Recently added to the oracledi project over at java.net is an adaptor enabling Oracle GoldenGate (OGG) to send data to Elasticsearch. This adds a powerful alternative to [micro-]batch extract via JDBC from Oracle to Elasticsearch, which I wrote about recently over at the Elastic blog.
Elasticsearch is a ‘document store’ widely used for both search and analytics. It’s something I’ve written a lot about (here and here for archives), as well as spoken about - preaching the good word, as it were, since the Elastic stack as a whole is very very good at what it does and a pleasure to work with. So, being able to combine that with my “day job” focus of Oracle is fun. Let’s get started!
From the adaptor page, download the zip to your machine. I’m using Oracle’s BigDataLite VM which already has GoldenGate installed and configured, and which I’ve also got Elasticsearch already on following on from this earlier post. If you’ve not got Elasticsearch already, head over to elastic.co to download it. I’m using version 2.3.1, installed in /opt/elasticsearch-2.3.1.
Ready … 🔗
Once you’ve got the OGG adaptor zip, you’ll want to unzip it – a word of advice here, specify the destination folder as there’s no containing root within the archive so you’ll end up with a mess of folder and files in amongst your download folder otherwise:
unzip OGG_elasticsearch_v1.0.zip -d /u01/OGG_elasticsearch_v1.0
Copy the provided .prm and .props files to your OGG dirprm folder:
cp /u01/OGG_elasticsearch_v1.0/dirprm/elasticsearch.props /u01/ogg-bd/dirprm/
cp /u01/OGG_elasticsearch_v1.0/dirprm/res.prm /u01/ogg-bd/dirprm/
Edit the elasticsearch.props (e.g. /u01/ogg/dirprm/elasticsearch.props) file to set:
-
gg.classpath, to pick up both the Elasticsearch jars and the OGG adaptor jar. On my installation this is :
gg.classpath=/opt/elasticsearch-2.3.1/lib/*:/u01/OGG_elasticsearch_v1.0/bin/ogg-elasticsearch-adapter-1.0.jar: -
gg.handler.elasticsearch.clusterName, which is the name of your elasticsearch cluster - if you don’t know it you can check with
[oracle@bigdatalite ~]$ curl -s localhost:9200|grep cluster_name "cluster_name" : "elasticsearch",So mine is the default - elasticsearch:
gg.handler.elasticsearch.clusterName=elasticsearch -
For gg.handler.elasticsearch.host and gg.handler.elasticsearch.port I left the defaults (localhost / 9300) unchanged - update these for your Elasticsearch instance as required. Note that Elasticsearch listens on two ports, with 9200 by default for HTTP traffic, and 9300 for Java clients which is what we’re using here.
Steady … 🔗
Run ggsci to add and start the replicat using the provided res configuration (res = Replicat, ElasticSearch, I’m guessing) and sample trail file (i.e. we don’t need a live extract running to try this thing out):
$ cd /u01/ogg-bd
$ rlwrap ./ggsci
Oracle GoldenGate Command Interpreter
Version 12.2.0.1.0 OGGCORE_12.2.0.1.0_PLATFORMS_151101.1925.2
Linux, x64, 64bit (optimized), Generic on Nov 10 2015 16:18:12
Operating system character set identified as UTF-8.
Copyright (C) 1995, 2015, Oracle and/or its affiliates. All rights reserved.
GGSCI (bigdatalite.localdomain) 1> start mgr
Manager started.
GGSCI (bigdatalite.localdomain) 2> add replicat res, exttrail AdapterExamples/trail/tr
REPLICAT added.
Go! 🔗
GGSCI (bigdatalite.localdomain) 3> start res
Sending START request to MANAGER ...
REPLICAT RES starting
Yay!
GGSCI (bigdatalite.localdomain) 5> info res
REPLICAT RES Initialized 2016-04-14 22:03 Status STOPPED
STOPPED? Oh …
Time for debug. Open up /u01/ogg-bd/ggserr.log, and the error (`Error loading shared library ggjava.dll) is nice and clear to see:
2016-04-14 22:04:25 INFO OGG-00987 Oracle GoldenGate Command Interpreter: GGSCI command (oracle): start res.
2016-04-14 22:04:25 INFO OGG-00963 Oracle GoldenGate Manager, mgr.prm: Command received from GGSCI on host [127.0.0.1]:13379 (START REPLICAT RES ).
2016-04-14 22:04:25 INFO OGG-00960 Oracle GoldenGate Manager, mgr.prm: Access granted (rule #6).
2016-04-14 22:04:25 INFO OGG-00975 Oracle GoldenGate Manager, mgr.prm: REPLICAT RES starting.
2016-04-14 22:04:25 INFO OGG-00995 Oracle GoldenGate Delivery, res.prm: REPLICAT RES starting.
2016-04-14 22:04:25 INFO OGG-03059 Oracle GoldenGate Delivery, res.prm: Operating system character set identified as UTF-8.
2016-04-14 22:04:25 INFO OGG-02695 Oracle GoldenGate Delivery, res.prm: ANSI SQL parameter syntax is used for parameter parsing.
2016-04-14 22:04:25 ERROR OGG-02554 Oracle GoldenGate Delivery, res.prm: Error loading shared library ggjava.dll: 2 No such file or directory.
2016-04-14 22:04:25 ERROR OGG-01668 Oracle GoldenGate Delivery, res.prm: PROCESS ABENDING.
But hang on … ggjava.dll ? dll? This is Linux, not Windows.
So, a quick change to the prm is in order, switching .dll for .so:
[oracle@bigdatalite ogg-bd]$ diff dirprm/res.prm dirprm/res.prm.bak
5c5
< TARGETDB LIBFILE libggjava.so SET property=dirprm/elasticsearch.props
---
> TARGETDB LIBFILE ggjava.dll SET property=dirprm/elasticsearch.props
Second time lucky? 🔗
Redefine the replicat:
GGSCI (bigdatalite.localdomain) 7> delete res
Deleted REPLICAT RES.
GGSCI (bigdatalite.localdomain) 8> add replicat res, exttrail AdapterExamples/trail/tr
REPLICAT added.
And start it again:
GGSCI (bigdatalite.localdomain) 9> start res
Sending START request to MANAGER ...
REPLICAT RES starting
Now it looks better:
GGSCI (bigdatalite.localdomain) 14> info res
REPLICAT RES Last Started 2016-04-14 22:10 Status RUNNING
Checkpoint Lag 00:00:00 (updated 00:00:02 ago)
Process ID 15101
Log Read Checkpoint File AdapterExamples/trail/tr000000000
2015-11-05 18:45:39.000000 RBA 5660
Result! 🔗
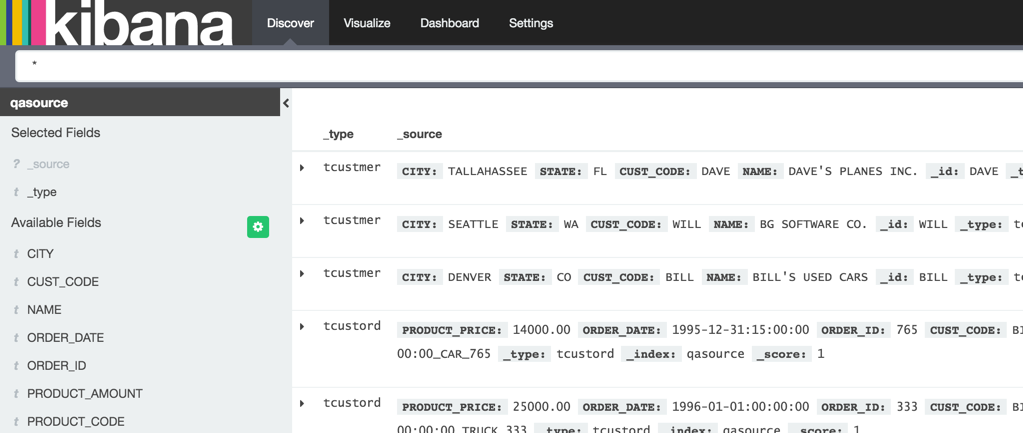
Let’s check out what’s happened in Elasticsearch. The console log looks promising, showing that an index with two mappings has been created:
[2016-04-14 22:10:08,709][INFO ][cluster.metadata ] [Abner Jenkins] [qasource] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [tcustmer, tcustord]
[2016-04-14 22:10:09,458][INFO ][cluster.routing.allocation] [Abner Jenkins] Cluster health status changed from [RED] to [YELLOW] (reason: [shards started [[qasource][4]] ...]).
[2016-04-14 22:10:09,488][INFO ][cluster.metadata ] [Abner Jenkins] [qasource] update_mapping [tcustmer]
[2016-04-14 22:10:09,658][INFO ][cluster.metadata ] [Abner Jenkins] [qasource] update_mapping [tcustord]
We can confirm that with the Elasticsearch REST API:
$ curl --silent -XGET http://localhost:9200/_cat/indices?pretty=true
yellow open qasource 5 1 8 6 19.6kb 19.6kb
And see how many documents (“rows”) have been loaded (8):
$ curl -s -XGET 'http://localhost:9200/qasource/_search?search_type=count&pretty=true'
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 8,
"max_score" : 0.0,
"hits" : [ ]
}
}
You can even see the mappings (“schema”) defined within each index:
$ curl -XGET 'http://localhost:9200/_mapping?pretty=true'
{
".kibana" : {
"mappings" : {
"config" : {
"properties" : {
"buildNum" : {
"type" : "string",
"index" : "not_analyzed"
}
}
}
}
},
"qasource" : {
"mappings" : {
"tcustord" : {
"properties" : {
"CUST_CODE" : {
"type" : "string"
},
"ORDER_DATE" : {
"type" : "string"
},
"ORDER_ID" : {
"type" : "string"
[...]
All this faffing about with curl is fine, but if you’re doing proper poking with Elasticsearch you may well find kopf handy:
It’s easy to install: (modify the path if your Elasticsearch binary is in a different location):
/opt/elasticsearch-2.3.1/bin/plugin install lmenezes/elasticsearch-kopf
After installation, restart Elasticsearch and then go to http://localhost:9200/_plugin/kopf
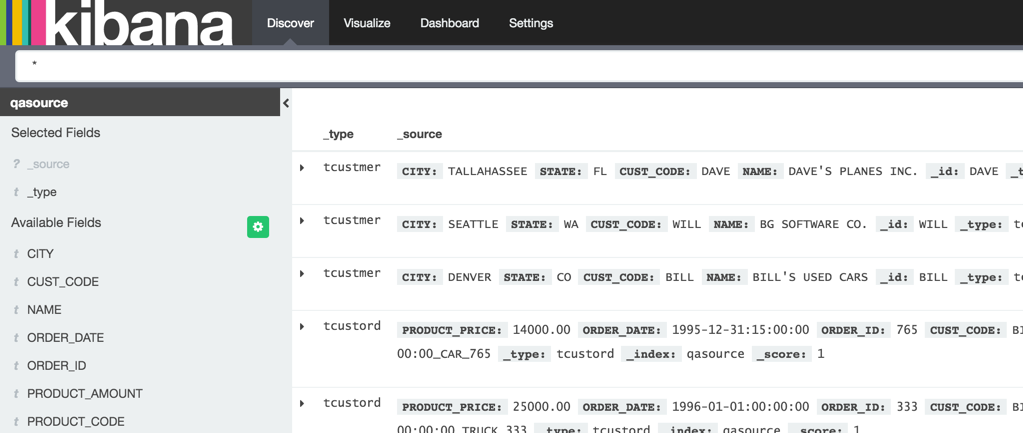
If you’re using Elasticsearch, you may well be doing so for the whole Elastic experience, using Kibana to view the data:
and even start doing quick profiling:
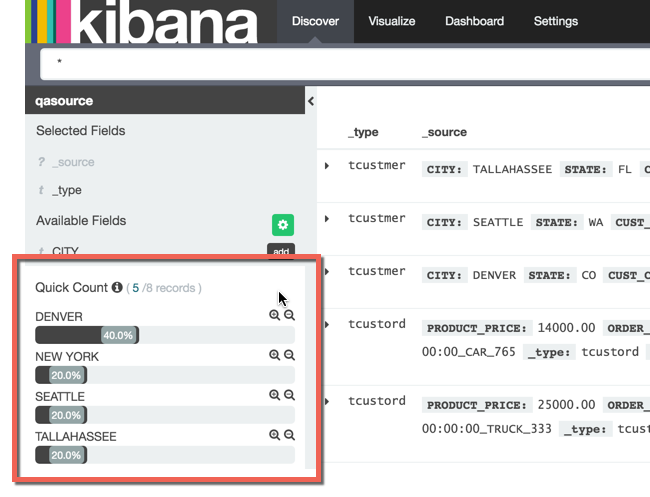
One issue with the data that’s come through in this example is that it is all string - even the dates and numerics (AMOUNT, PRICE), which makes instant-analysis in Kibana less possible.
Streaming data from Oracle to Elasticsearch
Now that we’ve tested and proven the replicat load into Elasticsearch, let’s do the full end-to-end. I’m going to use the same Extract as the BigDataLite Oracle by Example (you can see my notes on it here if you’re interested).
Reset & recreate the Extract, in the first OGG instance (/u01/ogg)
$ cd /u01/ogg/
$ rlwrap ./ggsci
GGSCI (bigdatalite.localdomain as system@cdb/CDB$ROOT) 1> obey dirprm/reset_bigdata.oby
[...]
GGSCI (bigdatalite.localdomain as system@cdb/CDB$ROOT) 2> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
GGSCI (bigdatalite.localdomain) 3> obey dirprm/bigdata.oby
[...]
GGSCI (bigdatalite.localdomain as system@cdb/CDB$ROOT) 9> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
EXTRACT RUNNING EMOV 00:00:03 00:00:00
Now define a new replicat parameter file, over in the second OGG instance (that we used above for the res test):
cat > /u01/ogg-bd/dirprm/relastic.prm <<EOF
REPLICAT relastic
TARGETDB LIBFILE libggjava.so SET property=dirprm/elasticsearch.props
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 10000
MAP orcl.moviedemo.movie TARGET orcl.moviedemo.movie;
EOF
Remove the previous replicat (res) just to keep things clear:
$ cd /u01/ogg-bd
$ rlwrap ./ggsci
Oracle GoldenGate Command Interpreter
Version 12.2.0.1.0 OGGCORE_12.2.0.1.0_PLATFORMS_151101.1925.2
Linux, x64, 64bit (optimized), Generic on Nov 10 2015 16:18:12
Operating system character set identified as UTF-8.
Copyright (C) 1995, 2015, Oracle and/or its affiliates. All rights reserved.
GGSCI (bigdatalite.localdomain) 2> stop res
Sending STOP request to REPLICAT RES ...
Request processed.
GGSCI (bigdatalite.localdomain) 3> delete res
Deleted REPLICAT RES.
GGSCI (bigdatalite.localdomain) 4> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
Add the new one (relastic):
GGSCI (bigdatalite.localdomain) 1> add replicat relastic, exttrail /u01/ogg/dirdat/tm
REPLICAT added.
And start it:
GGSCI (bigdatalite.localdomain) 2> start relastic
Sending START request to MANAGER ...
REPLICAT RELASTIC starting
GGSCI (bigdatalite.localdomain) 4> info relastic
REPLICAT RELASTIC Last Started 2016-04-14 22:55 Status RUNNING
Checkpoint Lag 00:00:00 (updated 00:00:04 ago)
Process ID 17564
Log Read Checkpoint File /u01/ogg/dirdat/tm000000000
First Record RBA 1406
If we head over to the Elasticsearch, we’ll see that …
$ curl --silent -XGET http://localhost:9200/_cat/indices?pretty=true
yellow open qasource 5 1 8 6 19.6kb 19.6kb
… nothing’s changed! Because, of course, nothing’s changed on the source Oracle table that the Extract is set up against.
Let’s rectify that:
$ rlwrap sqlplus system/welcome1@orcl
SQL*Plus: Release 12.1.0.2.0 Production on Thu Apr 14 23:01:57 2016
Copyright (c) 1982, 2014, Oracle. All rights reserved.
Last Successful login time: Thu Apr 14 2016 22:48:35 +01:00
Connected to:
Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production
With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options
SQL> INSERT INTO "MOVIEDEMO"."MOVIE" (MOVIE_ID, TITLE, YEAR, BUDGET, GROSS, PLOT_SUMMARY) VALUES ('42444', 'never gonna', '2014', '500000', '20000000', 'give you up');
1 row created.
SQL> COMMIT;
Commit complete.
Check Elasticsearch again:
$ curl --silent -XGET http://localhost:9200/_cat/indices?pretty=true
yellow open qasource 5 1 8 6 19.6kb 19.6kb
yellow open moviedemo 5 1 1 0 4.5kb 4.5kb
Much better - a new index! We’ve got a new index because the replicat is handling a different schema this time - moviedemo, not qasource.
We can look at the data in the index directly:
$ curl -XGET 'http://localhost:9200/moviedemo/_search?q=*&pretty=true'
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [ {
"_index" : "moviedemo",
"_type" : "movie",
"_id" : "42444",
"_score" : 1.0,
"_source" : {
"PLOT_SUMMARY" : "give you up",
"YEAR" : "2014",
"MOVIE_ID" : "42444",
"BUDGET" : "500000",
"TITLE" : "never gonna",
"GROSS" : "20000000"
}
} ]
}
}
You’ll note that the primary key (MOVIE_ID) has been correctly identied as the unique document _id field. The _id is now where things begin to get interesting, because this field enables the new OGG-Elasticsearch adaptor to apparently perform “UPSERT” on documents that already exist.
To doublecheck this apparent method of handling of the data, I first wanted to validate what was coming through from OGG in terms of the data flowing through from the extract. To do this I hooked up a second replicat, to Kafka and on to Logstash into Elasticseach (using this method), and then compared the doc count in the two relevant indices (or strictly speaking, the mapping types, corresponding to each index).
To start with, I deleted all my Elasticsearch data, as this shows:
$ curl "localhost:9200/*/_search?search_type=count&pretty=true" -d '{
"aggs": {
"count_by_type": {
"terms": {
"field": "_type"
}
}
}
}'
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"hits" : {
"total" : 0,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"count_by_type" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ]
}
}
}
Then I insert a row on "MOVIEDEMO"."MOVIE" in Oracle (having previously truncated it):
SQL> INSERT INTO "MOVIEDEMO"."MOVIE" (MOVIE_ID, TITLE, YEAR, BUDGET, GROSS, PLOT_SUMMARY) VALUES ('1', 'never gonna', '2014', '500000', '20000000', 'give you up');
1 row created.
SQL> commit;
Commit complete.
and see it shows up in both Elasticsearch indices:
$ curl "localhost:9200/*/_search?search_type=count&pretty=true" -d '{
"aggs": {
"count_by_type": {
"terms": {
"field": "_type"
}
}
}
}'
[...]
}, {
"key" : "logs",
"doc_count" : 1
}, {
"key" : "movie",
"doc_count" : 1
logsis the index mapping loaded through OGG –> Kafka –> Logstash –> Elasticsearchmovieis the index mapping loaded through the new adaptor, OGG –> Elasticsearch
So far, so good. Now, let’s add a second row in Oracle:
SQL> INSERT INTO "MOVIEDEMO"."MOVIE" (MOVIE_ID, TITLE, YEAR, BUDGET, GROSS, PLOT_SUMMARY) VALUES ('2', 'foo', '2014', '500000', '20000000', 'bar');
1 row created.
SQL> commit;
Commit complete.
Both indices match count:
"buckets" : [ {
"key" : "logs",
"doc_count" : 2
}, {
"key" : "movie",
"doc_count" : 2
}, {
What about an update?
SQL> UPDATE "MOVIEDEMO"."MOVIE" SET TITLE ='Foobar' where movie_id = 1;
1 row updated.
SQL> commit;
Commit complete.
Hmmmm…
"buckets" : [ {
"key" : "logs",
"doc_count" : 3
}, {
"key" : "movie",
"doc_count" : 2
}, {
The index loaded from the OGG-Elasticsearch Adaptor has only two documents still, whilst the other route has three. If we look at what’s in the first of these (movie, loaded by OGG-Elasticsearch) for movie_id=1:
[oracle@bigdatalite ogg-bd]$ curl -XGET 'http://localhost:9200/moviedemo/_search?q=_id=1&pretty=true'
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.014065012,
"hits" : [ {
"_index" : "moviedemo",
"_type" : "movie",
"_id" : "1",
"_score" : 0.014065012,
"_source" : {
"PLOT_SUMMARY" : "give you up",
"YEAR" : "2014",
"MOVIE_ID" : "1",
"BUDGET" : "500000",
"TITLE" : "Foobar",
"GROSS" : "20000000"
}
} ]
}
}
You can see it’s the latest version of the row (TITLE=Foobar). In the second index, loaded from the change record sent to Kafka and then on through Logstash, there are both the before and after record for this key:
}
[oracle@bigdatalite ogg-bd]$ curl -XGET 'http://localhost:9200/logstash*/_search?q=*&pretty=true'
[...]
"_source" : {
"table" : "ORCL.MOVIEDEMO.MOVIE",
"op_type" : "I",
"op_ts" : "2016-04-14 22:34:43.000000",
"current_ts" : "2016-04-14T23:34:45.131000",
"pos" : "00000000000000003514",
"primary_keys" : [ "MOVIE_ID" ],
"tokens" : { },
"before" : null,
"after" : {
"MOVIE_ID" : "1",
"MOVIE_ID_isMissing" : false,
"TITLE" : "never gonna",
"TITLE_isMissing" : false,
[...]
"_source" : {
"table" : "ORCL.MOVIEDEMO.MOVIE",
"op_type" : "U",
"op_ts" : "2016-04-14 22:39:37.000000",
"current_ts" : "2016-04-14T23:39:39.583000",
"pos" : "00000000000000004097",
"primary_keys" : [ "MOVIE_ID" ],
"tokens" : { },
"before" : {
[...]
"TITLE" : "never gonna",
[...]
},
"after" : {
[...]
"TITLE" : "Foobar",
[...]
Finally, if I delete a record in Oracle:
SQL> delete from "MOVIEDEMO"."MOVIE" where MOVIE_ID = 1;
1 row deleted.
SQL> commit;
Commit complete.
My document counts reflect what I’d expect – the OGG-Elasticsearch adaptor deleted the record from Elasticsearch, whilst the Kafka route just recorded another change record, of op_type='D' this time.
"key" : "logs",
"doc_count" : 4
}, {
"key" : "movie",
"doc_count" : 1
Summary
This adaptor is a pretty smart way of mirroring a table’s contents from one of the many RDBMS that GoldenGate supports as an extract source, into Elasticsearch.
If you want to retain history of changed records, then using OGG->Kafka->Logstash->Elasticsearch is an option.
And, if you don’t have the spare cash for OGG, you can use Logstash’s JDBC input mechanism to pull data periodically from your RDBMS. This has the additional benefit of being able to specify custom SQL queries with joins etc - useful when pulling in denormalised datasets into Elasticsearch for analytics.