
In this blog post I’ll show how you can use Flink SQL to write to Iceberg on S3, storing metadata about the Iceberg tables in the AWS Glue Data Catalog. First off, I’ll walk through the dependencies and a simple smoke-test, and then put it into practice using it to write data from a Kafka topic to Iceberg.
Apache Iceberg is a table format that provides a way of storing tabular data on object storage that can be read and written to by lots of different engines. When you’re using Iceberg you’ll need a metadata catalog so that other users of the data can discover what tables exist and where. Here I’m using Glue Data Catalog, but other catalogs that you might use in its place include Hive Metastore, Apache Polaris, Unity Catalog, and so on.
| You can find the Docker Compose for this article here |
Dependencies 🔗
I’m using Flink 1.20, since as of the time of writing (2025-06-24) the Iceberg connector doesn’t yet support Flink 2.0 (it’s due with Iceberg 1.10.0). The dependencies listed below are specifically for this version.
Iceberg 🔗
We’re writing to Iceberg, so need the Flink Iceberg connector, which is part of the Iceberg project.
The JAR is iceberg-flink-runtime-1.20-1.9.1.jar.
AWS S3 and Glue 🔗
JARs 🔗
AWS has an integration for Iceberg which provides support for both S3 and Glue data catalog.
The JAR is iceberg-aws-bundle-1.9.1.jar
S3 bucket 🔗
You’ll need an S3 bucket to write your Iceberg tables.
Authentication 🔗
You need to give Flink a way to authenticate to AWS. There are different ways to do this. I’ve gone for the very simple—and extremely insecure—method of setting environment variables. Remember that Flink is a distributed system and each component must have these environment variables set. Otherwise you’ll find one thing works (e.g. some table DDL) whilst another doesn’t (e.g. writing data to the table), because different components in Flink come into play at different stages.
In Docker Compose I use this syntax to pass through to the container the value of the variables, that I’ve set locally on the host machine:
environment:
- AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID}
- AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
- AWS_REGION=${AWS_REGION:-us-east-1}Note that I had to set AWS_REGION, even though it’s the default one (us-east-1).
Random jiggling (Hadoop JARs) 🔗
Some, or all, of these are needed, because $REASONS.
It’s a list I’ve built up by trial and error.
You can also just get Hadoop itself (lol, remember that?) and add it to the classpath.
If you don’t add these you’ll get various java.lang.ClassNotFoundException errors.
Feel free to play whack-a-mole and eliminate the redundant ones from the list and let me know which can be scratched off :)
https://repo1.maven.org/maven2/org/apache/commons/commons-configuration2/2.1.1/commons-configuration2-2.1.1.jar
https://repo1.maven.org/maven2/commons-logging/commons-logging/1.1.3/commons-logging-1.1.3.jar
https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-auth/3.3.4/hadoop-auth-3.3.4.jar
https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-common/3.3.4/hadoop-common-3.3.4.jar
https://repo1.maven.org/maven2/org/apache/hadoop/thirdparty/hadoop-shaded-guava/1.1.1/hadoop-shaded-guava-1.1.1.jar
https://repo1.maven.org/maven2/org/codehaus/woodstox/stax2-api/4.2.1/stax2-api-4.2.1.jar
https://repo1.maven.org/maven2/com/fasterxml/woodstox/woodstox-core/5.3.0/woodstox-core-5.3.0.jar
https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-hdfs-client/3.3.4/hadoop-hdfs-client-3.3.4.jar
https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-mapreduce-client-core/3.3.4/hadoop-mapreduce-client-core-3.3.4.jarKafka 🔗
Since I want to read from Kafka in the full example below, we need the Flink SQL Kafka connector.
The JAR is flink-sql-connector-kafka-3.4.0-1.20.jar.
JAR location 🔗
I put JARs in subfolders under ./lib to make it easier to organise and see what’s there:
lib
├── hadoop
│ ├── commons-configuration2-2.1.1.jar
│ ├── commons-logging-1.1.3.jar
│ ├── hadoop-auth-3.3.4.jar
│ ├── hadoop-common-3.3.4.jar
│ ├── hadoop-hdfs-client-3.3.4.jar
│ ├── hadoop-mapreduce-client-core-3.3.4.jar
│ ├── hadoop-shaded-guava-1.1.1.jar
│ ├── stax2-api-4.2.1.jar
│ └── woodstox-core-5.3.0.jar
├── iceberg
│ ├── iceberg-aws-bundle-1.9.1.jar
│ └── iceberg-flink-runtime-1.20-1.9.1.jar
├── kafka
│ └── flink-sql-connector-kafka-3.4.0-1.20.jarYou can also just put them straight under ./lib if you’d rather.
Checkpointing 🔗
You need to configure checkpointing in Flink in order for it to write data files. If you don’t then you’ll see metadata get written, but no actual data.
You can configure checkpointing within your SQL session by running:
SET 'execution.checkpointing.interval' = '30s';Smoke testing Iceberg/S3/Glue 🔗
Before we get data from Kafka into Iceberg, let’s just make sure the Iceberg/S3/Glue component is working.
This will launch a Flink SQL client if you’re using the Docker Compose that I’ve shared.
docker compose exec -it jobmanager bash -c "./bin/sql-client.sh"There are two ways to write an Iceberg table:
-
Explicitly, using the Iceberg connector in the table DDL
-
Implicitly, by declaring an Iceberg catalog in Flink and creating a table within it
Let’s check both.
Creating an Iceberg table in Flink SQL using the Iceberg connector 🔗
This will create a table called test01 in the Glue database my_glue_db.
CREATE TABLE test01 (col1 INT)
WITH (
'connector' = 'iceberg',
'catalog-name' = 'foo',
'catalog-database' = 'my_glue_db',
'warehouse' = 's3://rmoff-lakehouse/00/',
'catalog-impl' = 'org.apache.iceberg.aws.glue.GlueCatalog',
'ioImpl' = 'org.apache.iceberg.aws.s3.S3FileIO');
catalog-name is a mandatory configuration but as far as I can tell doesn’t have any impact on the written table, and is only used within Flink as part of the operator name.
|
Now write a row of data:
INSERT INTO test01 VALUES (42);[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 6742c18db85384825217b75fdb12b784|
At this point, all that’s happened is the job to write the data has been submitted. Don’t assume that because it was successfully submitted it’s been successfully executed! |
Check that the data has been written to the table:
Flink SQL> SELECT * FROM test01;
+----+-------------+
| op | col1 |
+----+-------------+
| +I | 42 |
+----+-------------+
Received a total of 1 row (6.77 seconds)Inspect the object storage:
$ aws s3 --recursive ls s3://rmoff-lakehouse/00
2025-06-24 16:44:34 423 00/my_glue_db.db/test01/data/00000-0-a2de3a7d-6075-4d80-a440-fb0e702ec4b8-00001.parquet
2025-06-24 16:44:28 874 00/my_glue_db.db/test01/metadata/00000-9808fb50-5694-4331-afb7-ee02fa7fa8ee.metadata.json
2025-06-24 16:44:36 1995 00/my_glue_db.db/test01/metadata/00001-a74b52b7-7fda-4e35-a044-17c2cae96aef.metadata.json
2025-06-24 16:44:35 6964 00/my_glue_db.db/test01/metadata/79f37e16-6b9d-491f-b96b-d4795b66bac1-m0.avro
2025-06-24 16:44:35 4455 00/my_glue_db.db/test01/metadata/snap-5270520003556673576-1-79f37e16-6b9d-491f-b96b-d4795b66bac1.avro|
If you only see |
You’ll see the table in the Glue data catalog:
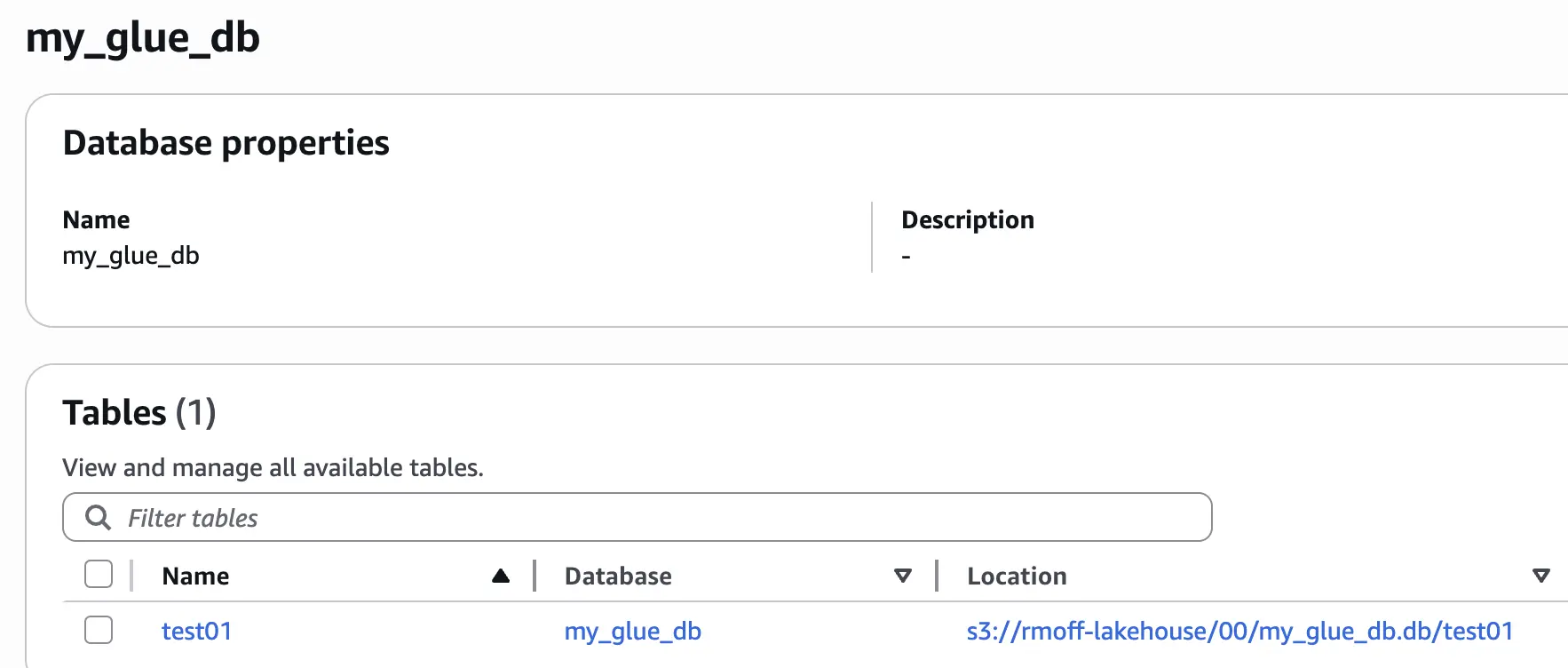
Creating a table in Flink SQL within an Iceberg catalog 🔗
The other route to creating an Iceberg table is to create a Flink SQL Catalog that is of an Iceberg type, pointing to the Glue data catalog.
😖 Whuuuhh what does this even mean? Find out more in this article that I wrote previously: Catalogs in Flink SQL—A Primer |
First create a catalog:
CREATE CATALOG my_iceberg_catalog WITH (
'type' = 'iceberg',
'warehouse' = 's3://rmoff-lakehouse/00/',
'catalog-impl' = 'org.apache.iceberg.aws.glue.GlueCatalog',
'io-impl' = 'org.apache.iceberg.aws.s3.S3FileIO'
);Set the catalog as the active one:
USE CATALOG my_iceberg_catalog;You can now see what Glue databases exist:
Flink SQL> SHOW DATABASES;
+------------------+
| database name |
+------------------+
| my_glue_db |
| rmoff_db |
| tmp |
+------------------+
3 rows in setIf you want, you can create a new database in Glue data catalog:
CREATE DATABASE new_glue_db;Now set the database (existing, or new) as the active one:
USE my_iceberg_catalog.new_glue_db;Finally, create and populate the new table:
CREATE TABLE test02 (col1 INT);
INSERT INTO test02 VALUES (42);The end result is the same as above - a table registered in the Glue data catalog, with Iceberg data stored in S3:
Flink SQL> SELECT * FROM test02;
+----+-------------+
| op | col1 |
+----+-------------+
| +I | 42 |
+----+-------------+
Received a total of 1 row (5.65 seconds)$ aws glue get-tables --region us-east-1 \
--database-name new_glue_db \
--query 'TableList[].Name' \
--output table
+----------+
| GetTables|
+----------+
| test02 |
+----------+$ aws s3 --recursive ls s3://rmoff-lakehouse/00
[…]
2025-06-24 17:32:51 423 00/new_glue_db.db/test02/data/00000-0-0c2f7b3e-6b84-44eb-add7-79ff16f7854d-00001.parquet
2025-06-24 17:32:42 679 00/new_glue_db.db/test02/metadata/00000-202c2e5e-db26-42cc-85df-a6e3c8b61b83.metadata.json
2025-06-24 17:32:53 1800 00/new_glue_db.db/test02/metadata/00001-2b15df7b-c93a-4cc8-a755-43e10afbeb44.metadata.json
2025-06-24 17:32:53 6963 00/new_glue_db.db/test02/metadata/6ef46eac-d442-40c8-bfaa-644cb84e5f0e-m0.avro
2025-06-24 17:32:53 4455 00/new_glue_db.db/test02/metadata/snap-4874299872284941836-1-6ef46eac-d442-40c8-bfaa-644cb84e5f0e.avroKafka → Iceberg (S3/Glue) 🔗
Now we can put this into practice, and use it to stream data from Kafka to Iceberg on S3, with Glue data catalog.
Define the Kafka source 🔗
Here’s a table that stores its data in Kafka.
I’m creating it outside of the Glue/Iceberg catalog because within it it always writes it as Iceberg.
Note that if you actually use the generic_in_memory catalog you’ll need to define your tables in every Flink session.
See Catalogs in Flink SQL—A Primer for more details.
CREATE CATALOG src WITH ('type'='generic_in_memory');
CREATE DATABASE src.kafka ;
CREATE TABLE src.kafka.kafka_transactions (
transaction_id STRING,
user_id STRING,
amount DECIMAL(10, 2),
currency STRING,
merchant STRING,
transaction_time TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = 'broker:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset',
'topic' = 'transactions'
);Now we’ll write some data to it:
INSERT INTO src.kafka.kafka_transactions VALUES
('TXN_001', 'USER_123', 45.99, 'GBP', 'Amazon', TIMESTAMP '2025-06-23 10:30:00'),
('TXN_002', 'USER_456', 12.50, 'GBP', 'Starbucks', TIMESTAMP '2025-06-23 10:35:00'),
('TXN_003', 'USER_789', 89.99, 'USD', 'Shell', TIMESTAMP '2025-06-23 10:40:00'),
('TXN_004', 'USER_123', 156.75, 'EUR', 'Tesco', TIMESTAMP '2025-06-23 10:45:00'),
('TXN_005', 'USER_321', 8.99, 'GBP', 'McDonald''s', TIMESTAMP '2025-06-23 10:50:00');Check the data’s there on the Kafka topic:
$ docker compose exec -it kcat kcat -b broker:9092 -C -t transactions -c5
{"transaction_id":"TXN_001","user_id":"USER_123","amount":45.99,"currency":"GBP","merchant":"Amazon","transaction_time":"2025-06-23 10:30:00"}
{"transaction_id":"TXN_002","user_id":"USER_456","amount":12.5,"currency":"GBP","merchant":"Starbucks","transaction_time":"2025-06-23 10:35:00"}
{"transaction_id":"TXN_003","user_id":"USER_789","amount":89.99,"currency":"USD","merchant":"Shell","transaction_time":"2025-06-23 10:40:00"}
{"transaction_id":"TXN_004","user_id":"USER_123","amount":156.75,"currency":"EUR","merchant":"Tesco","transaction_time":"2025-06-23 10:45:00"}
{"transaction_id":"TXN_005","user_id":"USER_321","amount":8.99,"currency":"GBP","merchant":"McDonald's","transaction_time":"2025-06-23 10:50:00"}💡 Send Kafka data to Iceberg using this one simple trick 😉 🔗
Now we create an Iceberg table, populated by what’s in the Kafka topic. It’s just a single SQL statement:
CREATE TABLE my_iceberg_catalog.my_glue_db.transactions AS
SELECT * FROM src.kafka.kafka_transactions;Flink then reads from the Kafka topic, and writes it to the Iceberg table. We can see the Iceberg table has been created in Glue data catalog:
$ aws glue get-tables --region us-east-1 \
--database-name my_glue_db \
--query 'TableList[].Name' \
--output table
------------------
| GetTables |
+----------------+
| test01 |
| transactions |
+----------------+and it’s been populated:
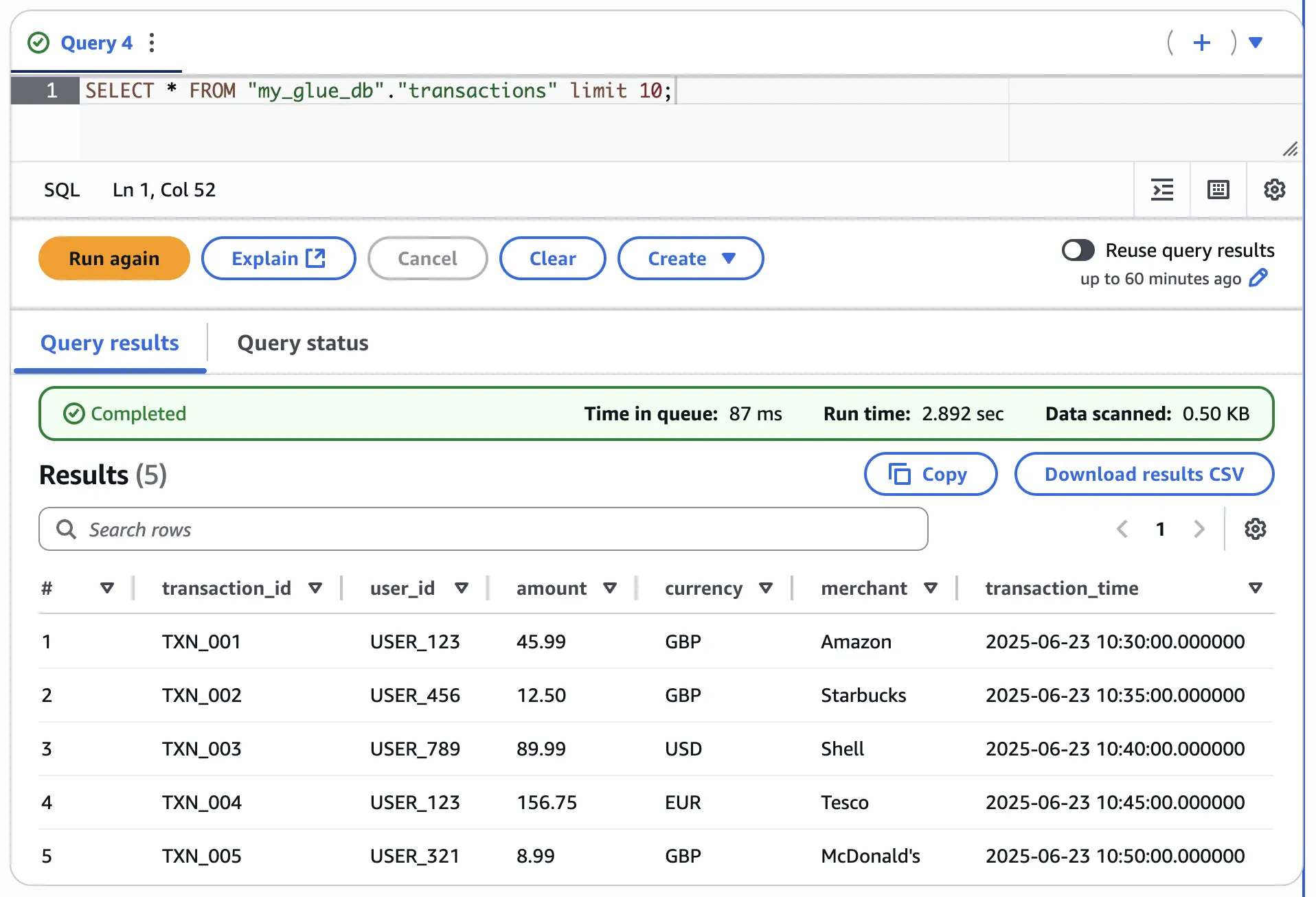
A Flink SQL CREATE TABLE…AS SELECT (known as CTAS) is a continuous query—a job that will run forever until you cancel it, executing the SELECT query and writing the results to the target table.
That means that if we add more rows to the source Kafka table (which is just a Kafka topic, and can be populated by any Kafka producer):
INSERT INTO src.kafka.kafka_transactions VALUES
('TXN_006', 'USER_456', 23.45, 'GBP', 'Wayne Enterprises', TIMESTAMP '2025-06-23 10:55:00'),
('TXN_007', 'USER_789', 67.80, 'USD', 'Stark Industries', TIMESTAMP '2025-06-23 11:00:00'),
('TXN_008', 'USER_654', 15.99, 'EUR', 'Daily Planet', TIMESTAMP '2025-06-23 11:05:00');we’ll shortly see the same data appear on the Iceberg table:
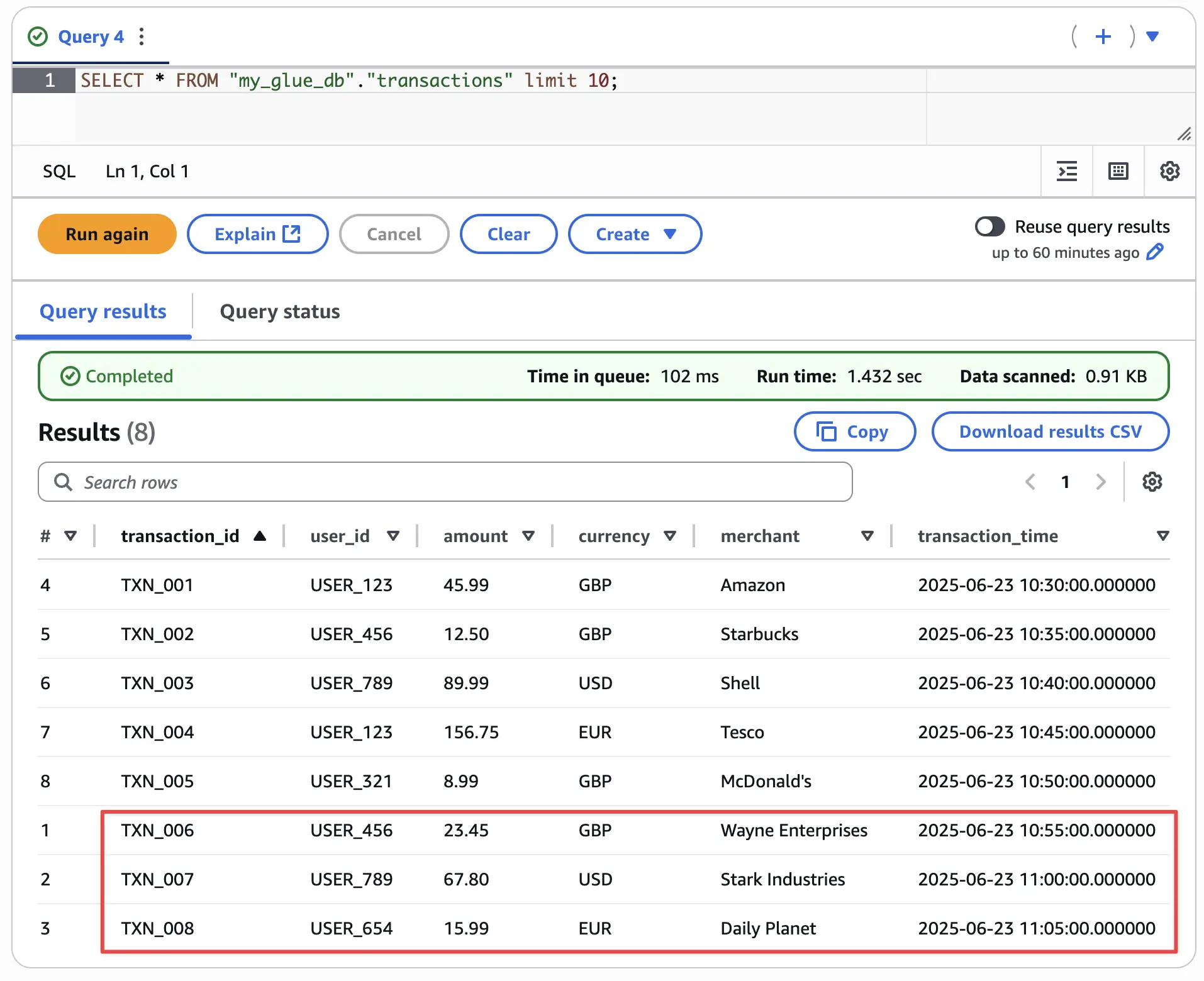
INSERT OVERWRITE 🔗
Iceberg tables can be written to using:
In the examples above we’ve used INSERT INTO, either explicitly to populate an existing table, or implicitly with the CREATE TABLE…AS SELECT statement.
You can use INSERT OVERWRITE to overwrite the existing tables contents.
This sounds useful for things like refreshing dimension tables if you don’t want to retain history (a.k.a Slowly Changing Dimension Type 0).
Here’s the intial state of the table:
USE my_iceberg_catalog.new_glue_db;
CREATE TABLE dim01 (id INT, name STRING);
INSERT INTO dim01 VALUES
(42, 'foo'),
(43, 'bar');Flink SQL> SELECT * FROM dim01;
+----+-------------+--------------------------------+
| op | id | name |
+----+-------------+--------------------------------+
| +I | 42 | foo |
| +I | 43 | bar |
+----+-------------+--------------------------------+
Received a total of 2 rows (7.19 seconds)
Flink SQL>Now to overwrite it.
INSERT OVERWRITE is only available in a batch Flink job, so we set that first:
SET 'execution.runtime-mode' = 'batch';and then overwrite the data:
INSERT OVERWRITE dim01 VALUES
(1, 'wibble');Flink SQL> SELECT * FROM dim01;
+----+--------+
| id | name |
+----+--------+
| 1 | wibble |
+----+--------+
1 row in set (5.80 seconds)I wonder if this could also be useful when working with fact data that’s partitioned by date, and you want to refresh an entire partition—perhaps with data that was late and you now have a complete picture of the day.
-- Create a partitioned table
CREATE TABLE orders (
id INT,
amount DECIMAL(10,2),
order_date DATE
) PARTITIONED BY (
order_date);
-- Populate it
INSERT INTO orders VALUES
(1, 100.50, DATE '2024-06-24'),
(2, 200.75, DATE '2024-06-24'),
(3, 150.25, DATE '2024-06-25');With the table populated you’ll see the data is physically partitioned on disk, with the data files under a folder path that includes the partition value (e.g. /order_date=2024-06-24/)
$ aws s3 --recursive ls s3://rmoff-lakehouse/00/my_glue_db.db/orders/
2025-06-25 11:07:24 1020 00/my_glue_db.db/orders/data/order_date=2024-06-24/00000-0-9a3c536e-cf26-43ad-940f-dde15931e3c1-00001.parquet
2025-06-25 11:07:24 985 00/my_glue_db.db/orders/data/order_date=2024-06-25/00000-0-9a3c536e-cf26-43ad-940f-dde15931e3c1-00002.parquet
[…]Query the table:
Flink SQL> SELECT * FROM orders;
+----+--------+------------+
| id | amount | order_date |
+----+--------+------------+
| 1 | 100.50 | 2024-06-24 |
| 2 | 200.75 | 2024-06-24 |
| 3 | 150.25 | 2024-06-25 |
+----+--------+------------+
3 rows in set (7.76 seconds)Now let’s replace the data for 2024-06-24, leaving 2024-06-25 untouched:
INSERT OVERWRITE orders PARTITION(order_date='2024-06-24')
VALUES
(1, 100.50),
(2, 200.75),
(5, 42.00),
(7, 43.21);Flink SQL> SELECT * FROM orders;
+----+--------+------------+
| id | amount | order_date |
+----+--------+------------+
| 3 | 150.25 | 2024-06-25 |
| 1 | 100.50 | 2024-06-24 |
| 2 | 200.75 | 2024-06-24 |
| 5 | 42.00 | 2024-06-24 |
| 7 | 43.21 | 2024-06-24 |
+----+--------+------------+
5 rows in set (7.79 seconds)Note that Flink enforces something to stop you being stupid; you can’t specify the partition value in the INSERT values because you’d risk ending up with inconsistent data.
Flink SQL> INSERT OVERWRITE orders PARTITION(order_date='2024-06-24')
> VALUES
> (1, 100.50, DATE '2024-06-23'),
> (2, 200.75, DATE '2024-06-24'),
> (5, 42.00, DATE '2024-06-27'),
> (7, 43.21, DATE '2024-06-24');
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.ValidationException: Column types of query result and sink for 'my_iceberg_catalog.my_glue_db.orders' do not match.
Cause: Different number of columns.
Query schema: [EXPR$0: INT NOT NULL, EXPR$1: DECIMAL(5, 2) NOT NULL, EXPR$2: DATE NOT NULL, EXPR$3: DATE NOT NULL]
Sink schema: [id: INT, amount: DECIMAL(10, 2), order_date: DATE]UPSERT 🔗
Whereas INSERT OVERWRITE says "write this data over whatever may be there already", an UPSERT is a more courteous operation, telling Flink to "write this data, and if the key exists already update it, and if not, insert it".
Let’s see it in action.
To start with, you need a key on your table—since the whole point of an UPSERT is that it’ll match on the key to determine whether it’s an UPDATE (the key exists already) or an INSERT (it doesn’t).
CREATE TABLE inventory (
product_id INT,
product_name STRING,
quantity INT,
PRIMARY KEY (product_id) NOT ENFORCED
);
INSERT INTO inventory VALUES
(101, 'Running shoes', 50),
(102, 'GPS watch', 1),
(103, 'Gels', 30);Flink SQL> SELECT * FROM inventory;
+------------+---------------+----------+
| product_id | product_name | quantity |
+------------+---------------+----------+
| 102 | GPS watch | 1 |
| 103 | Gels | 30 |
| 101 | Running shoes | 50 |
+------------+---------------+----------+
3 rows in set (5.50 seconds)To use UPSERT it’s the same INSERT INTO syntax, but UPSERT is set as a configuration.
This can be at the query level, using a query hint:
INSERT INTO inventory
/*+ OPTIONS('upsert-enabled'='true') */ (1)
VALUES (102, 'GPS watch ⌚', 5);| 1 | Upsert query hint |
Flink SQL> SELECT * FROM inventory;
+------------+---------------+----------+
| product_id | product_name | quantity |
+------------+---------------+----------+
| 102 | GPS watch ⌚ | 5 |
| 103 | Gels | 30 |
| 101 | Running shoes | 50 |
+------------+---------------+----------+
3 rows in set (10.40 seconds)You can also configure a table to use UPSERT always:
ALTER TABLE inventory SET ('write.upsert.enabled'='true');INSERT INTO inventory VALUES
(103, 'Gels 🍫', 28);Flink SQL> SELECT * FROM inventory;
+------------+---------------+----------+
| product_id | product_name | quantity |
+------------+---------------+----------+
| 103 | Gels 🍫 | 28 |
| 102 | GPS watch ⌚ | 5 |
| 101 | Running shoes | 50 |
+------------+---------------+----------+
3 rows in set (11.61 seconds)Examining Iceberg metadata 🔗
The Iceberg docs for Flink are pretty comprehensive. Something else that caught my eye when perusing them was the metadata tables.
Each Iceberg table has a bunch of metadata associated with it, covering things like physical data file locations, snapshots, manifests, and so on.
For my RDBMS readers, you can think of these as the equivalent of V$ tables in Oracle, pg_* tables in Postgres, etc.
You can find details of the tables in the Iceberg docs.
The tables themselves are a suffix that you append to your actual table name.
So if you want to see the list of files for a table called foo, you’d query table foo$files.
Here’s a list of the tables/suffixes:
-
$history -
$metadata_log_entries -
$snapshots -
$files -
$manifests -
$partitions -
$all_data_files -
$all_manifests -
$refs
For example, to look at the snapshots associated with the dim01 table above:
Flink SQL> DESCRIBE dim01$snapshots;
+---------------+---------------------------------------+-------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+---------------+---------------------------------------+-------+-----+--------+-----------+
| committed_at | TIMESTAMP_LTZ(6) | FALSE | | | |
| snapshot_id | BIGINT | FALSE | | | |
| parent_id | BIGINT | TRUE | | | |
| operation | STRING | TRUE | | | |
| manifest_list | STRING | TRUE | | | |
| summary | MAP<STRING NOT NULL, STRING NOT NULL> | TRUE | | | |
+---------------+---------------------------------------+-------+-----+--------+-----------+
6 rows in setFlink SQL> SELECT committed_at, snapshot_id, operation, summary from dim01$snapshots;
+----------------------------+---------------------+-----------+--------------------------------+
| committed_at | snapshot_id | operation | summary |
+----------------------------+---------------------+-----------+--------------------------------+
| 2025-06-25 09:45:55.390000 | 1088585618716047739 | append | {flink.operator-id=90bea66d... |
| 2025-06-25 09:49:12.844000 | 8184558532161473513 | overwrite | {flink.operator-id=90bea66d... |
+----------------------------+---------------------+-----------+--------------------------------+
2 rows in set (3.75 seconds)Appendix: Troubleshooting 🔗
A managed table factory that implements org.apache.flink.table.factories.ManagedTableFactory is not in the classpath. 🔗
Can you spot the error here?
Flink SQL> CREATE CATALOG my_iceberg_catalog WITH (
> 'type' = 'iceberg',
> 'warehouse' = 's3://rmoff-lakehouse/00/',
> 'catalog-impl' = 'org.apache.iceberg.aws.glue.GlueCatalog',
> 'io-impl' = 'org.apache.iceberg.aws.s3.S3FileIO'
> );
[INFO] Execute statement succeeded.
Flink SQL> CREATE TABLE dim01 (id INT, name STRING);
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.ValidationException: Table options do not contain an option key 'connector' for discovering a connector. Therefore, Flink assumes a managed table. However, a managed table factory that implements org.apache.flink.table.factories.ManagedTableFactory is not in the classpath.I’ve created the Iceberg catalog, and then the table within it. Except I didn’t!
I created the Iceberg catalog, and then created a table in the current catalog and database:
Flink SQL> SHOW CURRENT CATALOG;
+----------------------+
| current catalog name |
+----------------------+
| default_catalog |
+----------------------+
1 row in set
Flink SQL> SHOW CURRENT DATABASE;
+-----------------------+
| current database name |
+-----------------------+
| default_database |
+-----------------------+
1 row in setBefore creating the table I need to either fully qualify the table name:
Flink SQL> CREATE TABLE my_iceberg_catalog.my_glue_db.dim01 (id INT, name STRING);
[INFO] Execute statement succeeded.or change the current catalog and database for the session first:
Flink SQL> USE my_iceberg_catalog.my_glue_db;
[INFO] Execute statement succeeded.
Flink SQL> CREATE TABLE dim02 (id INT, name STRING);
[INFO] Execute statement succeeded.