The Oracle by Example (ObE) here demonstrating how to use Goldengate to replicate transactions big data targets such as HDFS is written for the BigDataLite 4.2.1, and for me didn’t work on the current latest version, 4.4.0.
The OBE (and similar Hands On Lab PDF) assume the presence of pmov.prm and pmov.properties in /u01/ogg/dirprm/. On BDL 4.4 there’s only the extract to from Oracle configuration, emov.
Fortunately it’s still possible to run this setup out of the box in BDL 4.4, with bells on because it includes Kafka too. And, who doesn’t like a bit of Kafka nowadays?
Getting it running 🔗
-
Set the Oracle extract running (as per the OBE/HOL instructions).
I’m using the ever-awesome
rlwrapso that if I mistype stuff inggsciI can just arrow up/down to cycle through command history.[oracle@bigdatalite ~]$ cd /u01/ogg [oracle@bigdatalite ogg]$ rlwrap ./ggsci Oracle GoldenGate Command Interpreter for Oracle Version 12.2.0.1.0 OGGCORE_12.2.0.1.0_PLATFORMS_151101.1925.2_FBO Linux, x64, 64bit (optimized), Oracle 12c on Nov 11 2015 03:53:23 Operating system character set identified as UTF-8. Copyright (C) 1995, 2015, Oracle and/or its affiliates. All rights reserved. GGSCI (bigdatalite.localdomain) 1> obey dirprm/bigdata.obyNote that the output differs from the OBE/HOL screenshot, with only the
emovextract listed now:GGSCI (bigdatalite.localdomain as system@cdb/CDB$ROOT) 9> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING EXTRACT RUNNING EMOV 04:00:10 00:00:01Press Ctrl-D to exit
ggsci -
Launch
ggsciagain, but from the/u01/ogg-bdfolder this time. Run the same-named bigdata obey file, but note that it’s a different set of instructions (because we’re now in/u01/ogg-bd, rather than/u01/ogg)[oracle@bigdatalite ogg]$ cd /u01/ogg-bd [oracle@bigdatalite ogg-bd]$ rlwrap ./ggsci Oracle GoldenGate Command Interpreter Version 12.2.0.1.0 OGGCORE_12.2.0.1.0_PLATFORMS_151101.1925.2 Linux, x64, 64bit (optimized), Generic on Nov 10 2015 16:18:12 Operating system character set identified as UTF-8. Copyright (C) 1995, 2015, Oracle and/or its affiliates. All rights reserved. GGSCI (bigdatalite.localdomain) 1> obey dirprm/bigdata.obyLooking at what’s running we can see two replicats:
GGSCI (bigdatalite.localdomain) 8> INFO ALL Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING REPLICAT RUNNING RKAFKA 00:00:00 00:00:01 REPLICAT RUNNING RMOV 00:00:00 00:00:02Poking around the Kafka parameters we can see the configured topic for the transactions and schema. For full details about the Kafka handler see the documentation.
[oracle@bigdatalite ogg-bd]$ cat dirprm/kafka.props gg.handlerlist = kafkahandler gg.handler.kafkahandler.type = kafka gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties gg.handler.kafkahandler.TopicName =oggtopic gg.handler.kafkahandler.format =avro_op gg.handler.kafkahandler.SchemaTopicName=mySchemaTopic gg.handler.kafkahandler.BlockingSend =false gg.handler.kafkahandler.includeTokens=false gg.handler.kafkahandler.mode =tx #gg.handler.kafkahandler.maxGroupSize =100, 1Mb #gg.handler.kafkahandler.minGroupSize =50, 500Kb
Testing it out 🔗
Using the Kafka console shell we can observe what Oracle GoldenGate sends to Kafka:
[oracle@bigdatalite dirprm]$ kafka-console-consumer --zookeeper localhost:2181 --topic oggtopic
In a separate session (or even better, in the same session but using screen as in the demo below) modify data in the MOVIEDEMO.MOVIE table on Oracle. You should see the change come through to Kafka after a few moments.
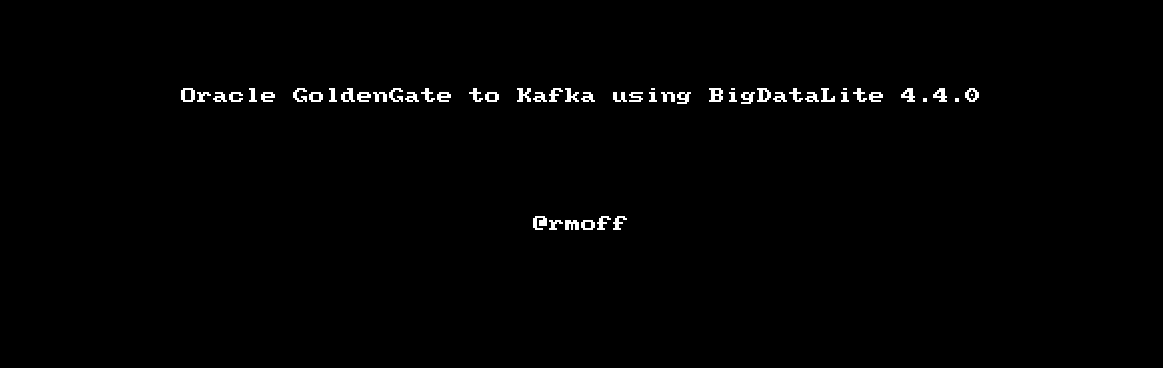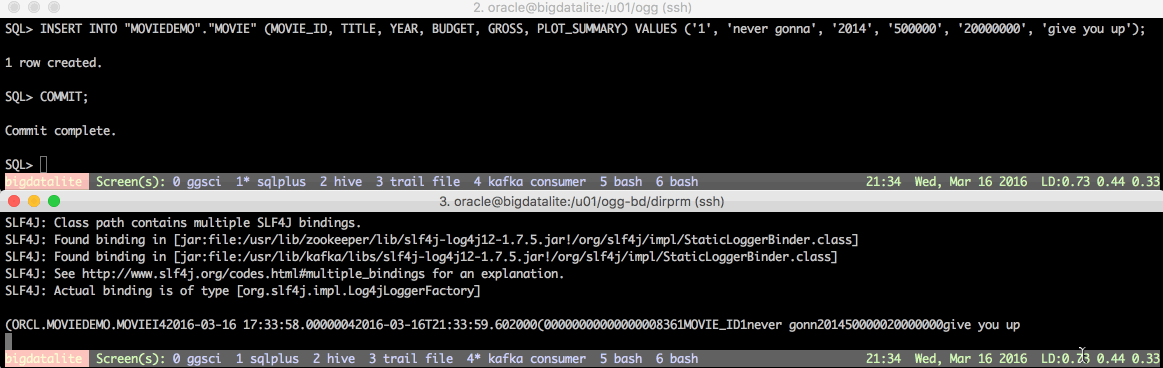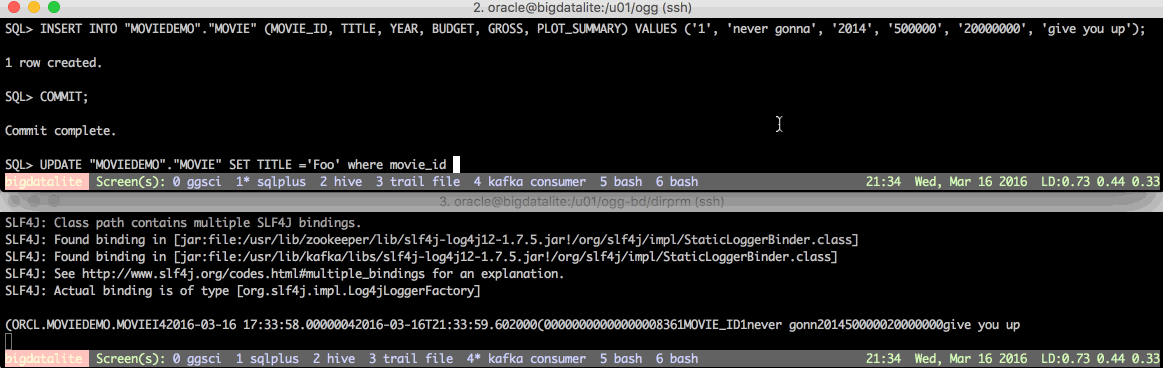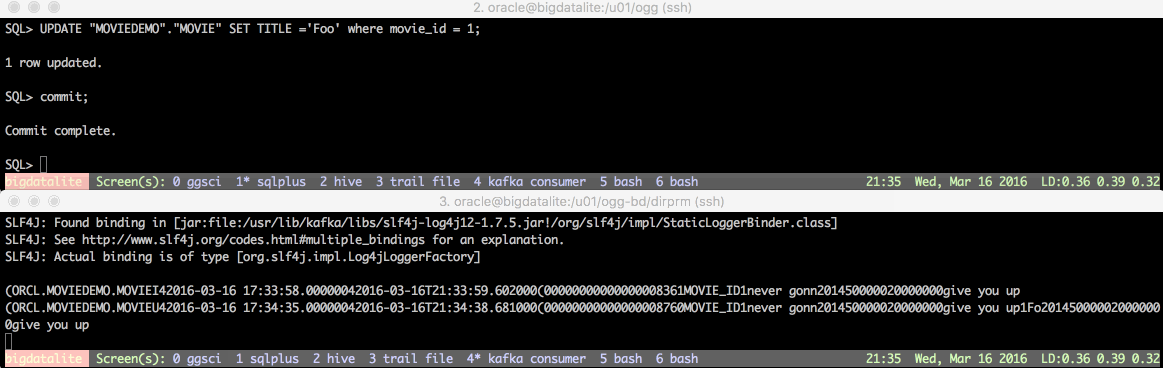
Always RTFM… 🔗
The manual? That thing that explains how things work, and what problems to watch out for? Yeah… about that…
So I got the Kafka bit working above and was happy, it worked, it was neat. But, for the life of me I couldn’t get the transactions to appear in Hive. They appeared in the HDFS file when I hadoop fs -cat’d it, they showed up in the Hue data browser … but not in Hive. Was this some weird bug/issue involving new lines? What was going on?
Here’s what I saw in HDFS. Note the last line, 22:32:21:
[oracle@bigdatalite ogg]$ sudo su - hdfs -c "hadoop fs -cat /user/odi/hive/orcl.moviedemo.movie/*"
D2016-03-16 22:14:47.0000001Foo201450000020000000give you up
D2016-03-16 22:14:47.0000002never gonna201450000020000000give you up
D2016-03-16 22:14:47.0000003never gonna201450000020000000give you up
D2016-03-16 22:14:47.0000004never gonna201450000020000000give you up
I2016-03-16 22:27:18.0000002Sharknadozz201450000020000000Flying sharks attack city
I2016-03-16 22:32:21.0000004242never gonna201450000020000000give you up
[oracle@bigdatalite ogg]$
And this is what I saw in Hive - only five of the six rows of data:
hive> select * from movie_updates;
OK
D 2016-03-16 22:14:47 1 Foo 2014 500000 20000000 give you up
D 2016-03-16 22:14:47 2 never gonna 2014 500000 20000000 give you up
D 2016-03-16 22:14:47 3 never gonna 2014 500000 20000000 give you up
D 2016-03-16 22:14:47 4 never gonna 2014 500000 20000000 give you up
I 2016-03-16 22:27:18 2 Sharknadozz 2014 500000 20000000 Flying sharks attack city
Time taken: 0.087 seconds, Fetched: 5 row(s)
Turns out the manual spells this out pretty darn clearly in a section cunningly named Common Pitfalls it notes that
HDFS blocks under construction are not always visible to analytic tools.
And since I’m noodling around with a few rows of data here and there (nowhere near the 128MB HDFS block size), this was the very cause of my issue. A workaround to prove that I wasn’t going mad? Restart the GoldenGate replicat with the rmov.properties file changed to close the HDFS file periodically:
gg.handler.hdfs.fileRollInterval=30s
Obviously this has performance implications in a real-life implementation, but for proving out functionality, it saved me from complete insanity :-)
Sidenote - error in reset_bigdata.oby? 🔗
I might be missing something here, but it looks like there’s a minor fubar in /u01/ogg-bd/dirprm/reset_bigdata.oby:
start mgr
stop rmov
stop rkafka
shell sleep 5
delete rmov
stop rkafka
[...]
That second stop rkafka I’m guessing should be delete rkafka?
Logstash 🔗
I’m a long-time fan of the Elastic stack, and Logstash has an input plugin for Kafka, so let’s see if that can fit the jigsaw here too.
The data from GoldenGate is serialised using Avro. The schema is put by Goldengate onto a separate Kafka topic, mySchemaTopic. There’s probably a more proper way to get it but I dumped it to file thus:
kafka-console-consumer --zookeeper localhost:2181 --topic mySchemaTopic --from-beginning > ~/schema.avsc
Here’s a snippet of what it looks like:
{
"type" : "record",
"name" : "MOVIE",
"namespace" : "ORCL.MOVIEDEMO",
"fields" : [ {
"name" : "table",
"type" : "string"
}, {
"name" : "op_type",
"type" : "string"
}, {
[...]
Logstash can use the Avro codec to deserialise the data it’s going to be pulling from Kafka. It isn’t part of the standard distribution, so needs installing thus:
/opt/logstash-2.2.0/bin/plugin install logstash-codec-avro
Now we can build our Logstash config file:
input {
kafka {
zk_connect => 'bigdatalite:2181'
topic_id => 'oggtopic'
codec =>
avro {
schema_uri => "/home/oracle/schema.avsc"
}
# These next two options will force logstash to pull
# the entire contents of the topic.
reset_beginning => 'true'
auto_offset_reset => 'smallest'
}
}
output {
stdout {
codec => rubydebug
}
}
Note the syntax for referencing the Avro codec - if you follow the syntax in the docs it will fail with the error undefined method `decode' for ["avro". Thanks to this Stackoverflow post for help on fixing that problem.
Because we’ve told Logstash to use the stdout output plugin we can see everything that it’s reading from Kafka, and the rubydebug codec ensures that field names etc are nicely formatted. You can see from this the point of the Avro schema - it supports the idea of records deletions, as in this one:
[oracle@bigdatalite logstash-2.2.0]$ /opt/logstash-2.2.0/bin/logstash -f ~/logstash-kafka-stdout.conf
Settings: Default pipeline workers: 4
Logstash startup completed
{
"table" => "ORCL.MOVIEDEMO.MOVIE",
"op_type" => "D",
"op_ts" => "2016-03-16 22:14:47.000000",
"current_ts" => "2016-03-16T22:26:29.515000",
"pos" => "00000000010000002172",
"primary_keys" => [
[0] "MOVIE_ID"
],
"tokens" => {},
"before" => {
"MOVIE_ID" => "1",
"MOVIE_ID_isMissing" => false,
"TITLE" => "Foo",
"TITLE_isMissing" => false,
"YEAR" => "2014",
"YEAR_isMissing" => false,
"BUDGET" => "500000",
"BUDGET_isMissing" => false,
"GROSS" => "20000000",
"GROSS_isMissing" => false,
"PLOT_SUMMARY" => "give you up",
"PLOT_SUMMARY_isMissing" => false
},
"after" => nil,
"@version" => "1",
"@timestamp" => "2016-03-16T22:53:48.675Z"
}
as well as inserts and updates:
{
"table" => "ORCL.MOVIEDEMO.MOVIE",
"op_type" => "I",
"op_ts" => "2016-03-16 22:32:21.000000",
"current_ts" => "2016-03-16T22:32:22.941000",
"pos" => "00000000010000003090",
"primary_keys" => [
[0] "MOVIE_ID"
],
"tokens" => {},
"before" => nil,
"after" => {
"MOVIE_ID" => "4242",
"MOVIE_ID_isMissing" => false,
"TITLE" => "never gonna",
"TITLE_isMissing" => false,
"YEAR" => "2014",
"YEAR_isMissing" => false,
"BUDGET" => "500000",
"BUDGET_isMissing" => false,
"GROSS" => "20000000",
"GROSS_isMissing" => false,
"PLOT_SUMMARY" => "give you up",
"PLOT_SUMMARY_isMissing" => false
},
"@version" => "1",
"@timestamp" => "2016-03-16T23:08:58.804Z"
}
{
"table" => "ORCL.MOVIEDEMO.MOVIE",
"op_type" => "U",
"op_ts" => "2016-03-16 23:09:58.000000",
"current_ts" => "2016-03-16T23:10:01.023000",
"pos" => "00000000010000003700",
"primary_keys" => [
[0] "MOVIE_ID"
],
"tokens" => {},
"before" => {
"MOVIE_ID" => "4242",
"MOVIE_ID_isMissing" => false,
"TITLE" => "never gonna",
"TITLE_isMissing" => false,
"YEAR" => "2014",
"YEAR_isMissing" => false,
"BUDGET" => "500000",
"BUDGET_isMissing" => false,
"GROSS" => "20000000",
"GROSS_isMissing" => false,
"PLOT_SUMMARY" => "give you up",
"PLOT_SUMMARY_isMissing" => false
},
"after" => {
"MOVIE_ID" => "4242",
"MOVIE_ID_isMissing" => false,
"TITLE" => "Foobar",
"TITLE_isMissing" => false,
"YEAR" => "2014",
"YEAR_isMissing" => false,
"BUDGET" => "500000",
"BUDGET_isMissing" => false,
"GROSS" => "20000000",
"GROSS_isMissing" => false,
"PLOT_SUMMARY" => "give you up",
"PLOT_SUMMARY_isMissing" => false
},
"@version" => "1",
"@timestamp" => "2016-03-16T23:10:11.043Z"
}
If you want to get this into Elasticsearch you can send it there from Logstash, just by adding
elasticsearch { hosts => "localhost"}
to the output stanza of the logstash configuration file. I hit the error
SSLConnectionSocketFactory not found [...]
when I ran Logstash with Elasticsearch output option, to which a quick Google produced the answer; run unset CLASSPATH first.
With the data in Elasticsearch it’s a matter of moments to get set up in Kibana and to start poking around it:
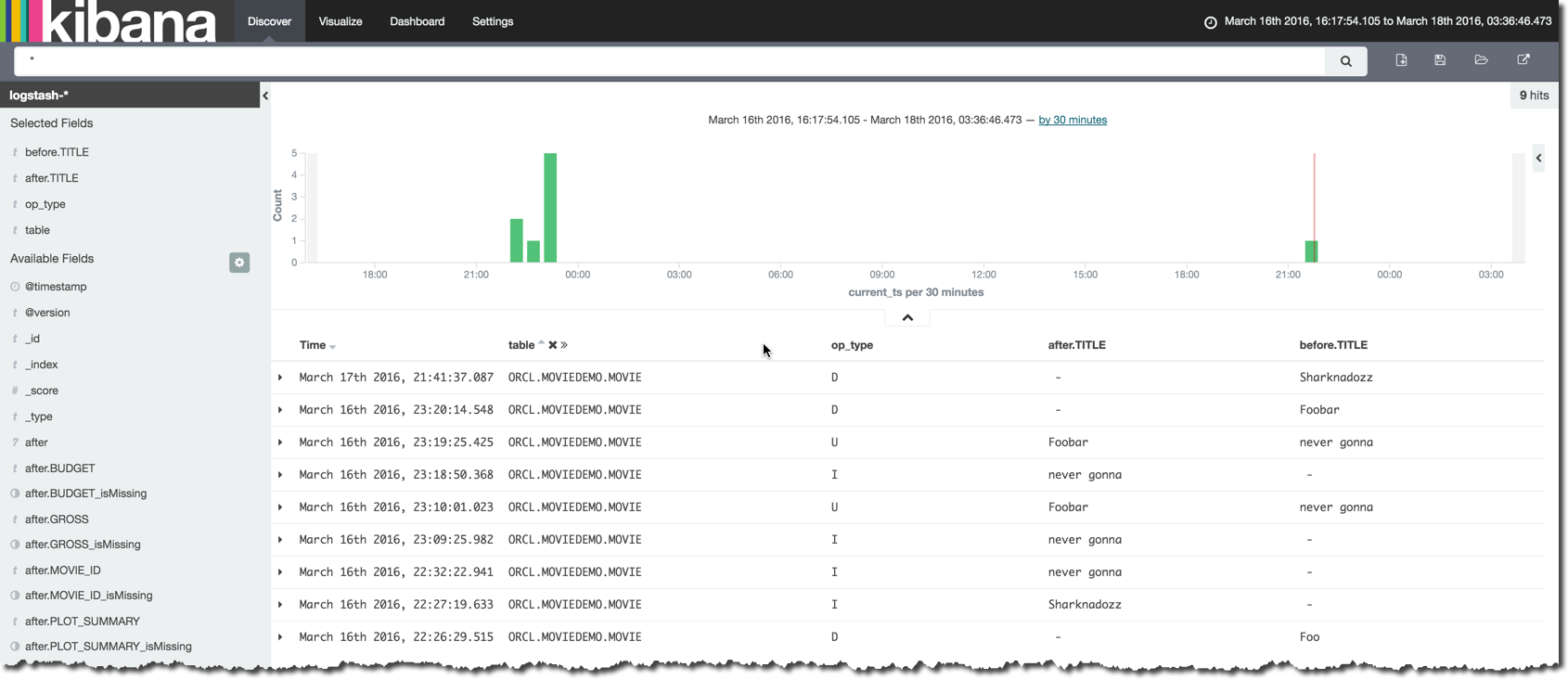
So what’s the point of all this? Well, I mentioned it partly above - jigsaws. It’s fun seeing what fits together with what 8-) But more usefully, Kafka has a vital role to play in flexible data pipelines, and Logstash is just an easy example of one of the many consumers that can take advantage of data persisted in the buffer that Kafka provides. Logstash itself gives a bunch of integration permutations, if the desired target itself doesn’t have a direct Kafka consumer (which something like Elasticsearch may have, with the advent of Kafka Connect).
Pulling the GoldenGate data into Elasticsearch as seen above is cool (c.f. jigsaws, or maybe Lego is a better analogy), and for poking around the Kafka messages and deserialising the Avro messages it’s perfect, but given the CDC nature of it having update and delete transactions too it could be that Elasticsearch-Hadoop is a better route if you want a consistent point-in-time view of your data. Done that way you’d have Hive pushing a copy of the data to Elasticsearch thus:
OGG -- [Kafka] --> HDFS/Hive --> Elasticsearch
