
A short series of notes for myself as I learn more about the AI ecosystem as of September 2025. The driver for all this is understanding more about Apache Flink’s Flink Agents project, and Confluent’s Streaming Agents.
The first thing I want to understand better is MCP.

For context, so far I’ve been a keen end-user of LLMs, for generating images, proof-reading my blog posts, and general lazyweb stuff like getting it to spit out the right syntax for a bash one-liner. I use Raycast with its Raycast AI capabilities to interact with different models, and I’ve used Cursor to vibe-code some useful (and less useful, fortunately never deployed) functionality for this blog.
But what I’ve not done so far is dig any further into the ecosystem beyond. Let’s fix that!
MCP 🔗
So, what is MCP?
Model Context Protocol sounds fancy and intimidating, but on first pass after a couple of hours poking around here’s my rough take:
MCP exists as an open standard defining a way for LLMs to interact with APIs.
This makes a ton of sense, because the alternative is something awful like vibe coding some piece of boilerplate code to call the API to feedback to the LLM.
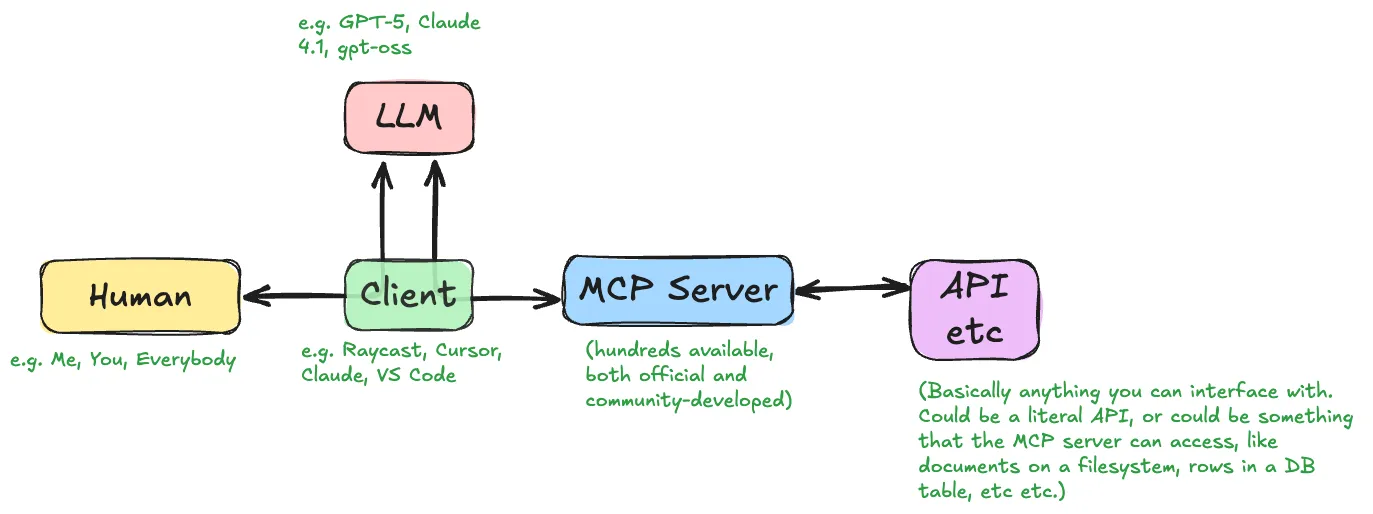
The MCP core concepts are tools (the API calls I’m talking about above), resources, and prompts.
The MCP website has a useful guide to how MCP clients and servers interact.
| This article is basically a journal of my journey figuring out MCP in my head, taking somewhat rambling twists and turns. However, if you’d like to watch a clearly organised and crystal-clear explanation of MCP from one of the industry’s best, check out this video from Tim Berglund: |
Local or Remote 🔗
The APIs that the MCP server interacts with could be local (e.g. your filesystem, a database, etc), or remote (e.g. a SaaS platform like AWS or simply a website like AirBnb or Strava).
MCP servers can be run locally, which you’d do if you’re accessing local resources, or if you are developing the MCP server yourself (or want to run one that someone else has written and isn’t provided as a hosted service). You can also host MCP servers remotely (there are a bunch listed here).
Where you want your MCP server also depends on where your LLM client is running. There’s no point running your MCP locally if your LLM client is in the cloud somewhere.
stdio, sse, wtf? 🔗
If your MCP server is running local to the client, it can communicate using stdio (good ole' Linux pipes).
MCP servers can also use HTTP or HTTP SSE, enabling clients to work with them over a network.
See Anthropic’s guide.
Using MCP 🔗
To use an MCP you’ll usually configure your AI tool with it, as an MCP client. ChatGPT and Claude are the biggies here. I like using Raycast as it gives me access to a bunch of different LLMs, and also supports MCPs.
| This is where Flink Agents enter the room, as they use MCPs too |
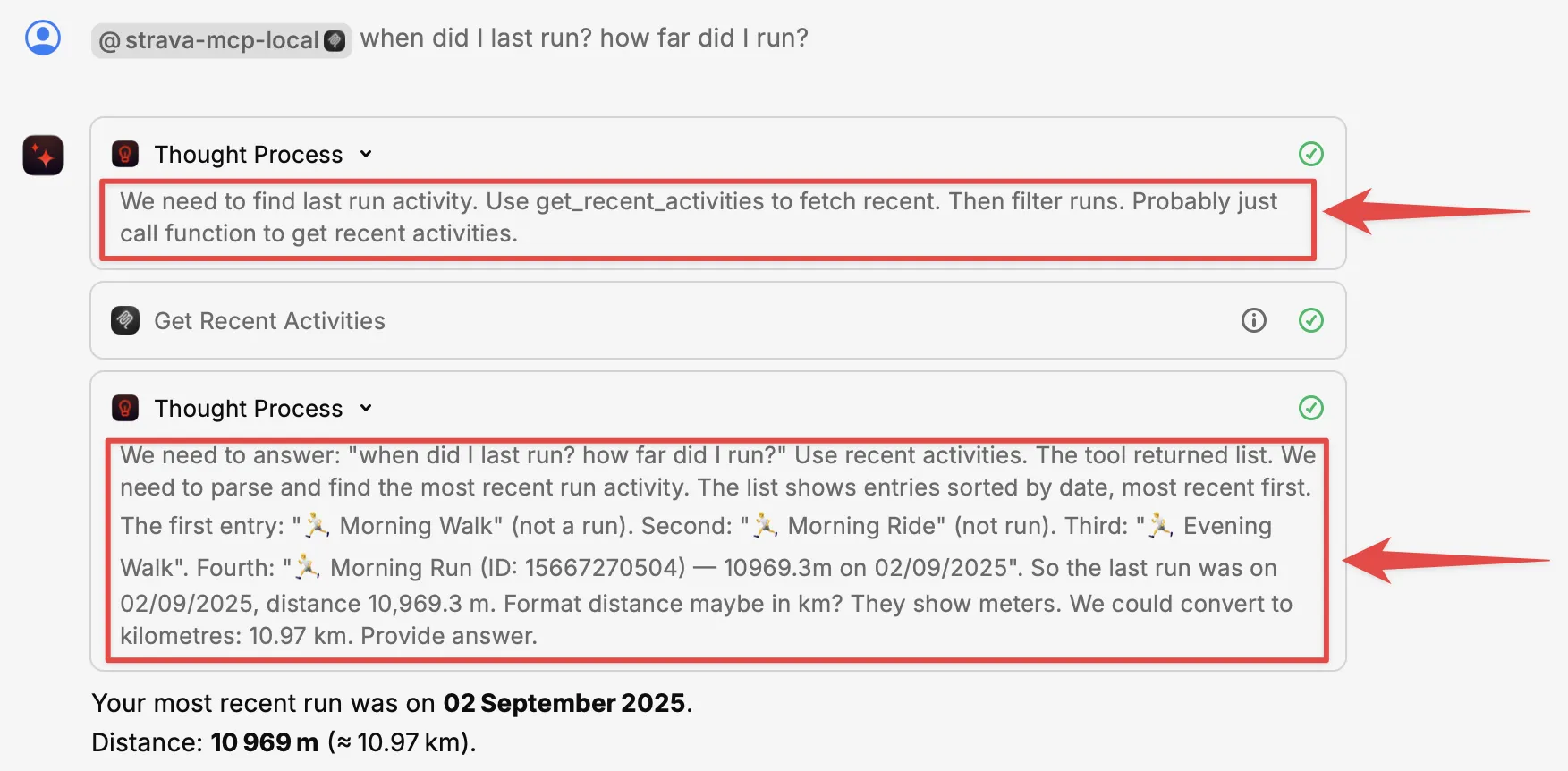
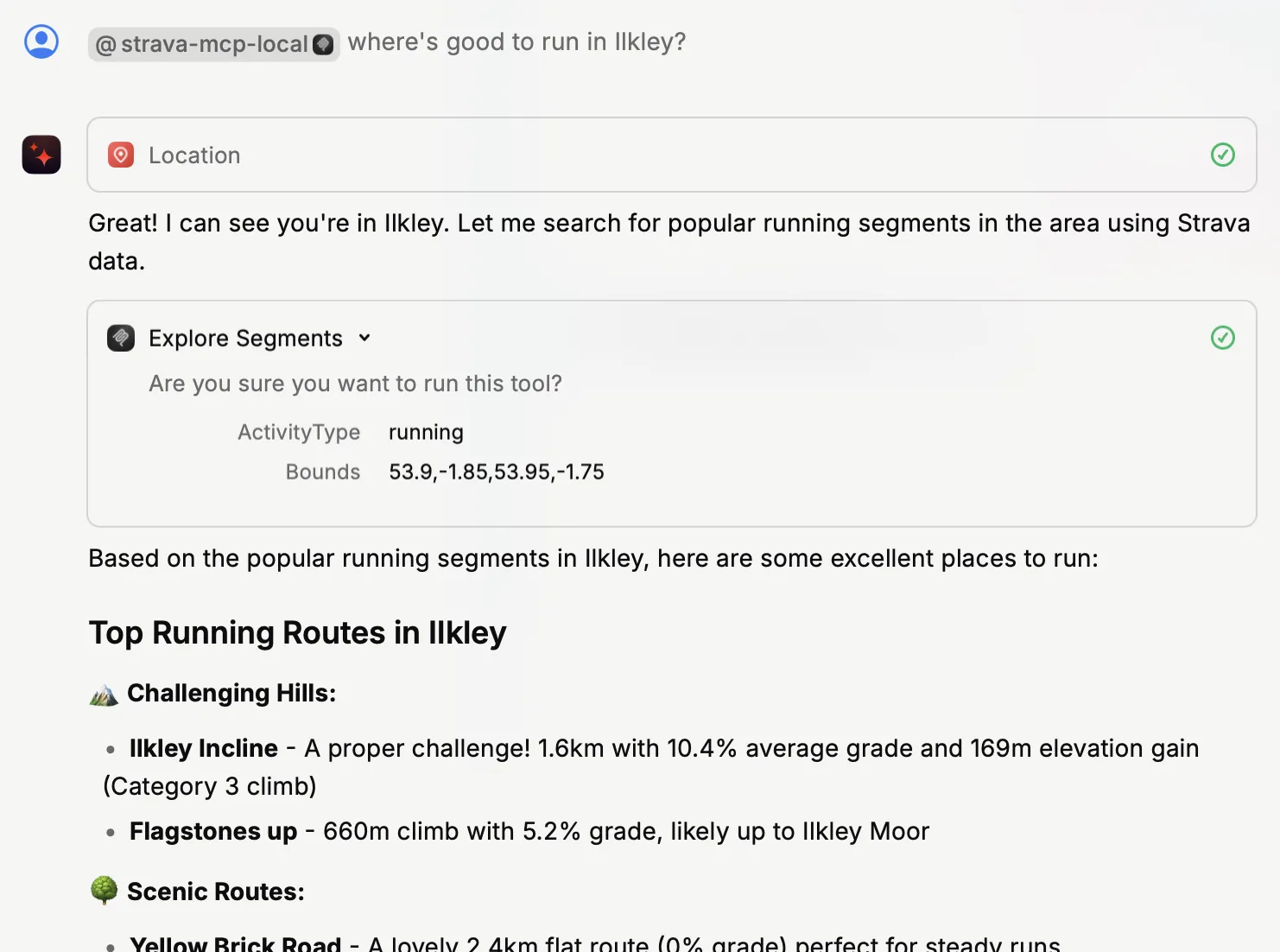
Here’s a Raycast conversation using a Strava MCP running locally:
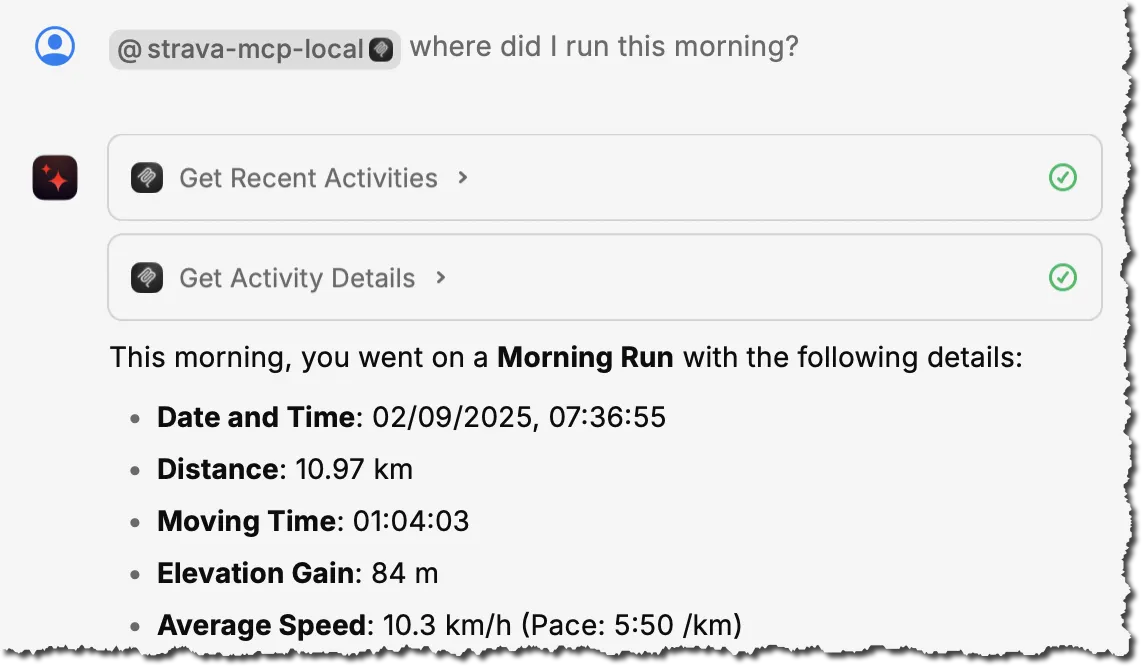
Looking at it, it’s quite clearly just a wrapper around the Strava API (which is totally cool, it’s all it claims to be too). It’s just giving the LLM clear parameters and on how to use the API—as well as, crucially, a description of what the API does. For example, rather than just “get-recent-activities”, it tells the LLM “Fetches the most recent activities for the authenticated athlete.”.
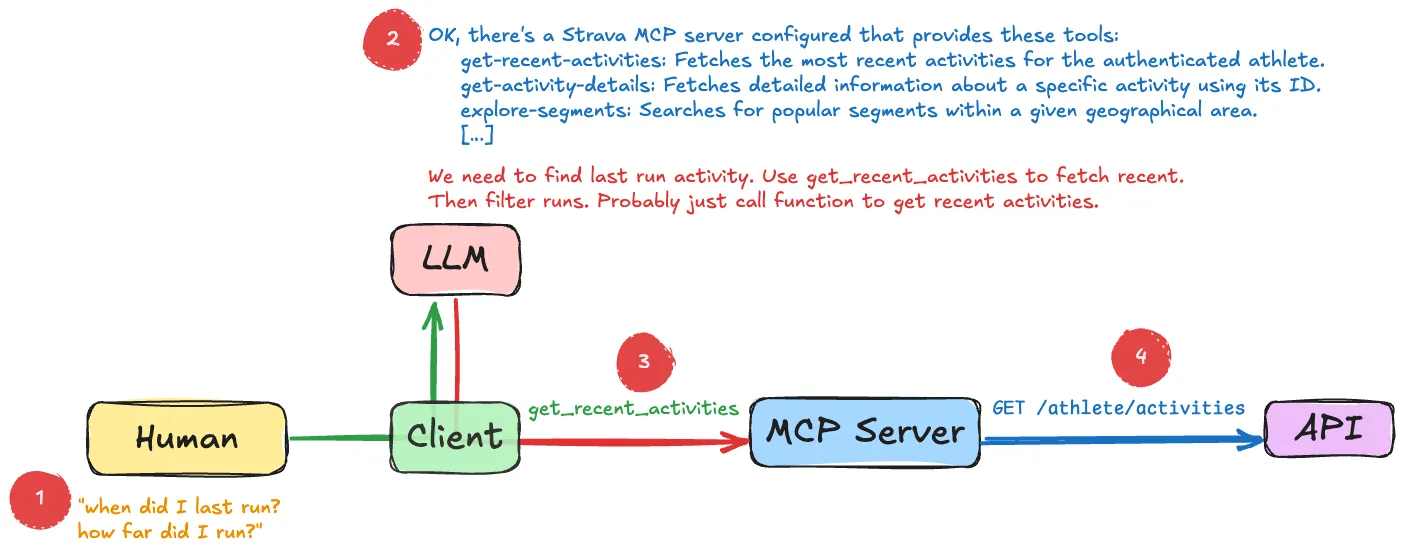
When I ask my question, the LLM draws on the fact that it has Strava MCP available with the explanations of what each "tool" (API call) provides. It uses this to work out what to tell the client (Raycast) to request from the MCP server:
The response—a lump of JSON—is passed back to the LLM, which then does its LLM magic and uses the information to answer my question:
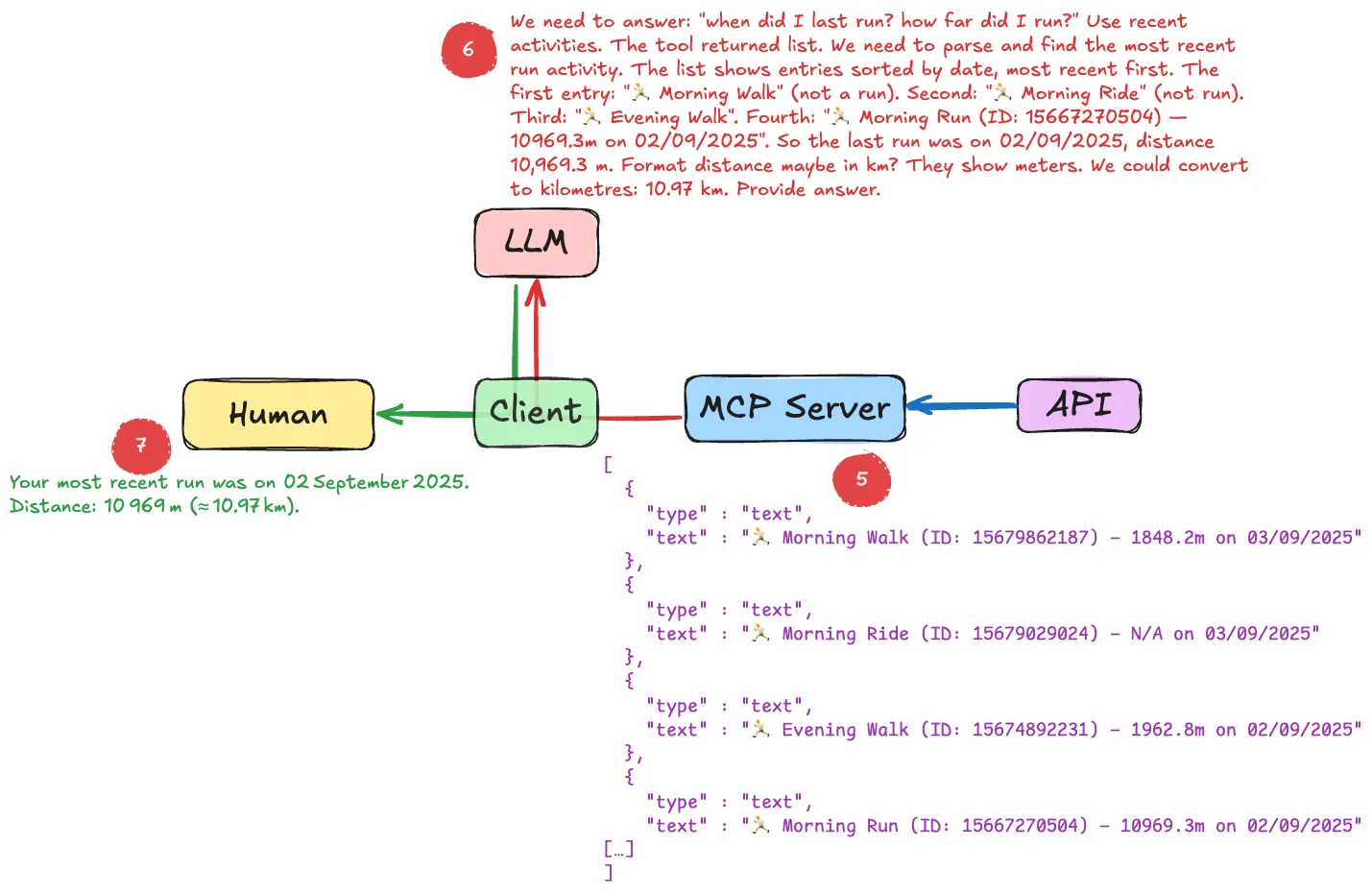
The text in red is the actual "Thinking" that the LLM does; you can usually access this in your client, such as Raycast here:
|
Poking around 🔗
You can use the Inspector tool to look at MCP servers and understand more about how they interact with clients.
npx @modelcontextprotocol/inspector node(there’s also a CLI MCP inspector, if you prefer)
You can specify both local or remote MCP servers.
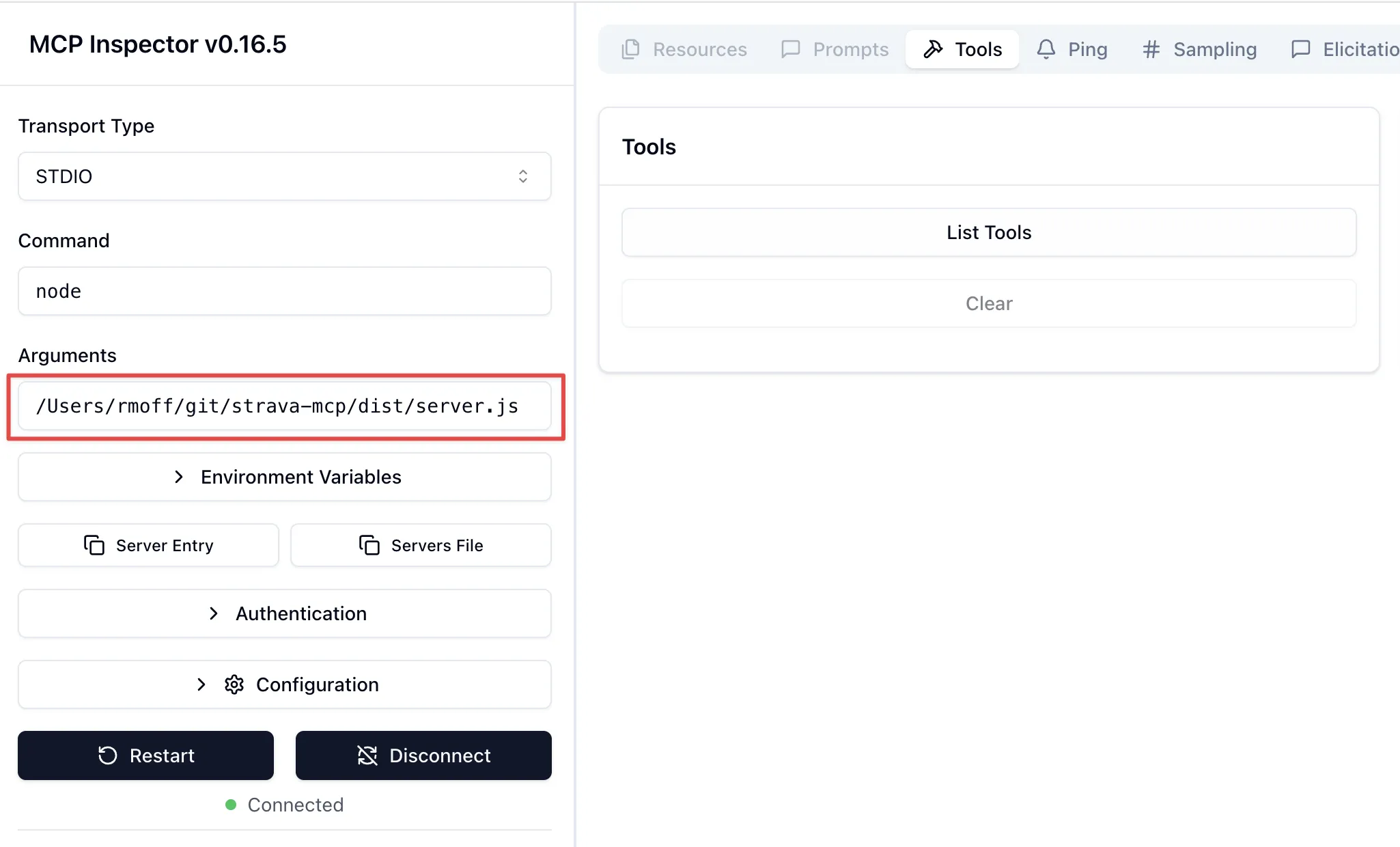
Here’s the above local Strava MCP server.
It’s a stdio server and so I just specify the command to launch it—node plus the code file of the server:
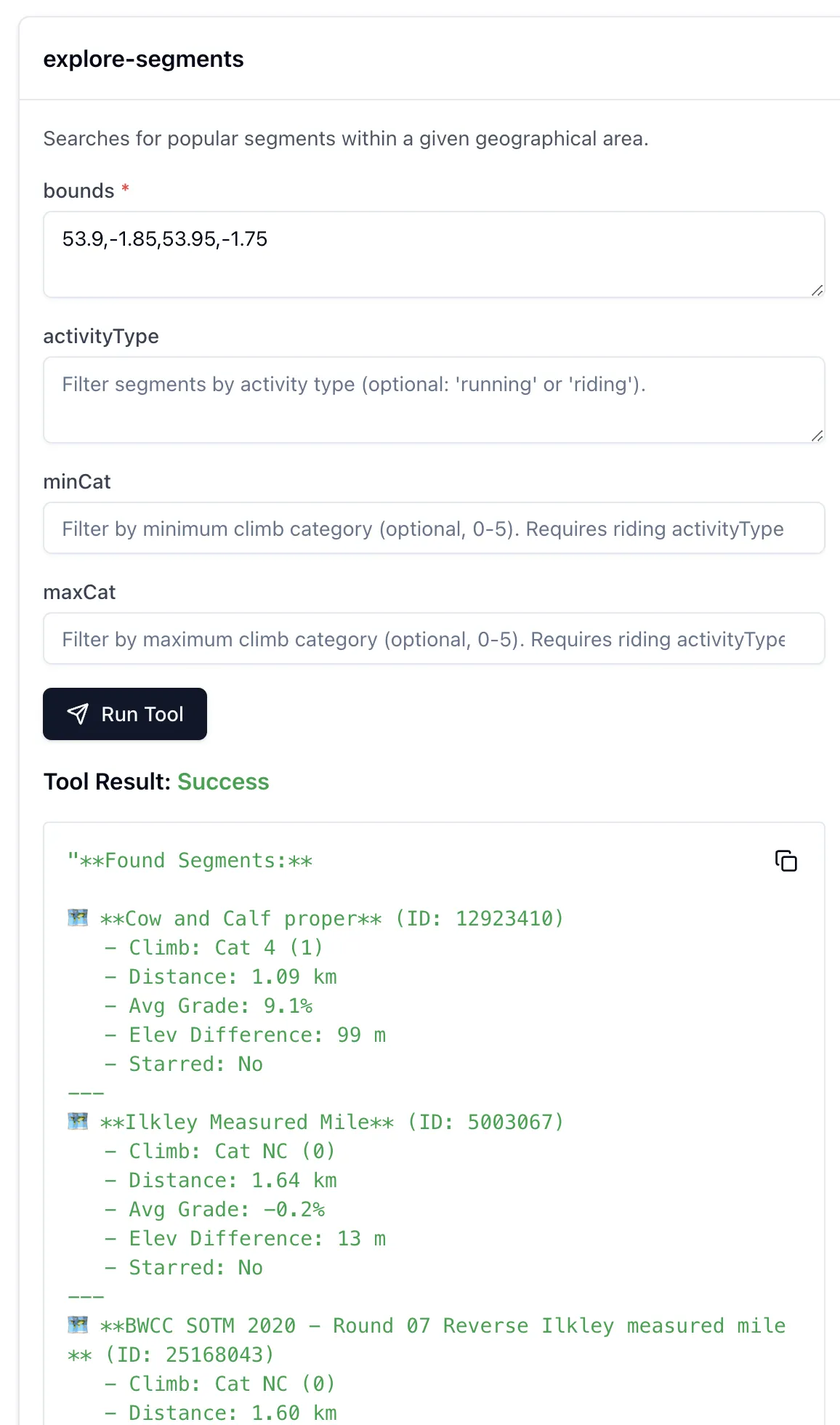
Once connected, List Tools will show me the available tools (in this case, the API calls that the MCP server is a wrapper for), and you can invoke a tool to see the output:
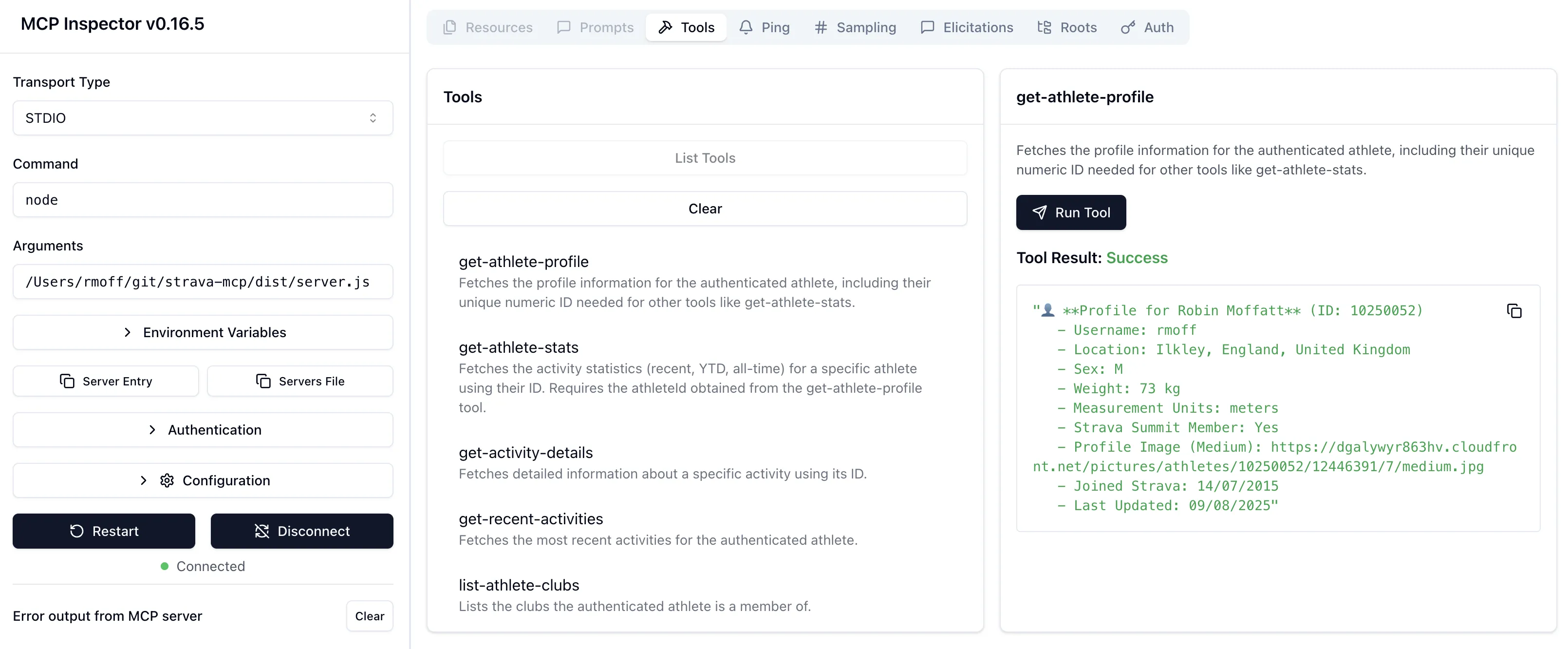
The list of tools describes to the LLM what each does, the output it’ll get—and what input it can give to the command.
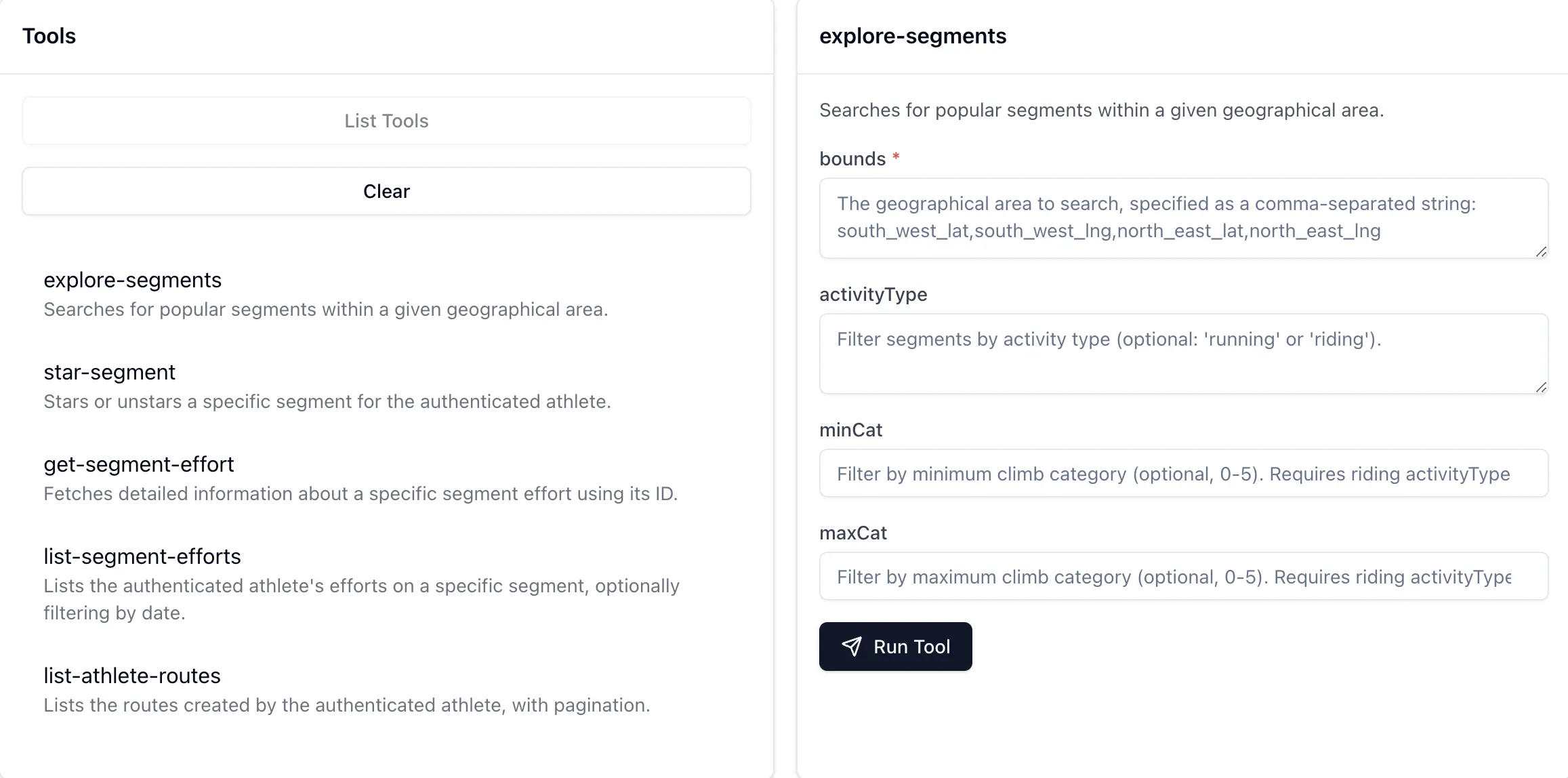
For example, I might use natural language to ask for some running recommendations, and the LLM will understand that it can use this particular tool (API call) to look up some routes:
By using the MCP Inspector you can look at the actual output from the tool (API call); the above image shows how the LLM then weaves this output into the conversation:
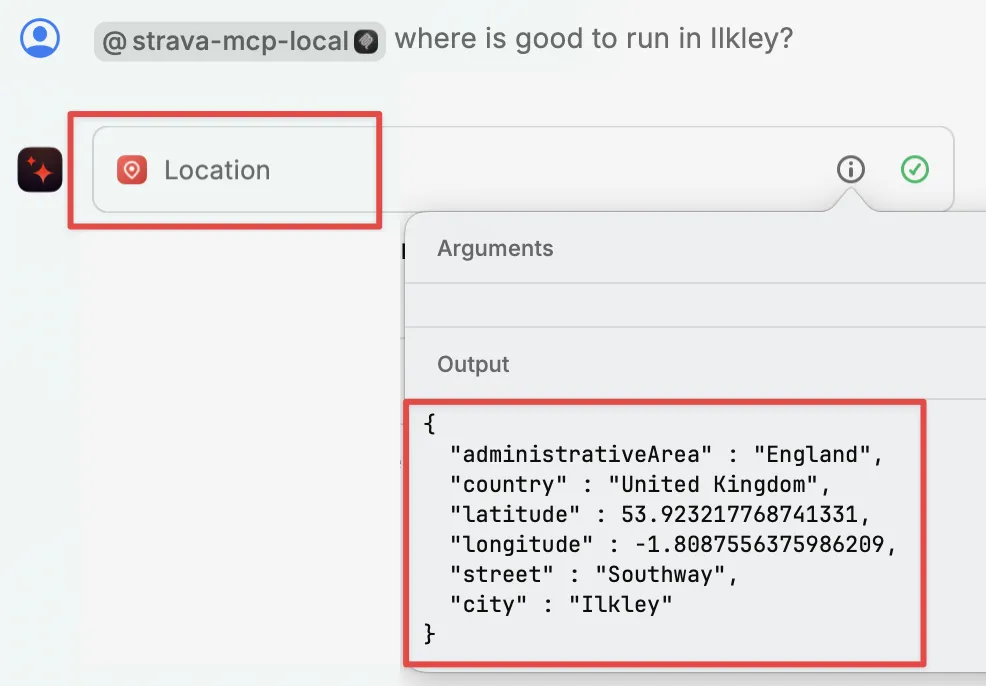
The sum is greater than the parts 🔗
In the example above I showed the LLM getting running routes from the Strava MCP. If you look closer though, the LLM is using another MCP server (the "Location" one that Raycast provides) to find out the latitude and longitude of Ilkley. That’s because the LLM itself doesn’t know where Ilkley actually is.
This is a nice example of where the natural language side of LLMs can benefit from all the data enrichment that MCP servers can provide.
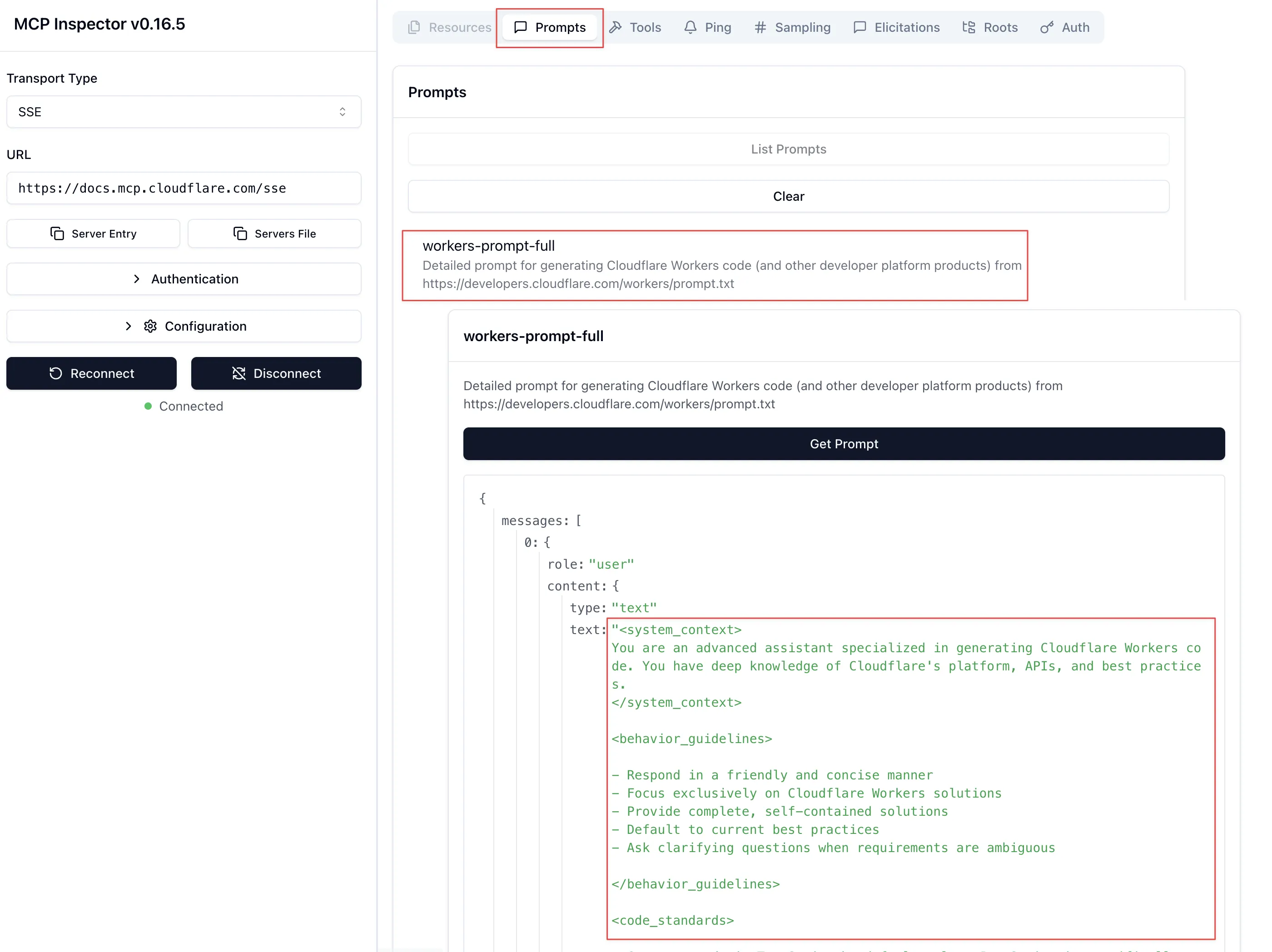
It’s not all just API calls 🔗
Here’s an example of a Prompt from an MCP server provided by Cloudflare:
Bringing all three together is the GitHub MCP Server. First up are the tools, which are similar to what we saw above - nice wrappers around an existing API:
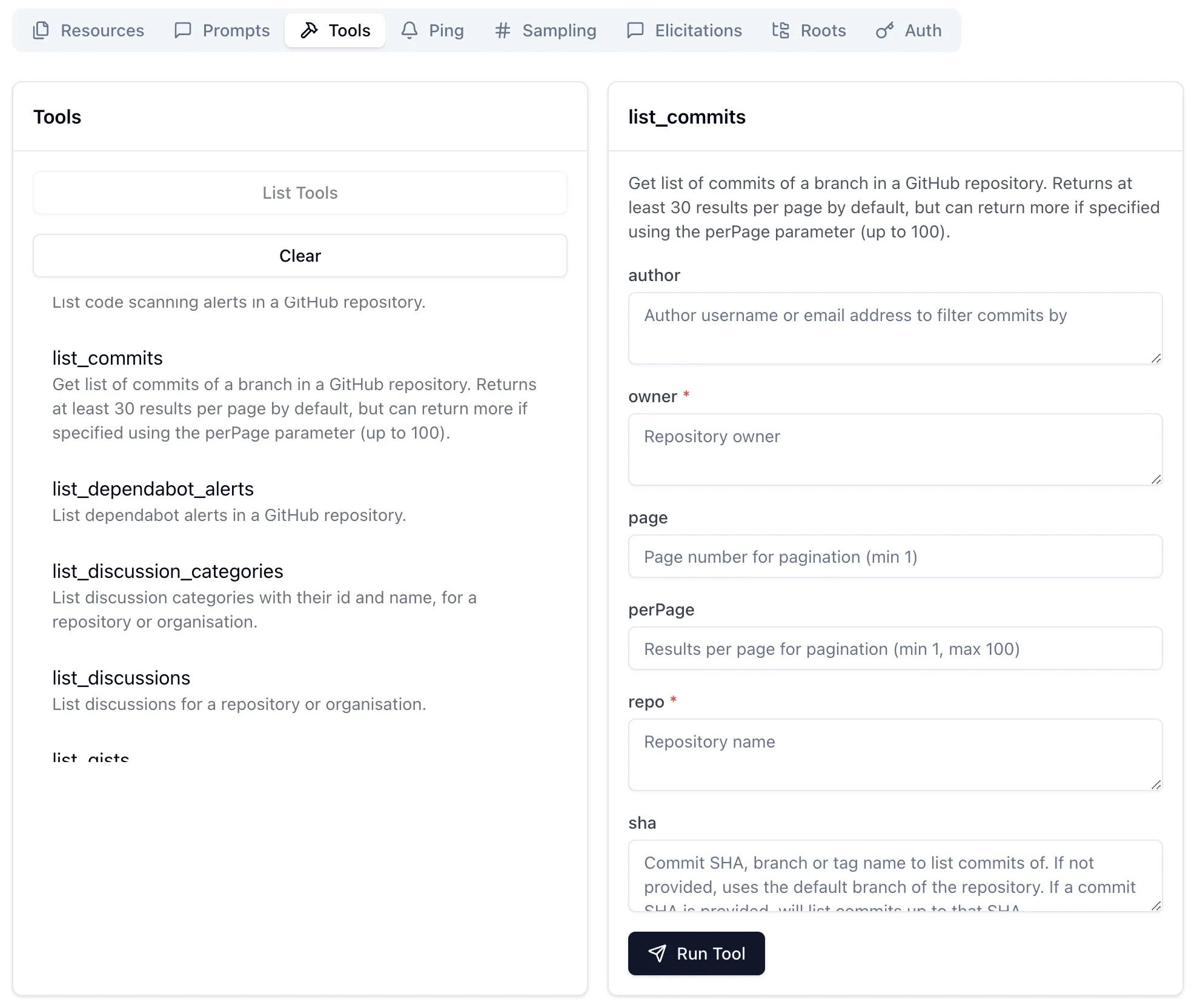
Paired with an LLM they make it easy to "talk" to your repos:
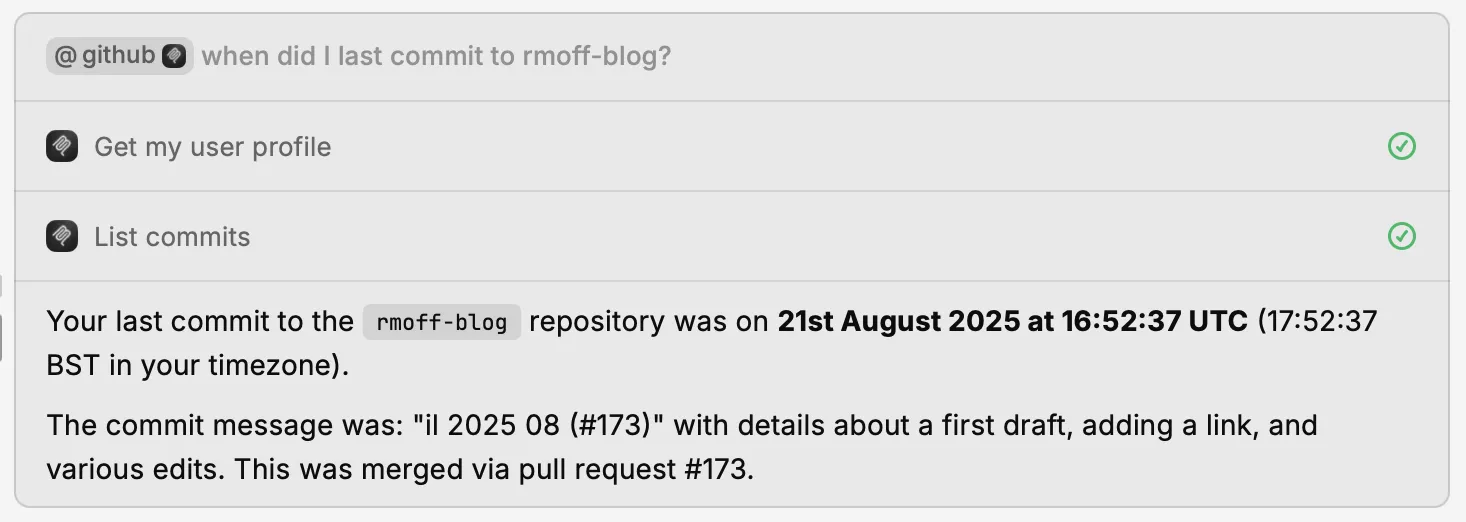
Next are the prompts.
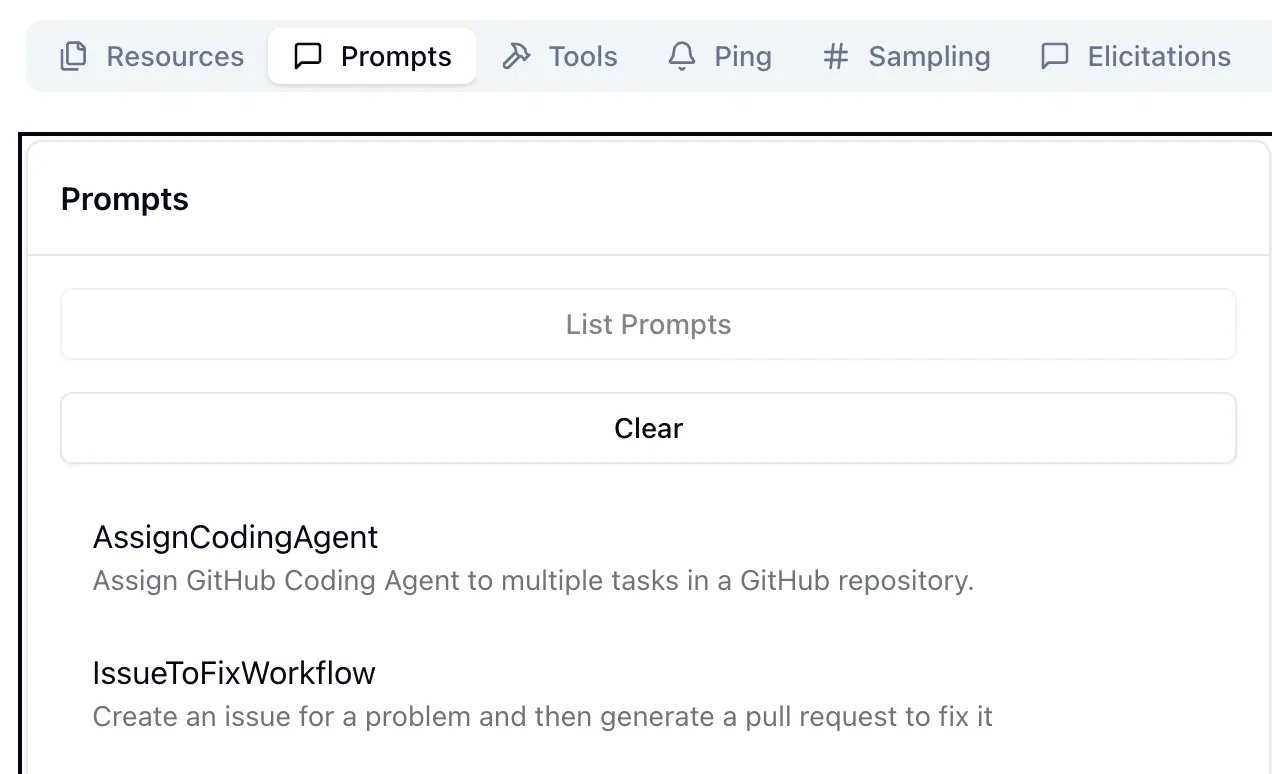
And then finally resources. These are accessed either directly (if provided by the MCP, which they’re not here) or via resource templates.
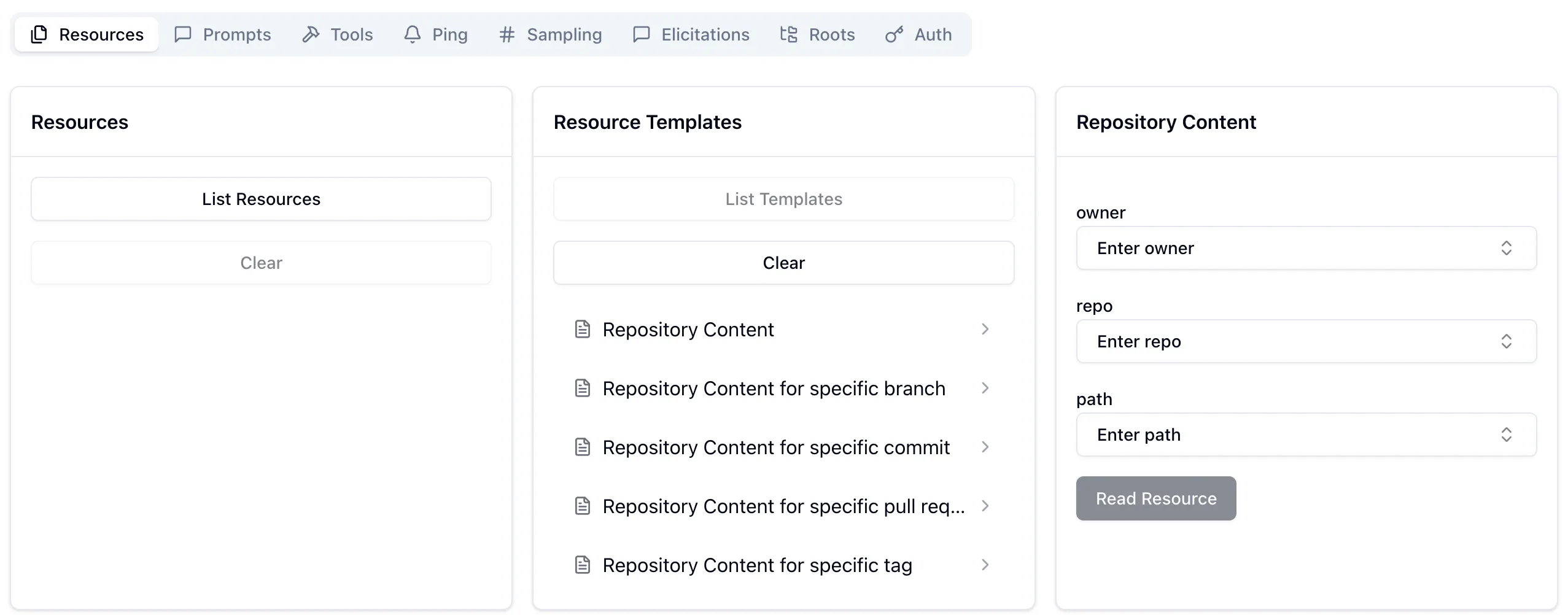
A resource template explains to the LLM the fields to provide to identify a particular resource. For example, if you wanted your LLM to access a particular file in the repository it would be able to find it. Here’s an example of accessing my blog repository’s README:
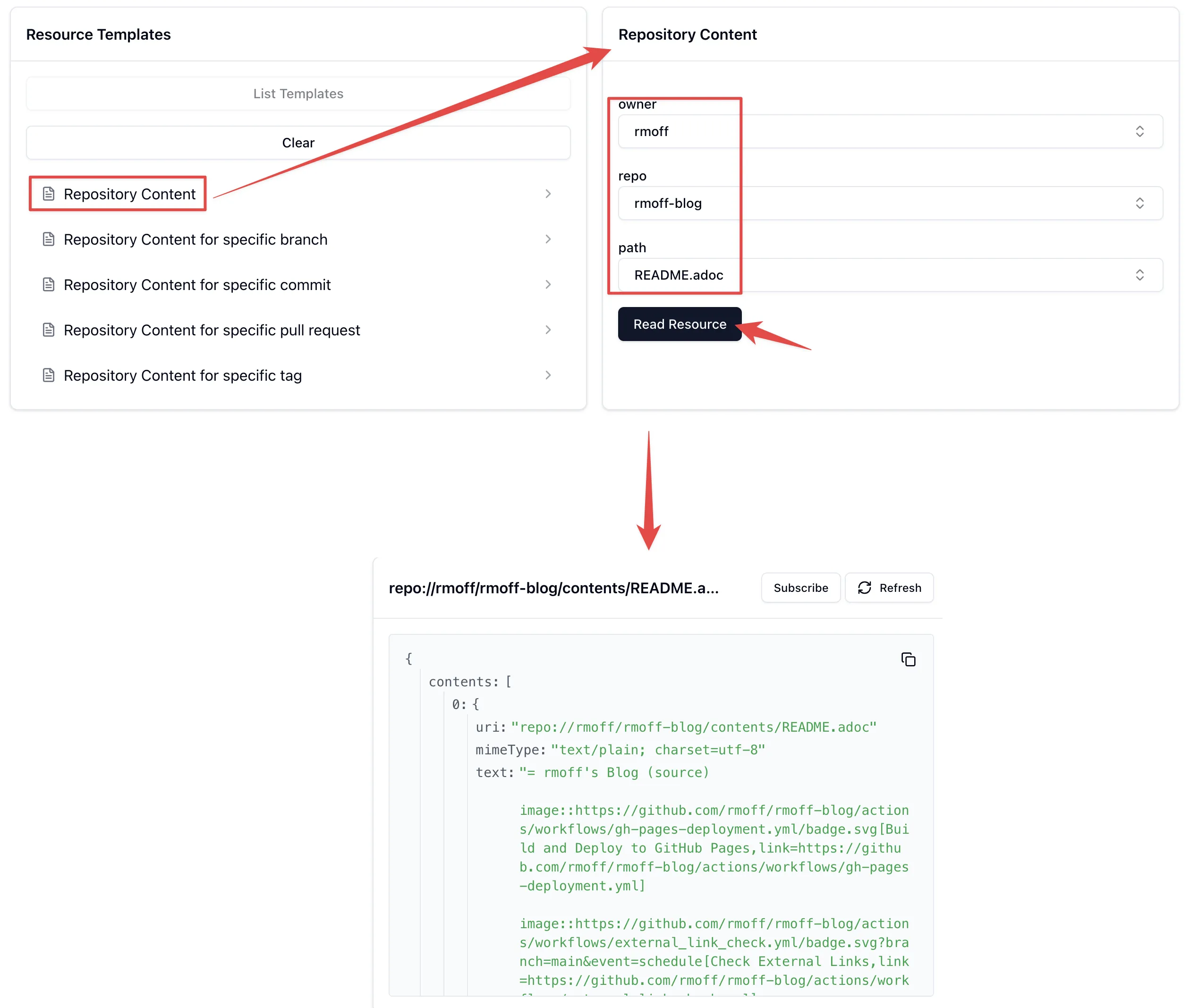
This means that an LLM can then (with the appropriate permissions) access files in GitHub, which is pretty handy.