
This article is part of a series exploring Streaming ETL in practice. You can read about setting up the ingest of realtime events from a standard Oracle platform, and building streaming ETL using KSQL.
This post shows how we take data streaming in from an Oracle transactional system into Kafka, and simply stream it onwards into Elasticsearch. This is a common pattern, for enabling rapid search or analytics against data held in systems elsewhere.
We’ll use Kafka Connect to stream the Avro topics directly into Elasticsearch. Because we’re using Avro and the schema registry all of our Elasticsearch mappings will be created automagically and with the correct datatypes. You can read more about using Kafka Connect to build pipelines in an earlier blog series here: 1 2 3.
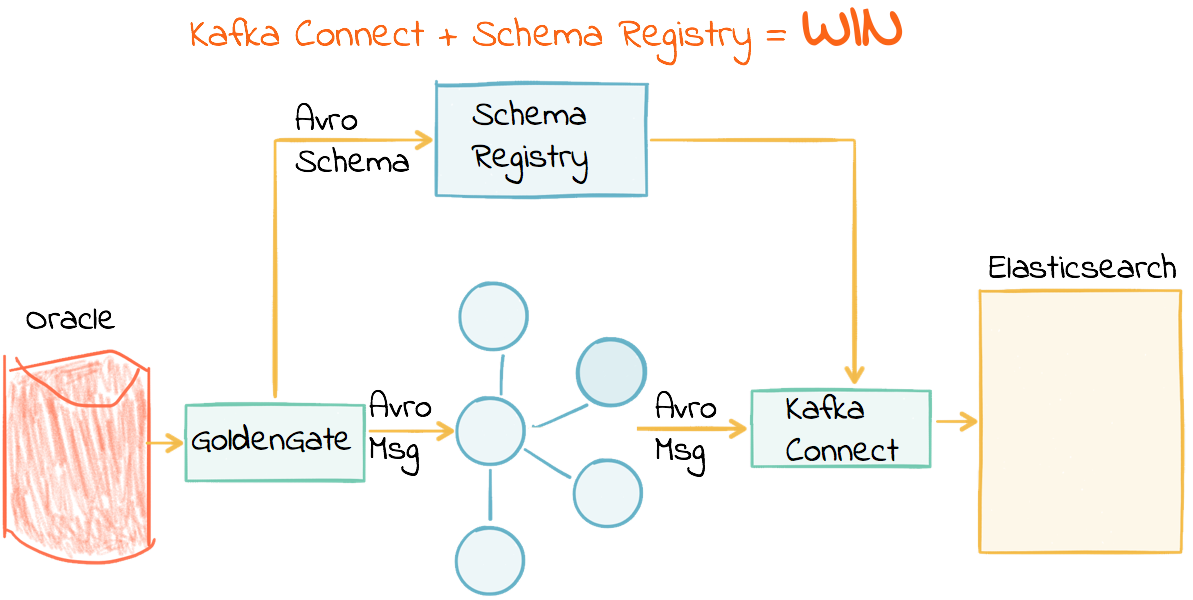
Create the Connect sink configuration file—note that we’re using Single Message Transforms (SMT) to set Timestamp datatype for op_ts and current_ts. We’re doing this to get around a limitation in the current release of GoldenGate in which date/timestamps are simply passed as strings. In order for Elasticsearch to work seamlessly, we want the Kafka Connect sink to pass the datatype as a timestamp—which using the SMT will enable.
Write this to /home/oracle/es-sink-soe-all.json
Load the sink:
confluent load es-sink-soe-all -d /home/oracle/es-sink-soe-all.json
Check status:
confluent status connectors| jq '.[]'| xargs -I{connector} confluent status {connector}| jq -c -M '[.name,.connector.state,.tasks[].state]|join(":|:")'| column -s : -t| sed 's/\"//g'| sort
If it’s FAILED then check the Connect log:
confluent log connect
Check Elasticsearch doc count:
curl -s "http://localhost:9200/soe.warehouses/_search" | jq '.hits.total'
1000
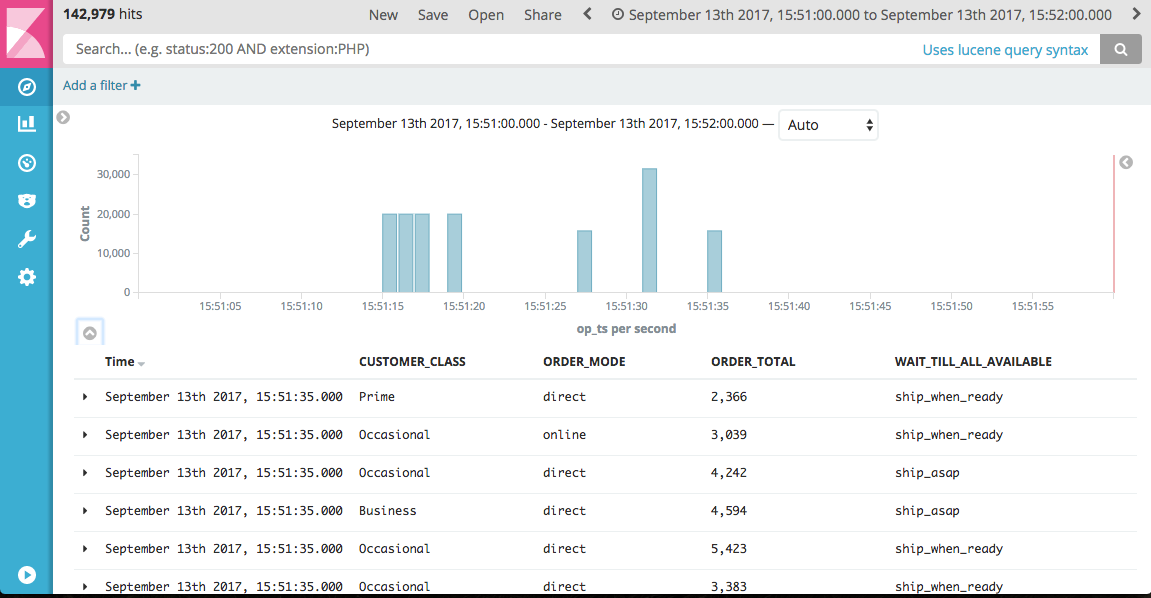
From here, with the data now in Elasticsearch, you can go and build Kibana dashboards to your heart’s content.
Here’s a very simple one of median/max Order values and counts over time, along with a histogram plot showing the distribution of order values.
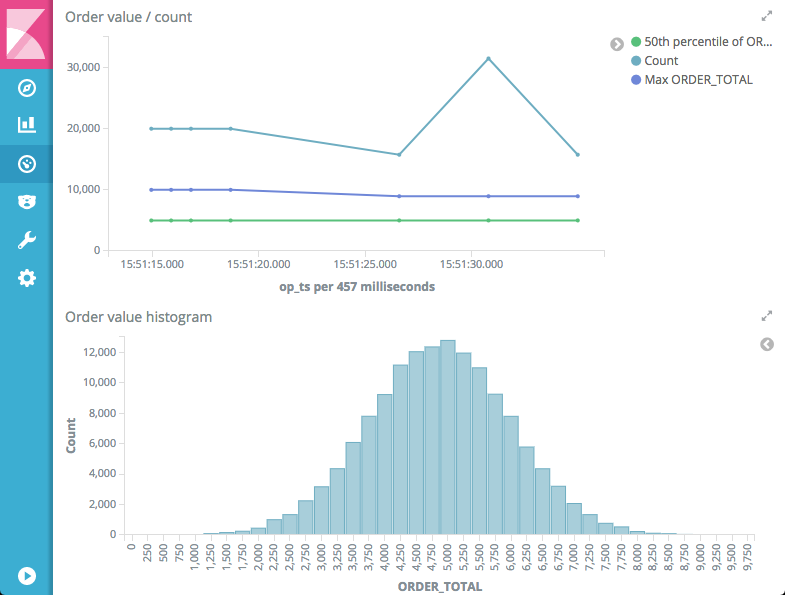
Remember that this is based on data streaming through from our source transactional system, with two particular benefits:
- We’ve not had to modify the source application at all to provide this data
- It’s extremely low latency, giving us a near-realtime analytics view of our data
To read more about this, and see the awesome KSQL in action, head over to the Confluent blog