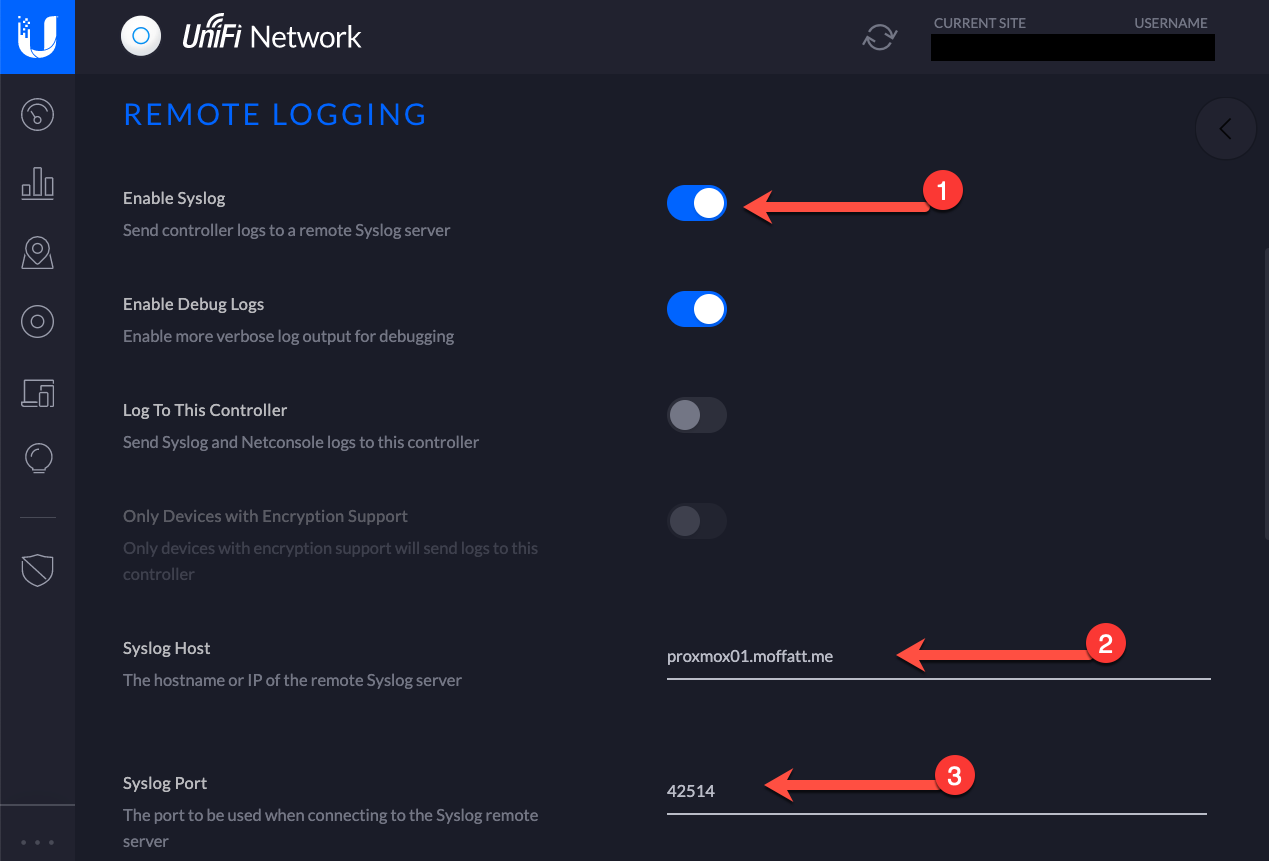
Now if I dump the Syslog Kafka topic to screen I can see it being populated with messages from my network devices:
ksql> PRINT syslog;
Format:AVRO
12/20/19 10:24:35 AM UTC, usgmoffattme, {"name": null, "type": "RFC3164", "message": "root : TTY=unknown ; PWD=/ ; USER=root ; COMMAND=/usr/sbin/ipsec statusall", "host": "usgmoffattme", "version": null, "level": 6, "tag": "sudo", "extension": null, "severity": null, "appName": null, "facility": 10, "remoteAddress": "192.168.10.1", "rawMessage": "<86>Dec 20 10:24:35 usgmoffattme sudo: root : TTY=unknown ; PWD=/ ; USER=root ; COMMAND=/usr/sbin/ipsec statusall", "processId": null, "messageId": null, "structuredData": null, "deviceVendor": null, "deviceProduct": null, "deviceVersion": null, "deviceEventClassId": null, "date": 1576837475000}
12/20/19 10:25:52 AM UTC, usgmoffattme, {"name": null, "type": "RFC3164", "message": "[WAN_IN-3006-A]IN=eth0 OUT=eth1 MAC=f0:9f:c2:12:a8:f4:04:2a:e2:c7:4c:1a:08:00 SRC=x.x.x.x DST=192.168.10.105 LEN=60 TOS=0x00 PREC=0x00 TTL=51 ID=30052 DF PROTO=TCP SPT=35214 DPT=22 WINDOW=29200 RES=0x00 SYN URGP=0 ", "host": "usgmoffattme", "version": null, "level": 4, "tag": "kernel", "extension": null, "severity": null, "appName": null, "facility": 0, "remoteAddress": "192.168.10.1", "rawMessage": "<4>Dec 20 10:25:52 usgmoffattme kernel: [WAN_IN-3006-A]IN=eth0 OUT=eth1 MAC=f0:9f:c2:12:a8:f4:04:2a:e2:c7:4c:1a:08:00 SRC=x.x.x.x DST=192.168.10.105 LEN=60 TOS=0x00 PREC=0x00 TTL=51 ID=30052 DF PROTO=TCP SPT=35214 DPT=22 WINDOW=29200 RES=0x00 SYN URGP=0 ", "processId": null, "messageId": null, "structuredData": null, "deviceVendor": null, "deviceProduct": null, "deviceVersion": null, "deviceEventClassId": null, "date": 1576837552000}Analysing Syslog hosts with ksqlDB 🔗
Let’s have a look at which devices we’ve got Syslog data for. First off we’ll declare a ksqlDB stream on top of the topic.
CREATE STREAM SYSLOG WITH (KAFKA_TOPIC='syslog', VALUE_FORMAT='AVRO');| Since we’re writing to the topic using Avro we don’t need to enter a schema here (since it already exists in the Schema Registry). ksqlDB works with JSON and CSV (🤮) too but you’d have to declare the schema at this point. |
Now we can use the schema of the data to query the data. We’re going to tell ksqlDB to read all the data in the Kafka topic by setting SET 'auto.offset.reset' = 'earliest'; and then run an aggregation:
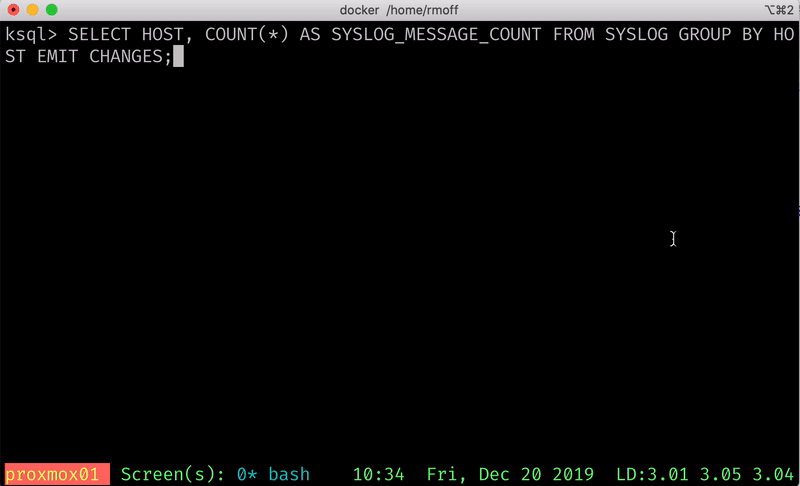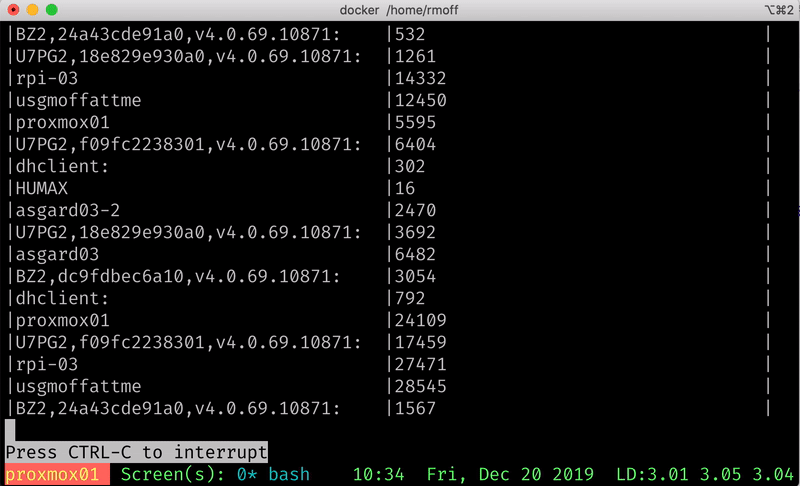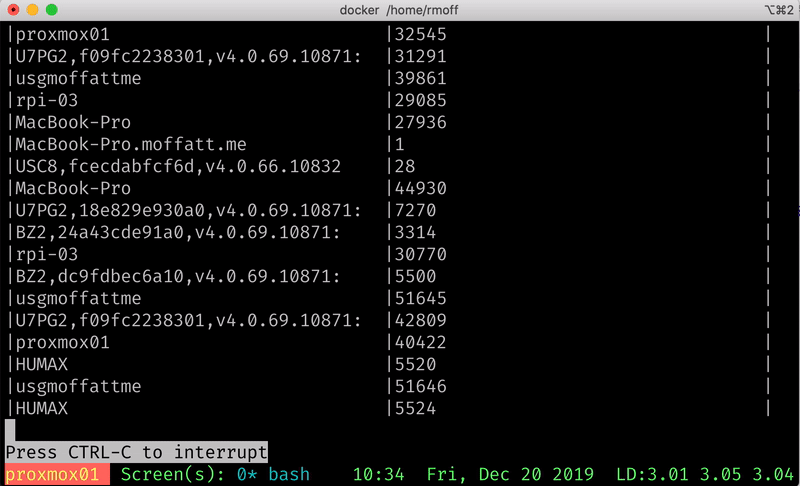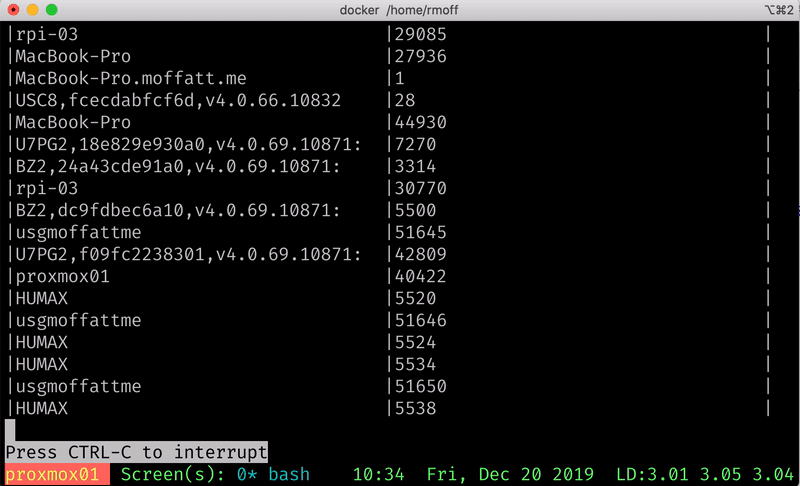
ksql> SELECT HOST, COUNT(*) AS SYSLOG_MESSAGE_COUNT FROM SYSLOG GROUP BY HOST EMIT CHANGES;
+----------------------------------+---------------------+
|HOST |SYSLOG_MESSAGE_COUNT |
+----------------------------------+---------------------+
|asgard03 |17278 |
|BZ2,24a43cde91a0,v4.0.69.10871: |3023 |
|BZ2,dc9fdbec6a10,v4.0.69.10871: |5194 |
|MacBook-Pro |42269 |
|proxmox01 |37279 |
|rpi-03 |30125 |
|U7PG2,18e829e930a0,v4.0.69.10871: |6592 |
|U7PG2,f09fc2238301,v4.0.69.10871: |38283 |
|USC8,fcecdabfcf6d,v4.0.66.10832 |26 |
|usgmoffattme |45695 |
…You might look at that query and think it looks pretty like any other SQL you’ve seen, except for the EMIT CHANGES. All that means is that ksqlDB will keep sending us the changes to the data as it occurs - so each new Syslog event that arrives will increase the aggregate value of the COUNT(*) per host, and so it is re-emitted:
The alternative is to materialise this data into a state store…
ksql> CREATE TABLE HOST_SYSLOG_AGG AS
SELECT HOST,
COUNT(*) AS MESSAGE_COUNT
FROM SYSLOG
GROUP BY HOST;…that we can then query directly:
ksql> SELECT MESSAGE_COUNT FROM HOST_SYSLOG_AGG WHERE ROWKEY='asgard03';
+-----------------+
|MESSAGE_COUNT |
+-----------------+
|17278 |
Query terminated
ksql>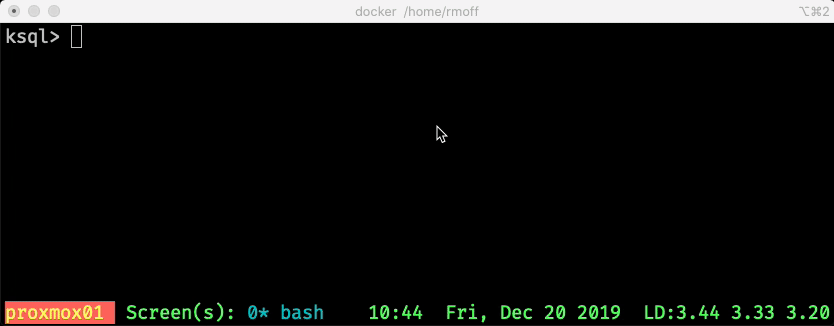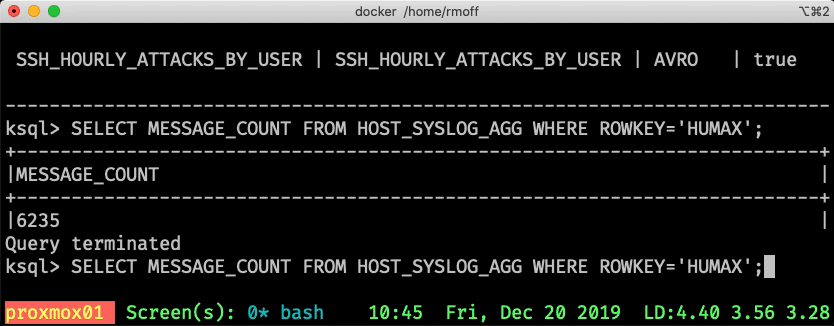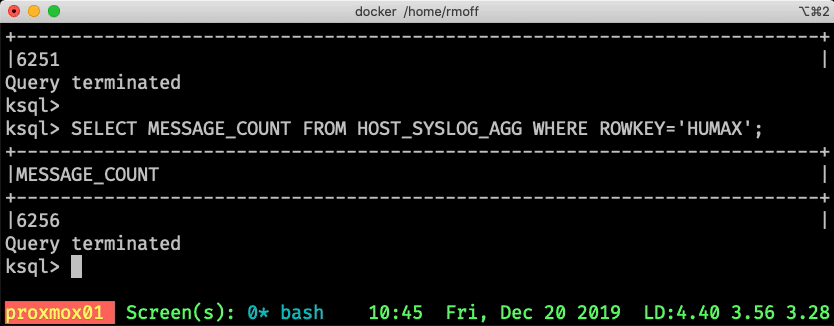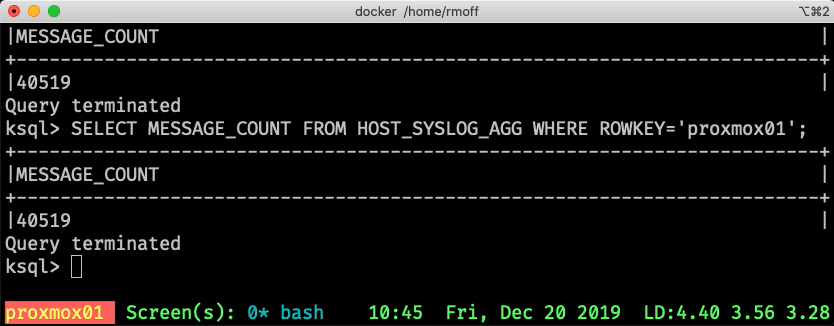
Note that the query says Query terminated since it returns back to the user. It’s called a "pull query" - the user requests the state of a key from ksqlDB, which is returned. Contrast that to the above "push query" in which EMIT CHANGES tells ksqlDB to keep sending us the changes to the state as it occurs.
Creating a dedicated Unifi Syslog stream 🔗
So…we’ve got Syslog data for a bunch of different hosts. Let’s create a new Kafka topic that’s populated in realtime with Syslog messages just for our network devices. Which are my network devices? These ones:
BZ2,24a43cde91a0,v4.0.69.10871:
BZ2,dc9fdbec6a10,v4.0.69.10871:
U7PG2,18e829e930a0,v4.0.69.10871:
U7PG2,f09fc2238301,v4.0.69.10871:
USC8,fcecdabfcf6d,v4.0.66.10832
usgmoffattme There are a couple of ways to select messages with which to populate this new topic. I could hardcode a predicate list of all the hostnames of my network devices.
CREATE STREAM UBNT_SYSLOG
AS SELECT * FROM SYSLOG
WHERE HOST='BZ2,24a43cde91a0,v4.0.69.10871:'
OR HOST='BZ2,dc9fdbec6a10,v4.0.69.10871:'
OR HOST='U7PG2,18e829e930a0,v4.0.69.10871:'
OR HOST='U7PG2,f09fc2238301,v4.0.69.10871:'
OR HOST='USC8,fcecdabfcf6d,v4.0.66.10832'
OR HOST='usgmoffattme'
EMIT CHANGES;That’s only so useful whilst that list doesn’t change. I could wildcard it based on the patterns in the naming (U7PG2 is the prefix of one of the access point types, etc):
CREATE STREAM UBNT_SYSLOG
AS SELECT * FROM SYSLOG
WHERE HOST LIKE 'BZ2%'
OR HOST LIKE 'U7PG2%'
OR HOST LIKE 'USC8%'
OR HOST='usgmoffattme'
EMIT CHANGES;This is better because the stream will adapt as new devices are added—but only if they match those patterns. The best way to do it is simply have a list of network devices in a ksqlDB table (which is backed by a Kafka topic)…
CREATE TABLE UBNT_NETWORK_DEVICES (ROWKEY STRING KEY)
WITH (KAFKA_TOPIC='network_devices',VALUE_FORMAT='AVRO', PARTITIONS=1);
INSERT INTO UBNT_NETWORK_DEVICES VALUES ('BZ2,24a43cde91a0,v4.0.69.10871:');
INSERT INTO UBNT_NETWORK_DEVICES VALUES ('BZ2,dc9fdbec6a10,v4.0.69.10871:');
INSERT INTO UBNT_NETWORK_DEVICES VALUES ('U7PG2,18e829e930a0,v4.0.69.10871:');
INSERT INTO UBNT_NETWORK_DEVICES VALUES ('U7PG2,f09fc2238301,v4.0.69.10871:');
INSERT INTO UBNT_NETWORK_DEVICES VALUES ('USC8,fcecdabfcf6d,v4.0.66.10832');
INSERT INTO UBNT_NETWORK_DEVICES VALUES ('usgmoffattme');…and then join to this to create the stream. By using an INNER JOIN I force it to only return messages for which there is a corresponding host on the UBNT_NETWORK_DEVICES table. Now any time I add a new network device I just add it to the table (with an INSERT INTO) and it gets picked up automagically in the join.
CREATE STREAM UBNT_SYSLOG
AS SELECT S.*
FROM SYSLOG S
INNER JOIN UBNT_NETWORK_DEVICES U
ON S.HOST = U.ROWKEY
EMIT CHANGES;Now I have a new Kafka topic called UBNT_SYSLOG:
ksql> SHOW TOPICS;
Kafka Topic | Partitions | Partition Replicas
-------------------------------------------------------------------
…
network_devices | 1 | 1
syslog | 1 | 1
UBNT_SYSLOG | 1 | 1
…
-------------------------------------------------------------------and when I check the number of messages for each host, I can see that it only contains messages for my Unifi hosts:
ksql> SELECT S_HOST, COUNT(*) AS SYSLOG_MESSAGE_COUNT
FROM UBNT_SYSLOG
GROUP BY S_HOST
EMIT CHANGES;
+----------------------------------+---------------------+
|S_HOST |SYSLOG_MESSAGE_COUNT |
+----------------------------------+---------------------+
|BZ2,dc9fdbec6a10,v4.0.69.10871: |3106 |
|U7PG2,18e829e930a0,v4.0.69.10871: |3757 |
|BZ2,24a43cde91a0,v4.0.69.10871: |1590 |
|U7PG2,f09fc2238301,v4.0.69.10871: |17658 |
|usgmoffattme |28964 |
…Access point usage 🔗
I want to revisit this example to show how we can easily wrangle and enrich the raw Syslog data. When I come home and my iPhone connects to my network, the Access Point logs this, with a raw Syslog message that looks like this:
<30>Dec 13 17:02:59 BZ2,dc9fdbec6a10,v4.0.69.10871: hostapd: ath1: STA 50:c7:bf:da:db:5e IEEE 802.11: associatedWe can parse this down into usable fields using ksqlDB, which we’re going to write to a new stream to make subsequent processing easier:
ksql> CREATE STREAM AP_CLIENT_EVENTS AS
SELECT TIMESTAMPTOSTRING(S_DATE,'yyyy-MM-dd HH:mm:ss','Europe/London') AS EVENT_TIME,
S_REMOTEADDRESS AS AP_IP,
SPLIT(S_MESSAGE,' ')[2] AS CLIENT_MAC,
SPLIT(S_MESSAGE,'IEEE 802.11: ')[1] AS ACTION
FROM UBNT_SYSLOG
WHERE S_MESSAGE LIKE '%associated%'
EMIT CHANGES;
ksql> SELECT EVENT_TIME, AP_IP, CLIENT_MAC, ACTION
FROM AP_CLIENT_EVENTS
EMIT CHANGES;
+--------------------+---------------+------------------+--------------+
|EVENT_TIME |AP_IP |CLIENT_MAC |ACTION |
+--------------------+---------------+------------------+--------------+
|2019-12-13 17:02:59 |192.168.10.67 |50:c7:bf:da:db:5e |associated |
|2019-12-13 17:07:59 |192.168.10.68 |f0:c3:71:2a:04:20 |disassociated |
|2019-12-13 17:09:34 |192.168.10.67 |50:c7:bf:da:db:5e |disassociated |
|2019-12-13 17:16:37 |192.168.10.67 |c8:f6:50:17:17:d3 |associated |
…But we’ve just got some access point IP addresses and client MAC addresses. What devices actually are they?
Using data from MongoDB in ksqlDB 🔗
Unifi uses MongoDB as its data store for information about the network, including things like the MAC address and name of client devices, IP addresses of access points, and so on. We can ingest this data into ksqlDB using Debezium and use it for lookups in our queries. Let’s pull in information about the network devices and clients:
CREATE SOURCE CONNECTOR SOURCE_MONGODB_UNIFI_01 WITH (
'connector.class' = 'io.debezium.connector.mongodb.MongoDbConnector',
'mongodb.hosts' = 'rs0/mongodb:27017',
'mongodb.name' = 'unifi',
'collection.whitelist' = 'ace.device, ace.user'
);With the connector running we get a snapshot of the current MongoDB collections, along with any changes to them, stored in Kafka topics that we can register in ksqlDB. We register them as ksqlDB streams first, because we need to make sure that before creating them as tables we’ve set the partitioning key correctly:
ksql> CREATE STREAM DEVICES_RAW WITH (KAFKA_TOPIC='unifi.ace.device', VALUE_FORMAT='AVRO');
ksql> CREATE STREAM USERS_RAW WITH (KAFKA_TOPIC='unifi.ace.user', VALUE_FORMAT='AVRO');From the streams we can extract the current details about the devices and users:
ksql> SELECT EXTRACTJSONFIELD(AFTER ,'$.mac') AS MAC,
EXTRACTJSONFIELD(AFTER ,'$.ip') AS IP,
EXTRACTJSONFIELD(AFTER ,'$.name') AS NAME,
EXTRACTJSONFIELD(AFTER ,'$.model') AS MODEL,
EXTRACTJSONFIELD(AFTER ,'$.type') AS TYPE
FROM DEVICES_RAW
EMIT CHANGES;
+------------------+------------------------+------+------+
|MAC |NAME |MODEL |TYPE |
+------------------+------------------------+------+------+
|f0:9f:xx:xx:xx:f4 |usg.moffatt.me |UGW3 |ugw |
|24:a4:xx:xx:xx:a0 |Unifi AP - Attic |BZ2 |uap |
|18:e8:xx:xx:xx:a0 |Unifi AP - Study (new) |U7PG2 |uap |
|f0:9f:xx:xx:xx:01 |Unifi AP - Sitting Room |U7PG2 |uap |
|dc:9f:xx:xx:xx:10 |Unifi AP - Kitchen |BZ2 |uap |
|fc:ec:xx:xx:xx:6d |Switch - Study |USC8 |usw |
…
I’m using EXTRACTJSONFIELD instead of the io.debezium.connector.mongodb.transforms.ExtractNewDocumentState transformation because the schema in MongoDB changes between documents and caused a Schema Registry compatibility check failure.
|
Now we’ll write the snapshot of data (plus any new changes that come through from MongoDB) into new Kafka topics, with the data tidied up into a proper schema, and the messages keyed on the column on which they’re going to be joined later on:
ksql> CREATE STREAM DEVICES_REKEY AS
SELECT EXTRACTJSONFIELD(AFTER ,'$.mac') AS MAC,
EXTRACTJSONFIELD(AFTER ,'$.ip') AS IP,
EXTRACTJSONFIELD(AFTER ,'$.name') AS NAME,
EXTRACTJSONFIELD(AFTER ,'$.model') AS MODEL,
EXTRACTJSONFIELD(AFTER ,'$.type') AS TYPE
FROM DEVICES_RAW
PARTITION BY IP;
ksql> CREATE STREAM USERS_REKEY AS
SELECT EXTRACTJSONFIELD(AFTER ,'$.mac') AS MAC,
EXTRACTJSONFIELD(AFTER ,'$.name') AS NAME,
EXTRACTJSONFIELD(AFTER ,'$.hostname') AS HOSTNAME,
CAST(EXTRACTJSONFIELD(AFTER ,'$.is_guest') AS BOOLEAN) AS IS_GUEST,
EXTRACTJSONFIELD(AFTER ,'$.oui') AS OUI
FROM USERS_RAW
PARTITION BY MAC;Data wrangling with ksqlDB 🔗
Looking at the user data we notice it’s going to need a bit of cleaning up to give us a single field by which to label a user’s connection. There’s a mix of fields that give us an identifiable label (NAME / HOSTNAME) that we need to wrangle together.
ksql> SELECT MAC,NAME,HOSTNAME,OUI,IS_GUEST FROM USERS_REKEY EMIT CHANGES;
+------------------+----------------------------+--------------------------+---------+---------+
|MAC |NAME |HOSTNAME |OUI |IS_GUEST |
+------------------+----------------------------+--------------------------+---------+---------+
|18:b4:30:2d:b2:29 |Nest |02AA01AC17140ADS |NestLabs |false |
|44:65:0d:e0:94:66 |Robin - Kindle |null |AmazonTe |false |
|b8:ac:6f:54:cf:4e |crashplan.moffatt.me |rmoff-Inspiron-1764 |Dell |false |
|66:65:34:30:30:34 |monitoring-01.moffatt.me |null | |false |
|36:39:61:36:30:36 |cdh57-01-node-02.moffatt.me |null | |false |
|5c:cf:7f:52:e9:c3 |Wifi Plug - Sitting Room |ESP_52E9C3 |Espressi |false |
|84:c7:ea:6c:53:5c |null |android-f1b22cbacced1ca4 |SonyMobi |true |
|ac:29:3a:2f:42:53 |null |iPhone |Apple |true |
|6c:b7:49:a7:d2:6b |null |HUAWEI_P10-f56f4a35871f46 |HuaweiTe |true |
|dc:9f:db:ed:6a:10 |null |null |Ubiquiti |false |
…There’s also the network devices themselves that are also 'users' on the network, but which don’t have a useful label (see the last entry in the table above). For those we’re going to merge in some data from the DEVICES table.
First up, we clean the normal users with some SQL into a new derived stream, excluding any network devices (OUI != 'Ubiquiti'). Here we’re saying to derive a new NAME field based on:
-
Existing
NAMEplusHOSTNAMEif it exists -
If
NAMEdoesn’t exist then try to useHOSTNAME -
If neither exist then take the device manufacturer (
OUI) and concatenate it with the only other identifier, that of whether the device is a guest or not.
ksql> CREATE STREAM USERS_REKEY_CLEANSED AS
SELECT MAC,
CASE WHEN NAME IS NULL THEN
CASE WHEN HOSTNAME IS NULL THEN
CASE WHEN IS_GUEST THEN 'guest_'
ELSE 'nonguest_'
END + OUI
ELSE HOSTNAME
END
ELSE CASE WHEN HOSTNAME IS NULL THEN NAME
ELSE NAME + ' (' + HOSTNAME + ')'
END
END AS NAME
FROM USERS_REKEY
WHERE OUI != 'Ubiquiti'
EMIT CHANGES;Then we insert into the users stream the network devices so that we have a reference for those too when they are active against access points:
ksql> INSERT INTO USERS_REKEY_CLEANSED (ROWKEY, MAC, NAME) AS
SELECT MAC, MAC, NAME FROM DEVICESThis gives us client names that look like this, which is much more useful:
ksql> SELECT MAC, NAME FROM USERS_REKEY_CLEANSED EMIT CHANGES LIMIT 20;
+------------------+----------------------------+
|MAC |NAME |
+------------------+----------------------------+
|18:b4:30:2d:b2:29 |Nest |
|44:65:0d:e0:94:66 |Robin - Kindle |
|66:65:34:30:30:34 |monitoring-01.moffatt.me |
|5c:cf:7f:52:e9:c3 |Wifi Plug - Sitting Room |
|84:c7:ea:6c:53:5c |nonguest_SonyMobi |
…Now we declare tables on these two streams which have now had the partitioning key set correctly. The tables are what we’ll use for the join.
ksql> CREATE TABLE DEVICES WITH (KAFKA_TOPIC='DEVICES_REKEY',VALUE_FORMAT='AVRO');
ksql> CREATE TABLE USERS WITH (KAFKA_TOPIC='USERS_REKEY_CLEANSED',VALUE_FORMAT='AVRO');Using ksqlDB to lookup reference data for a stream of events 🔗
We’re now in a position to join to the stream of network events to the lookup data from MongoDB:
ksql> SELECT E.EVENT_TIME,
E.AP_IP,
D.NAME,
E.CLIENT_MAC,
E.ACTION
FROM AP_CLIENT_EVENTS E
LEFT OUTER JOIN DEVICES D
ON E.AP_IP = D.ROWKEY
EMIT CHANGES;
+--------------------+--------------+-------------------+------------------+--------------+
|EVENT_TIME |AP_IP |NAME |CLIENT_MAC |ACTION |
+--------------------+--------------+-------------------+------------------+--------------+
|2019-12-13 17:02:59 |192.168.10.67 |Unifi AP - Kitchen |50:c7:bf:da:db:5e |associated |
|2019-12-13 17:07:59 |192.168.10.68 |Unifi AP - Attic |f0:c3:71:2a:04:20 |disassociated |
|2019-12-13 17:09:34 |192.168.10.67 |Unifi AP - Kitchen |50:c7:bf:da:db:5e |disassociated |
|2019-12-13 17:16:37 |192.168.10.67 |Unifi AP - Kitchen |c8:f6:50:17:17:d3 |associated |
|2019-12-16 16:34:43 |192.168.10.68 |Unifi AP - Attic |40:b4:cd:58:40:8f |associated |
…ksqlDB doesn’t support multi-way joins, so we need two hops to get to the finished stream:
ksql> CREATE STREAM AP_CLIENT_EVENTS_STG_01 AS
SELECT E.EVENT_TIME,
E.AP_IP,
D.NAME,
E.CLIENT_MAC,
E.ACTION
FROM AP_CLIENT_EVENTS E
LEFT OUTER JOIN DEVICES D
ON E.AP_IP = D.ROWKEY
EMIT CHANGES;
ksql> CREATE STREAM AP_CLIENT_EVENTS_ENRICHED AS
SELECT E.EVENT_TIME,
E.AP_IP,
E.NAME AS AP_NAME,
E.CLIENT_MAC,
U.NAME AS CLIENT_NAME,
E.ACTION
FROM AP_CLIENT_EVENTS_STG_01 E
LEFT OUTER JOIN USERS U
ON E.CLIENT_MAC = U.ROWKEY
EMIT CHANGES;Finally, we have a stream of access point events, enriched with the name of the access point and the user device connecting or disconnecting from it. It’s processing all the existing events on the Kafka topic, as well as new ones as they arrive. With a handful of SQL statements we’ve filtered and parsed a raw Syslog into a really useful stream of data.
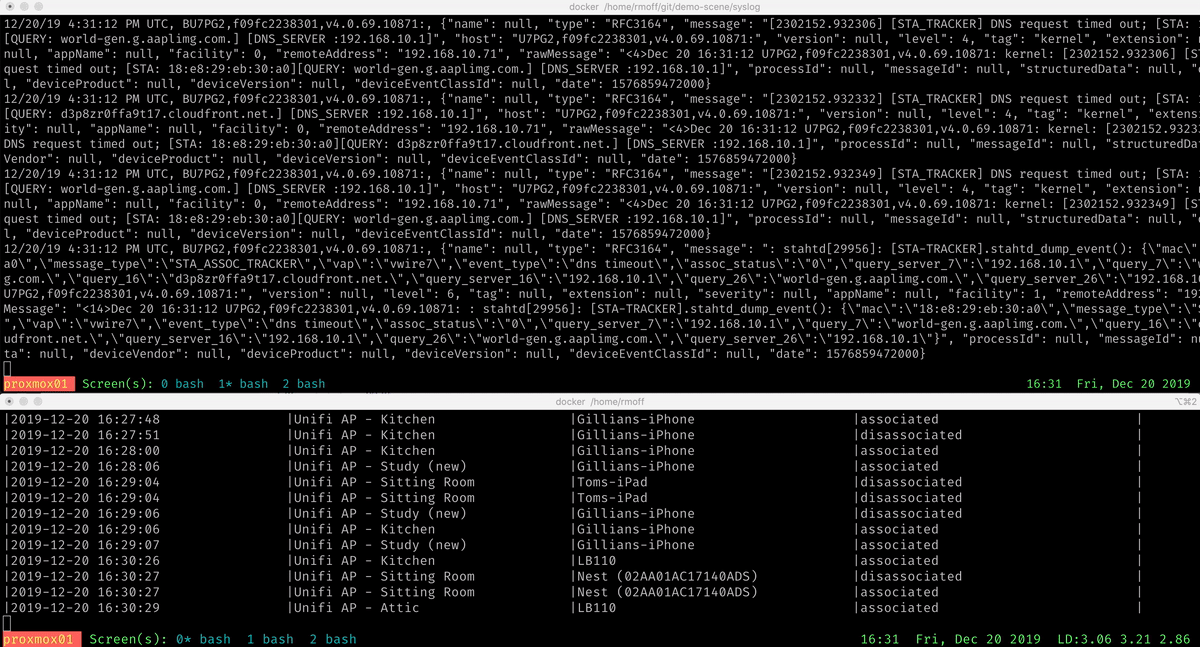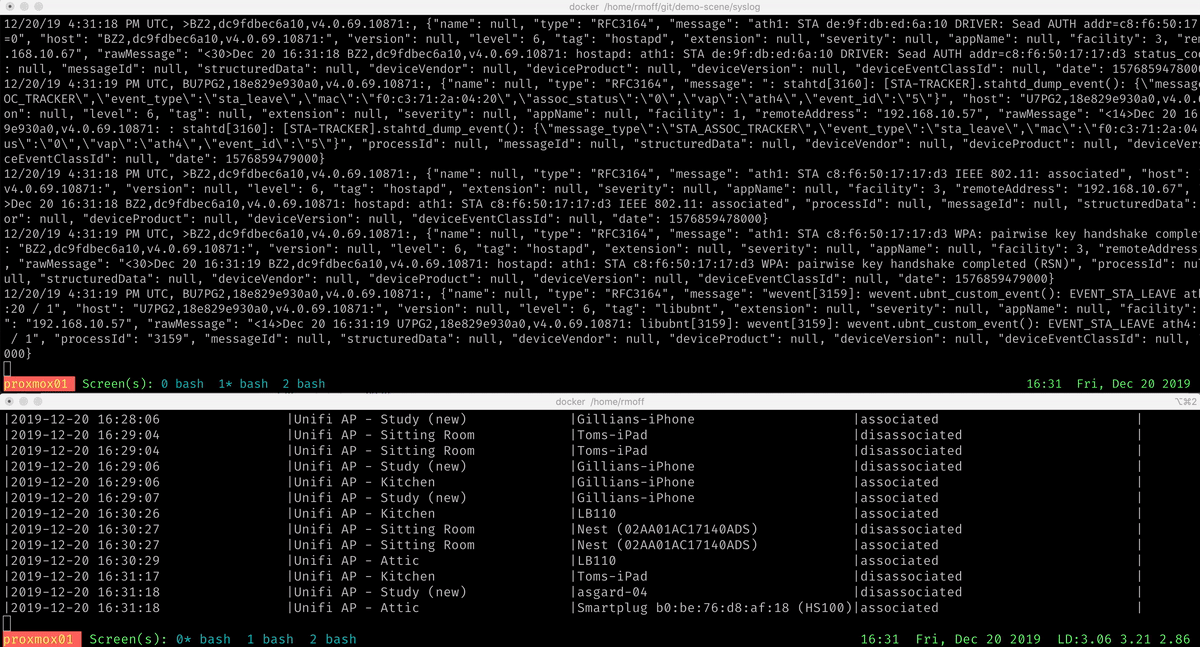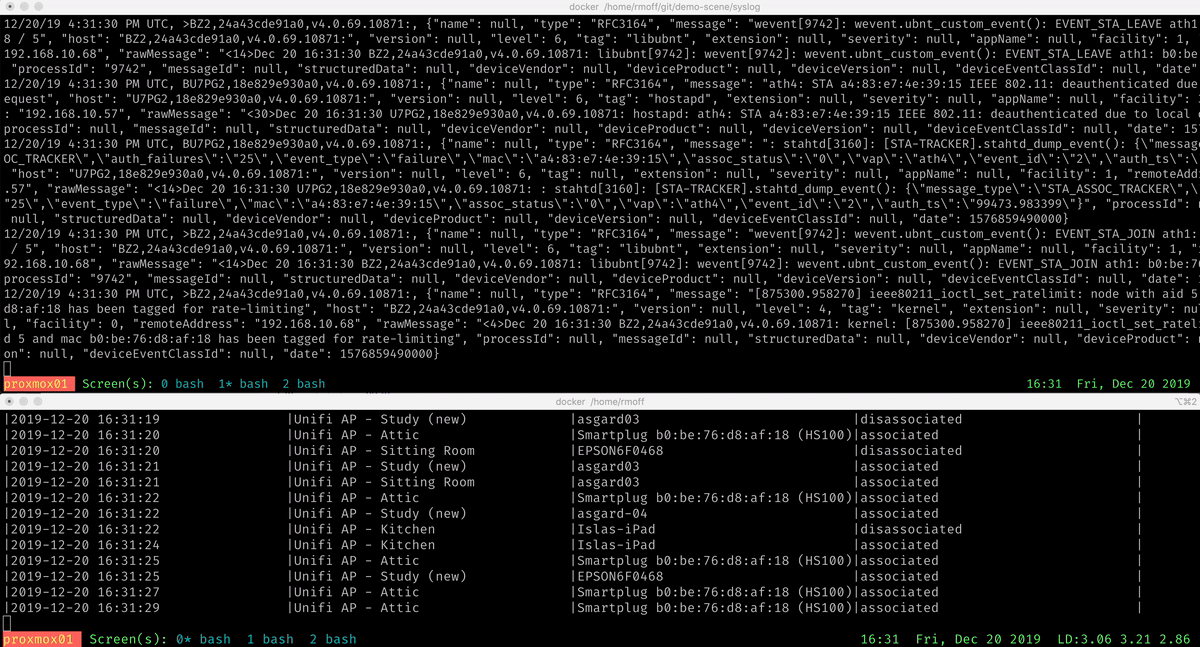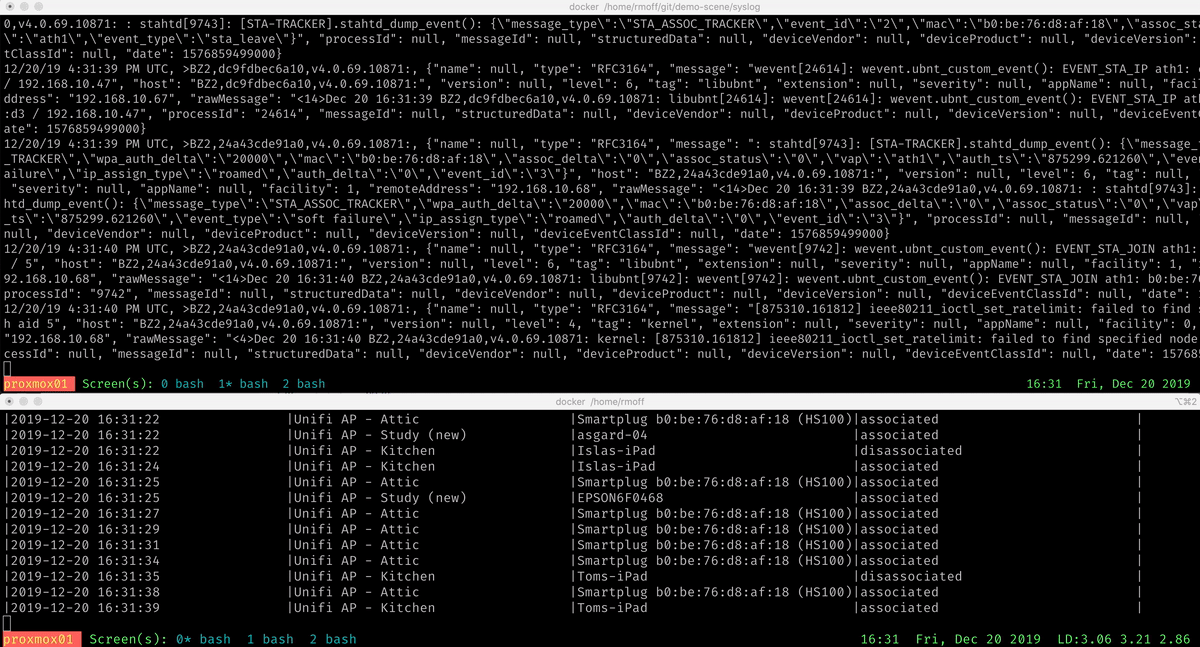
ksql> SELECT EVENT_TIME, AP_NAME, CLIENT_NAME, ACTION
FROM AP_CLIENT_EVENTS_ENRICHED
EMIT CHANGES;
+--------------------+-------------------+------------+--------------+
|EVENT_TIME |AP_NAME |CLIENT_NAME |ACTION |
+--------------------+-------------------+------------+--------------+
|2019-12-13 17:02:59 |Unifi AP - Kitchen |LB110 |associated |
|2019-12-13 17:07:59 |Unifi AP - Attic |asgard-04 |disassociated |
|2019-12-13 17:09:34 |Unifi AP - Kitchen |LB110 |disassociated |
|2019-12-13 17:16:37 |Unifi AP - Kitchen |Toms-iPad |associated |
…
Stateful aggregation in ksqlDB 🔗
As we saw above, ksqlDB can wrangling data for cleansing and enrichment, and it can join between Kafka topics. ksqlDB can also build stateful aggregations. Here’s an example of writing a ksqlDB table with the number of disassociation events per five-minute window:
ksql> CREATE TABLE AP_5MIN_AGG AS
SELECT TIMESTAMPTOSTRING(WINDOWSTART(),'yyyy-MM-dd HH:mm:ss','Europe/London') AS WINDOW_START_TS,
AP_NAME,
COUNT(*) AS EVENTS
FROM AP_CLIENT_EVENTS_ENRICHED
WINDOW TUMBLING (SIZE 5 MINUTES)
WHERE ACTION='disassociated'
GROUP BY AP_NAME
EMIT CHANGES;Now we can query it, in one of two ways:
-
"Push" query (receive a stream of events from the ksqlDB server as the state changes):
ksql> SELECT WINDOW_START_TS, AP_NAME, EVENTS FROM AP_5MIN_AGG EMIT CHANGES; +---------------------+-------------------------+-------+ |WINDOW_START_TS |AP_NAME |EVENTS | +---------------------+-------------------------+-------+ |2019-12-13 17:05:00 |Unifi AP - Attic |1 | |2019-12-13 17:05:00 |Unifi AP - Kitchen |1 | |2019-12-16 16:35:00 |Unifi AP - Study (new) |2 | |2019-12-20 16:30:00 |Unifi AP - Sitting Room |2 | |2019-12-20 16:30:00 |Unifi AP - Kitchen |3 | |2019-12-20 16:30:00 |Unifi AP - Attic |29 | |2019-12-20 16:35:00 |Unifi AP - Attic |1 | |2019-12-20 16:35:00 |Unifi AP - Sitting Room |2 | |2019-12-20 16:35:00 |Unifi AP - Study (new) |2 | … -
"Pull" query (fetch the current state from ksqlDB to the client)
ksql> SELECT ROWKEY, EVENTS FROM AP_5MIN_AGG WHERE ROWKEY='Unifi AP - Attic' AND WINDOWSTART = '2019-12-20T16:30:00'; +------------------+-------+ |ROWKEY |EVENTS | +------------------+-------+ |Unifi AP - Attic |29 | Query terminated ksql>ksqlDB has a REST API so external clients can also access the state held within it:
$ time curl -s -X POST \ http://proxmox01.moffatt.me:18088/query \ -H 'content-type: application/vnd.ksql.v1+json; charset=utf-8' \ -d '{"ksql":"SELECT ROWKEY, EVENTS FROM AP_5MIN_AGG WHERE ROWKEY=\'Unifi AP - Attic\' AND WINDOWSTART = \'2019-12-20T16:30:00\';"}' | jq -c '.[] | select(.row!=null).row.columns' 0.12 real 0.00 user 0.00 sys ["Unifi AP - Attic",29]
Anomoly detection with ksqlDB 🔗
Building on the above aggregation, we can populate a Kafka topic with a message any time there are more than ten disassociation events for a given access point in a five minute window:
ksql> CREATE TABLE AP_ALERTS WITH (KAFKA_TOPIC='ap_alerts_01') AS
SELECT WINDOW_START_TS, AP_NAME, EVENTS
FROM AP_5MIN_AGG
WHERE EVENTS >10
EMIT CHANGES;If we don’t want to store the intermediate aggregate state then we could rewrite this as a single table query using the GROUP BY… HAVING syntax:
ksql> CREATE TABLE AP_ALERTS WITH (KAFKA_TOPIC='ap_alerts_01') AS
SELECT TIMESTAMPTOSTRING(WINDOWSTART(),'yyyy-MM-dd HH:mm:ss','Europe/London') AS WINDOW_START_TS,
AP_NAME,
COUNT(*) AS EVENTS
FROM AP_CLIENT_EVENTS_ENRICHED
WINDOW TUMBLING (SIZE 5 MINUTES)
WHERE ACTION='disassociated'
GROUP BY AP_NAME
HAVING COUNT(*)> 10
EMIT CHANGES;However we write it, the result is just a Kafka topic that backs the ksqlDB table. This means that any alerting app that can be driven by a Kafka topic can be hooked up to this:
ksql> PRINT ap_alerts_01;
Format:AVRO
12/17/19 9:12:16 AM UTC, Unifi AP - Kitcheno@, {"WINDOW_START_TS": "2019-12-17 09:10:00", "AP_NAME": "Unifi AP - Kitchen", "EVENTS": 16}
12/20/19 4:34:42 PM UTC, Unifi AP - Attico$$�@, {"WINDOW_START_TS": "2019-12-20 16:30:00", "AP_NAME": "Unifi AP - Attic", "EVENTS": 29}Visualising the relationship between Access Points and Clients 🔗
Having built this streaming pipeline in ksqlDB that takes the raw Syslog and generates a Kafka topic with a list of Access Points events, we can also use this to stream into Neo4j:
CREATE SINK CONNECTOR SINK_NEO4J_UNIFI_AP_01 WITH (
'connector.class' = 'streams.kafka.connect.sink.Neo4jSinkConnector',
'key.converter' = 'org.apache.kafka.connect.storage.StringConverter',
'topics' = 'AP_CLIENT_EVENTS_ENRICHED',
'neo4j.server.uri' = 'bolt://neo4j:7687',
'neo4j.authentication.basic.username' = 'neo4j',
'neo4j.authentication.basic.password' = 'connect',
'neo4j.topic.cypher.AP_CLIENT_EVENTS_ENRICHED' = 'MERGE (a:AP{Name: event.AP_NAME, IP: event.AP_IP}) MERGE (c:Client{Name: event.CLIENT_NAME, MAC: event.CLIENT_MAC}) MERGE (c)-[:INTERACTED_WITH {action: event.ACTION}]->(a)'
); With the data in Neo4j it’s easy to query it for the association patterns of a specific device:
MATCH (n:Client {Name:'asgard-04'})-[rel :INTERACTED_WITH ]->(a:AP) RETURN n,a,rel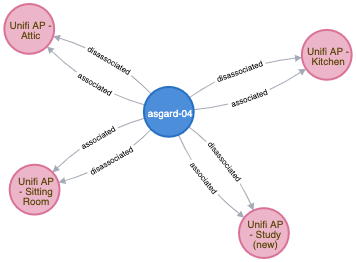
You can also look at the pattern across numerous devices. Here you can visually identify devices that are probably statically located in my house and only connect to a single AP, and others that roam across all of them.
MATCH (n:Client )-[rel :INTERACTED_WITH {action:'associated'}]->(a:AP) RETURN n,a,rel 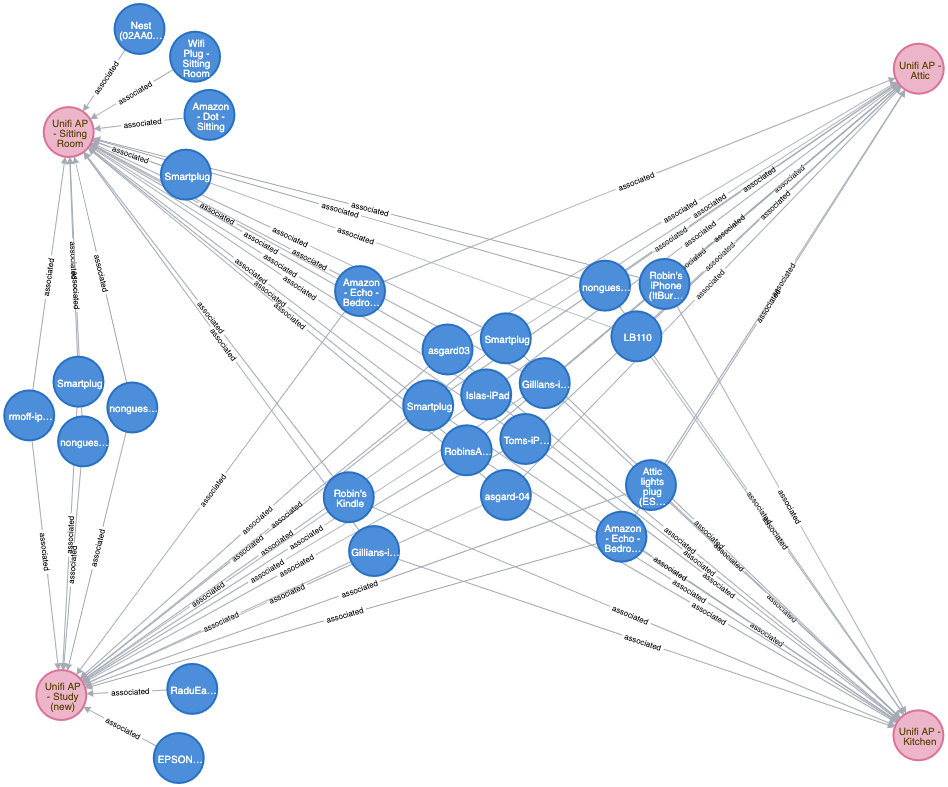
Sounds interesting, right? 🔗
-
You can find all the code to run this on GitHub.
-
Head to https://ksqldb.io/quickstart.html to try the ksqlDB quickstart
-
Join the Confluent Community slack group at http://cnfl.io/slack and hang out on the #ksqldb channel