
A short series of notes for myself as I learn more about the AI ecosystem as of September 2025. The driver for all this is understanding more about Apache Flink’s Flink Agents project, and Confluent’s Streaming Agents.
Having poked around MCP and Models, next up is RAG.
RAG has been one of the buzzwords of the last couple of years, with any vendor worth its salt finding a way to crowbar it into their product. I’d been sufficiently put off it by the hype to steer away from actually understanding what it is. In this blog post, let’s fix that—because if I’ve understood it correctly, it’s a pattern that’s not scary at all.
RAG basics 🔗
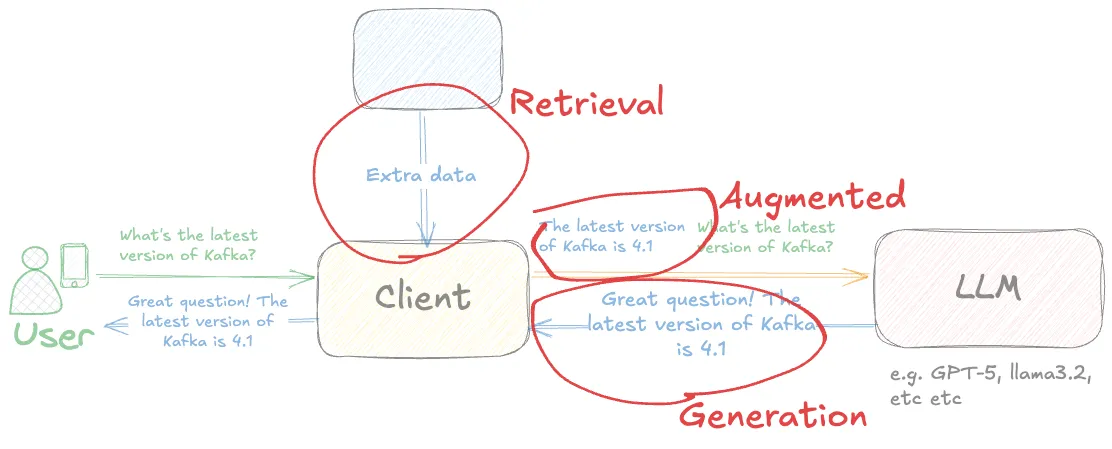
First up: RAG stands for Retrieval-Augmented Generation.
Put another way, it’s about Generation (using LLMs, like we saw before and like you use every day), in which the prompt given to the LLM is Augmented by the Retrieval of additional context.
It is literally the difference between this prompt & response from an LLM:
Respond to this prompt: what’s the latest version of kafka?
Apache Kafka 3.7 (released on May 12, 2023)
and this one:
Using this data: The latest version of Apache Kafka is 4.1. Respond to this prompt: what’s the latest version of kafka?
The latest version of Apache Kafka is 4.1.
The second example’s generation has been augmented by the retrieval of additional information that’s then added to the prompt prior to submission to the LLM.
This may seem stupid—why would I tell the LLM the latest version, and then ask it the latest version? But it’s not me asking! In a typical interaction you’ll have the end-user entering a prompt, and the prompt given to the LLM will be the user’s question, plus context (information) added by some kind of lookup.
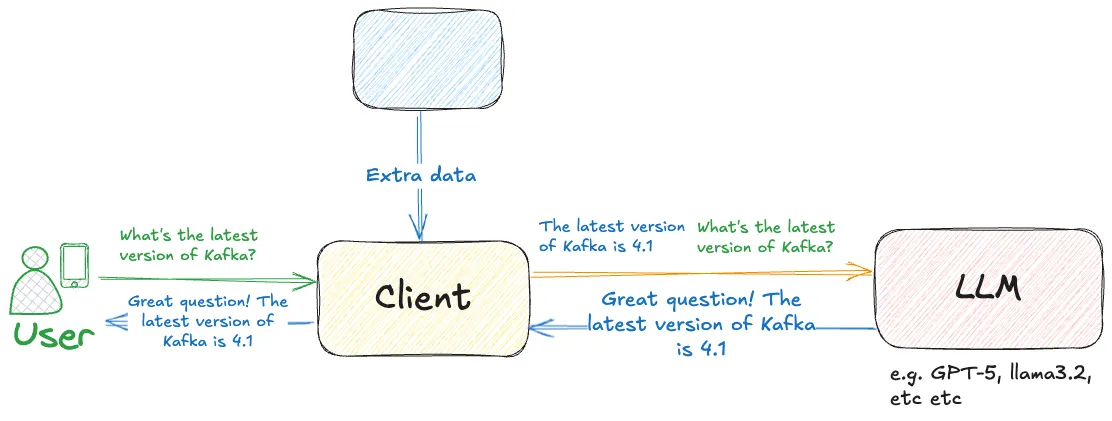
The LLM uses the additional context in order to provide an answer that is much more likely to be accurate, avoiding the issue of hallucinations (when LLMs make shit up) or simply out of date information (on which the LLM was trained; it’s not their fault really).
|
If you like videos, I really liked this video from IBM’s Marina Danilevsky that explains the concept. She uses the analogy of her kid asking her which planet has the most moons, and the fact that her "training dataset" was from several decades ago, and discoveries have been made since then that could render her answer, given in good faith, incorrect. The RAG bit of the analogy is that she would go and check the latest datasource from somewhere like NASA before giving the answer to her child. |
So far, so simple, really. RAG==a fancy way for giving LLMs more context with which to hopefully give you a better answer.
The Kafka version number example is somewhat trite and could be picked apart in multiple ways. Why do I need an LLM to tell me that? Why can’t I just go to the datasource that gave the additional context to the prompt myself?
The point with RAG is that you’re still wanting an LLM to do its thing—but to do so either with much greater accuracy (e.g. Kafka version), or in a way that it simply couldn’t do without the additional context.
RAGs really come into their own for enriching the behaviour of LLMs with data, often that’s held within our business. As a customer, we all expect companies to know "everything" about us, right? After all, we completely the forms, we checked the boxes—why are you asking me to type in a bunch of data that you already know?
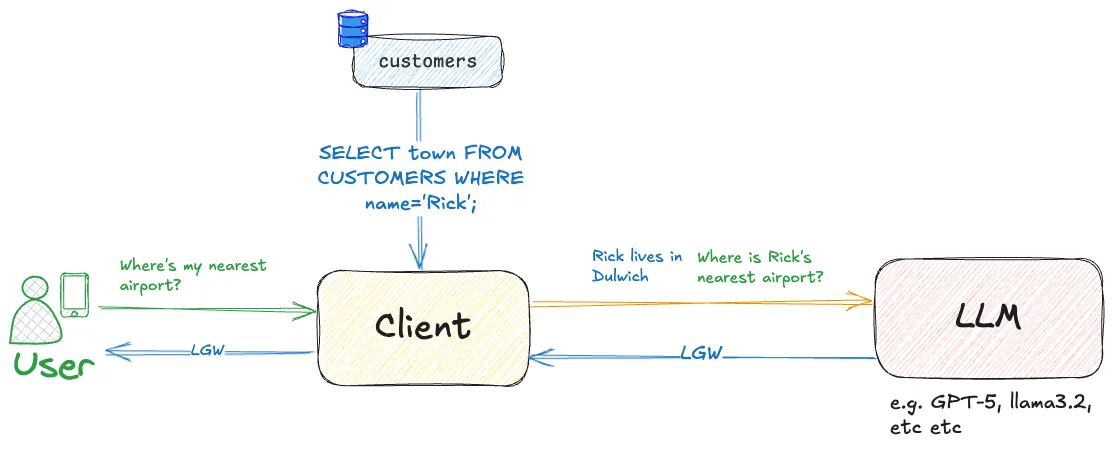
Here’s a simple example of this concept. Imagine we want to know where our nearest airport is?
Yes yes, we could just open Google Maps, but hear me out.
If we ask an LLM this, it’s not got a clue—it has no context:
Where is Rick’s nearest airport? Single answer only.
I’m not aware of any information about Rick, so I’ll need more context or details about who or what "Rick" refers to.
Whereas if we already hold information about our customer 'Rick', we can look that information up and pass it to the LLM:
Using this data: Rick lives in Dulwich. Respond to this prompt: Where is Rick’s nearest airport? Single answer only.
London Gatwick Airport (LGW)
Embeddings and Vectors 🔗
So how do we get this additional context? Or rather, how do we do the Retrieval of data with which we can Augment our Generation?
Well, you could literally run a SQL query, as illustrated above. You could have your client make API calls to get data, you could even use an MCP server—the end result is the same: the LLM is getting additional context to help it do what you want it to do.
One common pattern for the implementation of RAG is the use of vector databases. In fact, so common I would say it’s become synonymous. The reason that it’s so widely used is that whilst a SQL lookup is excellent for working with structured data (e.g. "where does my customer live"), that’s often not the kind of additional context that we want to provide to the LLM.
What if we’re working with text? Whilst LLMs are trained on a metric crap-ton of publicly available text, there’s material out there that they don’t know about. That could be content that was created after the LLM was trained (for example, the release notes for the latest version of Apache Kafka). Often, in the context of RAG, it’s material internal to a company such as documentation, wikis, emails, Slack conversations…any manner of content.
To use this text data in RAG, a representation ("embedding") of the semantic meaning of the text is created, and stored as a vector. This is the RAG Ingestion part. Once the data is stored, it can be used in RAG Retrieval. What this does is take the user’s query and convert that to an embedding too. It then compares the query’s vector with those held in the vector store (populated by the ingest process) and finds the piece of textual data ("embedding") that’s most closely related to it. This piece of additional information is then included in the LLM request, in exactly the same manner we saw above—adding context to the existing prompt.
The Ollama blog has a nice example which I’m going to use here, demonstrating the Kafka version example I showed above.
RAG Ingestion: Populating a vector database with embeddings 🔗
First, set up the environment. We’re using ChromaDB as an in-memory vector store. Ollama is a tool for running models locally.
import ollama
import chromadb
client = chromadb.Client()
collection = client.create_collection(name="docs")Now we define our 'documents'. This is a very simplified example. In practice we could be ingesting entire wikis or codebases of information. The vital bit is how we carve it up, which is known as chunking. A chunk is what will get passed to the LLM for enriching the context, so it needs to be big enough to be useful, but not so big that it is unhelpful (e.g. blows the token limit on the LLM, provides context that is not specific enough, etc).
Here I’ve manually pasted excerpts of the Apache Kafka 4.1.0 release blog post (I’ve cropped the text in the code sample here, just for clarity of layout):
documents = [
"4 September 2025 - We are proud to announce the release of Apache Kafka® 4.1.0. This release contai[…]",
"KIP-877: Mechanism for plugins and connectors to register metrics Many client-side plugins can now […]",
"KIP-932: Queues for Kafka (Early Access) This KIP introduces the concept of a share group as a way […]",
"KIP-996: Pre-Vote KIP-996 introduces a 'Pre-Vote' mechanism to reduce unnecessary KRaft leader elec[…]"
]For each of these documents we call an embedding model (which is not an LLM!) which captures the semantic meaning of the text and encodes it in a series of vectors which are added to the ChromaDB collection:
for i, d in enumerate(documents):
response = ollama.embed(model="mxbai-embed-large", input=d)
embeddings = response["embeddings"]
# Store the embeddings in ChromaDB
collection.add(
ids=[str(i)],
embeddings=embeddings,
documents=[d]
)The model used here is mxbai-embed-large.
For interest, here’s what the data we’re storing in the vector database looks like:
ID: 0
Document: 4 September 2025 - We are proud to announce the release of Apache Kafka® 4.1.0. This relea[…]
Embedding: [ 0.05642379 -0.02119605 -0.04147635 0.05452667 -0.01146116]...
ID: 1
Document: KIP-877: Mechanism for plugins and connectors to register metrics Many client-side plugins[…]
Embedding: [-0.01764962 -0.00686921 -0.03395142 0.00759143 -0.02553692]...
ID: 2
Document: KIP-932: Queues for Kafka (Early Access) This KIP introduces the concept of a share group […]
Embedding: [0.05048409 0.00816069 0.00764809 0.03790297 0.00651639]...
ID: 3
Document: KIP-996: Pre-Vote KIP-996 introduces a 'Pre-Vote' mechanism to reduce unnecessary KRaft le[…]
Embedding: [ 0.04927347 -0.02349585 0.01001445 0.01915772 -0.010186 ]...So the vector database holds the actual document (chunk) data, along with the embedding representation.
That’s all, so far. A static set of text data, stored in a way that represents the semantic meaning of the data.
You do this process once, or add to the vector database as new documents are needed (for example, when Apache Kafka 4.2.0 is released).
RAG Retrieval: Using embeddings to provide context to an LLM 🔗
Now our merry user arrives with their LLM client, and wants to know the latest version of Kafka.
Left to its own devices, the LLM only knows what it was trained with, which will have a cutoff date. Sometimes the LLM will tell you that, sometimes it won’t.
Instead of ollama.embed, let’s use ollama.generate with the llama3.2 LLM to generate the answer to the question with no additional context:
user_input = "what's the latest version of kafka?"
prompt=f"Respond to this prompt: {user_input}"
output = ollama.generate(
model="llama3.2",
prompt=prompt
)
print(f"{prompt}\n-----\n{output['response']}\n\n=-=-=-=-")Respond to this prompt: what's the latest version of kafka?
____
As of my knowledge cutoff in December 2023, the latest version of Apache Kafka is 3.4.OK—so as expected, not up-to-date, at all. What we’d like to do is help out the LLM by giving it some more context.
We can’t throw our entire library of knowledge at it—that wouldn’t work (too many tokens, not specific enough). Instead, we’re going to work out within our library, which document is most relevant to the query.
The first step is to generate an embedding for our query, using the same model with which we created the embeddings for the documents in the vector database (the "library" to which I’m figuratively referring).
user_input = "what's the latest version of kafka?"
response = ollama.embed(
model="mxbai-embed-large",
input=user_input
)The vector looks like this:
[[0.017346583, -0.021703502, -0.0436593, 0.045320738, -0.0005510414, -0.038553298, 0.016 […]which to you or I might not mean much, but when passed to the vector database as a .query:
results = collection.query(
query_embeddings=response["embeddings"],
n_results=1
)
data = results['documents'][0][0]returns the document that is the most closely related, semantically:
4 September 2025 - We are proud to announce the release of Apache Kafka® 4.1.0. This release contains many new features and improvements. […]We’ve now retrieved the additional context with which we can now do the generation. The prompt is the same as before, except we include the document that we retrieved from the vector database in it too:
prompt=f"Using this data: {data}. Respond to this prompt: {user_input}"
output = ollama.generate(
model="llama3.2",
prompt=prompt
)Using this data: 4 September 2025 - We are proud to announce the release of Apache Kafka® 4.1.0. This release contains many new features and improvements. This blog post will highlight some of the more prominent ones. For a full list of changes, be sure to check the release notes. Queues for Kafka (KIP-932) is now in preview. It's still not ready for production but you can start evaluating and testing it. See the preview release notes for more details. This release also introduces a new Streams Rebalance Protocol (KIP-1071) in early access. It is based on the new consumer group protocol (KIP-848). See the Upgrading to 4.1 section in the documentation for the list of notable changes and detailed upgrade steps..
Respond to this prompt: what's the latest version of kafka?
____
The latest version of Kafka mentioned in the data is Apache Kafka 4.1.0, which was released on September 4, 2025.There we go–our LLM used the context from the release notes to not only tell us the latest version, but also its release date.
And then the snake ate its own tail 🔗
In writing this article I made a rookie mistake. No surprise there; but one worth illustrating here.
I use LLMs a lot to help my writing—never to write but to help generate code, for example. The embeddings example on the Ollama blog had these documents:
documents = [
"Llamas are members of the camelid family meaning they're pretty closely related to vicuñas and camels",
"Llamas were first domesticated and used as pack animals 4,000 to 5,000 years ago in the Peruvian highlands",
"Llamas can grow as much as 6 feet tall though the average llama between 5 feet 6 inches and 5 feet 9 inches tall",
"Llamas weigh between 280 and 450 pounds and can carry 25 to 30 percent of their body weight",
"Llamas are vegetarians and have very efficient digestive systems",
"Llamas live to be about 20 years old, though some only live for 15 years and others live to be 30 years old",
]Cute, but nothing to do with my domain. So I did as I often do—chuck it over to an LLM.
Feeling smug, I copied this into my Python code and added a couple more documents (chunks) to illustrate the point about release version freshness:
documents = [
"The latest version of Apache Kafka is 4.1",
"KIP-932 adds support for traditional message queue semantics to Kafka",
"Apache Kafka is a distributed event streaming platform originally developed by LinkedIn and later open-sourced to the Apache Software Foundation",
"Kafka was first released in 2011 and is written primarily in Scala and Java, designed to handle high-throughput, low-latency data streaming",
"Kafka clusters can scale horizontally across multiple servers and can handle millions of messages per second with sub-millisecond latency",
"Kafka uses a publish-subscribe messaging model where producers write data to topics and consumers read from those topics in real-time",
"Kafka provides durability through configurable data replication and can retain messages for days, weeks, or even indefinitely depending on configuration",
"Kafka is widely used by companies like Netflix, Uber, Airbnb, and thousands of other organizations for real-time analytics, log aggregation, and event-driven architectures"
]But when it came to comparing LLM responses using RAG and this data, it didn’t really make much difference in some cases:
Respond to this prompt: what is Apache Kafka? Give me one sentence. (1)
____
Apache Kafka is a distributed streaming platform that enables real-time data processing and event-driven architecture, providing fault-tolerant and scalable messaging capabilities for large-scale data ingestion, storage, and analysis.
=-=-=-=-
Using this data: Apache Kafka is a distributed event streaming platform originally developed by LinkedIn and later open-sourced to the Apache Software Foundation. Respond to this prompt: what is Apache Kafka? Give me one sentence. (2)
____
Apache Kafka is a distributed event streaming platform that enables scalable, fault-tolerant, and secure data processing and consumption for real-time applications.
=-=-=-=-| 1 | No RAG |
| 2 | With RAG |
Why’s the output basically the same?
Because the LLM already knows what Apache Kafka is!
If it didn’t, how would it have generated the documents array above?
(technically I used Claude 4 Sonnet to generate the array and Llama 3.2 in my Python script—but basically the same principle).
One lesson, but to express in two different ways from this:
-
RAG content only makes sense if it’s not already in the LLM
-
Don’t use LLMs to generate RAG content
There are probably a bunch of nuances to this. For example, could you use a more powerful LLM to distill down content for use in RAG by a smaller LLM (cheaper/faster to run)? Tell me in the comments below—I’m here to learn :)
Further reading 🔗
-
Tons of great content in this talk from Paul Iusztin at QCon London 2025, including lots about RAG (at around 24 minutes in).