
SQL. Three simple letters.
Ess Queue Ell.
/ˌɛs kjuː ˈɛl/.
In the data world they bind us together, yet separate us.
As the saying goes, England and America are two countries divided by the same language, and the same goes for the batch and streaming world and some elements of SQL.
In Flink SQL all objects are tables. So how does Flink SQL deal with the idea of a 'table' that in the RDBMS world is a static lump of data (a.k.a. 'bounded'), but in Flink’s world can be either bounded or unbounded (streaming)?
The answer is what the Flink docs call Dynamic Tables and changelogs. Some of this will be visible to you, and some of it won’t unless you go poking around for it.
| Bear in mind that a table is a table in Flink SQL; you don’t go and declare a "dynamic table"; it’s a conceptual thing. |
In this blog post I’m going to start with a simple SELECT * FROM and build up from there, looking at the changelog implications at each stage along the way.
In particular, I’m going to learn the hard way what happens when you take a LEFT OUTER JOIN from a regular RDBMS and chuck it into Flink SQL without understanding the implications…
Getting Started 🔗
I’m using a local Apache Flink 2.0 environment running under Docker Compose that you can spin up from here.
First we’ll create a simple orders fact table and customers dimension table, using Kafka to hold the data.
CREATE TABLE orders (
order_id STRING,
customer_id STRING,
order_date TIMESTAMP(3),
total_amount DECIMAL(10, 2),
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka', (1)
'topic' = 'orders',
'properties.bootstrap.servers' = 'broker:9092',
'key.format' = 'json',
'value.format' = 'json'
);
CREATE TABLE customers (
customer_id STRING,
name STRING,
PRIMARY KEY (customer_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka', (1)
'topic' = 'customers',
'properties.bootstrap.servers' = 'broker:9092',
'key.format' = 'json',
'value.format' = 'json'
);| 1 | I’m using the upsert-kafka connector here, which has implications for the changelog.
For a fact (append-only) table you’d typically use the kafka connector instead, and use the upsert-kafka connector for dimensional data that may change.
I get into this detail later in the post. |
Now we’ll populate both tables with a light sprinkling of data:
INSERT INTO orders (order_id, customer_id, order_date, total_amount)
VALUES
('1001', 'CUST-5678', TIMESTAMP '2025-05-09 14:30:00', 199.99),
('1002', 'CUST-9012', TIMESTAMP '2025-05-09 15:45:00', 349.50),
('1003', 'CUST-5678', TIMESTAMP '2025-05-09 16:15:00', 75.25);INSERT INTO customers (customer_id, name)
VALUES
('CUST-3456', 'Yelena Belova'),
('CUST-5678', 'Bucky Barnes'),
('CUST-9012', 'Valentina Allegra de Fontaine');What could be more simple than a SELECT? 🔗
SELECT * FROM orders;This gives us this:

Notice how the Updated: keeps changing?
That’s because it’s a streaming query, and if I add another row to the table, it’ll appear in the results.
What about if we switch the result-mode from the default table to tableau:
SET 'sql-client.execution.result-mode' = 'tableau';
Now we get a new column, op—short for "operation".
This shows us the changelog view of what’s going on when the query is executing.
In this case the three rows are all +I for INSERT.
Probably the simplest example of a changelog other than just +I (i.e. append-only) is an aggregate, in which the value changes as new data is read:
Flink SQL> SELECT COUNT(*) AS order_ct FROM orders;
+----+----------------------+
| op | order_ct |
+----+----------------------+
| +I | 1 | (1)
| -U | 1 | (2)
| +U | 2 | (2)
| -U | 2 |
| +U | 3 || 1 | The first order is read and so the count is 1, which is +I to the query output. |
| 2 | When the next order is read the count becomes two.
For the purposes of the changelog, this is first a -U operation to remove the existing value, and then a +U to replace it. |
| You can learn more about continuous queries and stateful operators and pipelines in the docs. |
The different operations have terms that you can find mentioned in the Flink docs:
| Operation | Description |
|---|---|
|
|
|
|
|
|
|
|
Update operations don’t have to be for an aggregate.
Here’s another example in which an UPDATE_AFTER is used to remove a row that no longer matches a query predicate.
Here’s the original orders query, now with a predicate:
Flink SQL> select * from orders WHERE total_amount >70;
+----+-----------+--------------+-------------------------+--------------+
| op | order_id | customer_id | order_date | total_amount |
+----+-----------+--------------+-------------------------+--------------+
| +I | 1002 | CUST-9012 | 2025-05-09 15:45:00.000 | 349.50 |
| +I | 1001 | CUST-5678 | 2025-05-09 14:30:00.000 | 199.99 |
| +I | 1003 | CUST-5678 | 2025-05-09 16:15:00.000 | 75.25 | (1)| 1 | The total_amount for order 1003 is 75.25 and thus meets the predicate total_amount >70 |
Leaving this query running, in a second Flink SQL session I add another row to the orders table for an existing value of the primary key (order_id), order 1003:
INSERT INTO orders (order_id, customer_id, order_date, total_amount)
VALUES ('1003', 'CUST-5678', TIMESTAMP '2025-05-09 16:15:00', 65.25);The total_amount value is now outside the predicate.
The output from the SELECT is updated to retract this record.
Flink SQL> select * from orders WHERE total_amount >70;
+----+-----------+--------------+-------------------------+--------------+
| op | order_id | customer_id | order_date | total_amount |
+----+-----------+--------------+-------------------------+--------------+
[…]
| -U | 1003 | CUST-5678 | 2025-05-09 16:15:00.000 | 75.25 | (1)Changelogs in JOINs 🔗
What about when we do a JOIN?
This is where it gets interesting!
(interesting, as in the curse, "may you live in interesting times")
Let’s join the orders to the customers to find out the name of the customer who placed the respective order.
Anyone with half a background in RDBMS will probably write a SQL query that looks something like this (give or take some tabs/spaces, and capitalisation or otherwise of keywords…):
SELECT o.order_id,
o.total_amount,
c.name
FROM orders o
LEFT OUTER JOIN
customers c
ON o.customer_id = c.customer_id
WHERE order_id='1001';This is a LEFT OUTER JOIN.
You’ll sometimes see it written as LEFT JOIN; it means that it’ll always return the row on the left (based on the order of the ON predicate), and if there is a match the value on the right, and if not a NULL.
To learn more about the different types of JOIN see these articles (and learn why you shouldn’t use Venn diagrams to represent the different JOIN types).
|
What’s really cool with the changelog view is that we get an insight into how the query gets run:
+----+-----------+--------------+---------------+
| op | order_id | total_amount | name |
+----+-----------+--------------+---------------+
| +I | 1001 | 199.99 | <NULL> | (1)
| -D | 1001 | 199.99 | <NULL> | (2)
| +I | 1001 | 199.99 | Bucky Barnes | (3)| 1 | The orders row is first emitted with only the left side of the join; the order_id and total_amount, with no match for customers so a <NULL> in name. |
| 2 | The customers source catches up and is matched, so Flink retracts the <NULL> with a -D |
| 3 | Flink restates the record with a +I that includes the full record value this time |
What happens if you update the customer data? 🔗
Out of interest, I added a couple of new records to the customers table, using the same customer_id and thus representing a logical update to the record.
Here’s what happened:
+----+--------------------------------+--------------+--------------------------------+
| op | order_id | total_amount | name |
+----+--------------------------------+--------------+--------------------------------+
| -U | 1001 | 199.99 | Bucky Barnes |
| +I | 1001 | 199.99 | <NULL> | (1)
| -D | 1001 | 199.99 | <NULL> | (2)
| +I | 1001 | 199.99 | Fred Flintstone | (3)| 1 | First, the existing record is replaced with a <NULL> |
| 2 | Then the <NULL> is removed (with a -D, compared to a -U above) |
| 3 | The new value is written |
So each time the customer data changes, the order is re-emitted with the updated customer information.
This pattern continued for as long as I continued making changes to the relevant record on customers, which got me to thinking: how long is Flink holding these values from each side of the join in order to emit an updated join result if one changes?
Staying Regular 🔗
The above join, a humble LEFT OUTER JOIN (or LEFT JOIN if you prefer brevity), is what’s known as a regular join.
In Flink SQL regular joins have particular execution characteristics. Per the docs:
it requires to keep both sides of the join input in Flink state forever. Thus, the required state for computing the query result might grow infinitely depending on the number of distinct input rows of all input tables and intermediate join results
💥 Here’s the batch-based SQL world meeting the streaming one!
In batch, we resolve the join once and once only, because we have a bounded set of data.
In the streaming world the data is unbounded and so we need to decide what to do if a join’s results are changed by the arrival of a new record on either side.
Using the standard SQL JOIN syntax you get an updated result from the JOIN any time a new row arrives that impacts the result.
If you’ve got big volumes of data coming through your pipeline, this might cause problems.

The YOLO approach: discarding state in regular joins 🔗
One way to avoid this, assuming you don’t want to get updated results, is to tell Flink to discard the state after a period of time. You configure this by setting a 'time to live' (TTL) for the state:
SET 'table.exec.state.ttl'='5sec';Any new customers records arriving after this time will not cause a new join result to be issued. New records on orders will continue to be emitted as they arrive, joining to the latest result on customers.
However, this is a relatively crude—if effective—approach that can end up with different results each time you run it depending on when records arrive.
Imagine you have a pipeline in which a customer update arrives after the TTL has expired. Flink will ignore it, per the configuration. The order(s) it relates to therefore only be passed downstream with the original customer details. Now we re-run the pipeline, and since the customer update has already arrived, will be processed by Flink within the 5 second TTL timeout, and now the same orders get joined to the newer version of the customer data.
Perhaps this is what you want, or a tolerable compromise to make. But it’s very important to be aware of it because you’re changing the data that’s being passed downstream. Flink will do exactly what you tell it to, including sending "wrong" data if you tell it to. Only you can decide if it’s "wrong" though, per the business requirements of the system.
In short, we’re relying on execution logic and the vagaries of when a record might arrive to implement what is business logic (which version of customer data should we use to join to the order; should we wait for any changes to that data and if so for how long). The rest of the business logic resides in the SQL; let’s see how we can do this for the join logic too.
Temporal joins 🔗
If we’re going to really adopt SQL in the streaming world we need to break free from the training wheels of regualar joins, and instead embrace temporal joins.

As the name suggests, a temporal join uses time as an element in evaluating the join. This way we can encode in the SQL statement what logic we actually want to use in the join. Combined with watermarks Flink gives us a powerful way to express if, and for how long, we want to continue to wait for a match or update in the join result. This avoids the exploding state problem, whilst also formalising the expected results from a query.
Temporal joins are enabled through Flink’s versioned tables feature.
Here’s the same query as above but with a temporal join.
Flink will use the event time (order_date) and look at the state of customers at that time to determine the value of the corresponding record (if there is one).
SELECT o.order_id,
o.total_amount,
c.name
FROM orders AS o
LEFT OUTER JOIN
customers
FOR SYSTEM_TIME AS OF o.order_date (1)
AS c
ON o.customer_id = c.customer_id;| 1 | Ahoy there, temporal join! |
Before we can do it we need to update the definitions of the tables, otherwise we get:
org.apache.flink.table.api.ValidationException:
Temporal table join currently only supports 'FOR SYSTEM_TIME AS OF' left table's time attribute fieldThe left table is orders, which does have order_date but not defined as a time attribute field.
This is what caught me out with watermarks the first time round too; read this bit here of my blog to understand more about time attribute fields in Flink SQL if you need to.
We’ll add an event time attribute to orders using the order_date field and a five second lag in the watermark strategy, to allow for out of order records to arrive within that time frame:
ALTER TABLE orders
ADD WATERMARK FOR `order_date` AS `order_date` - INTERVAL '5' SECONDS;Having done that, we still get an error when we try the temporal join query again:
org.apache.flink.table.api.ValidationException:
Event-Time Temporal Table Join requires both primary key and row time attribute in versioned table, but no row time attribute can be found.In short, we’ve added a time attribute to orders but not customers, and if we’re joining based on time, we need one.
But whilst orders has the obvious order_date event time column, customers doesn’t.
We could use a standard data modelling technique—which is good practice anyway—and have a valid_from / valid_to set of columns on the customers table.
That way we can report on order data based on the customer value at the time of the order.
What we’re going to do here is simpler.
We’ll just take the timestamp of the Kafka records that customers is built from and use that as the event time attribute.
ALTER TABLE customers
ADD `record_time` TIMESTAMP(3) METADATA FROM 'timestamp';
ALTER TABLE customers
ADD WATERMARK FOR `record_time` AS `record_time`;Now when we run the query we get… nothing:
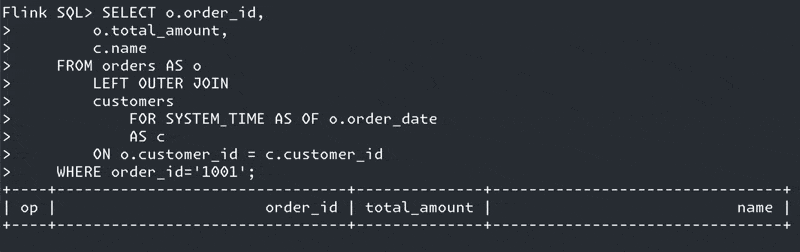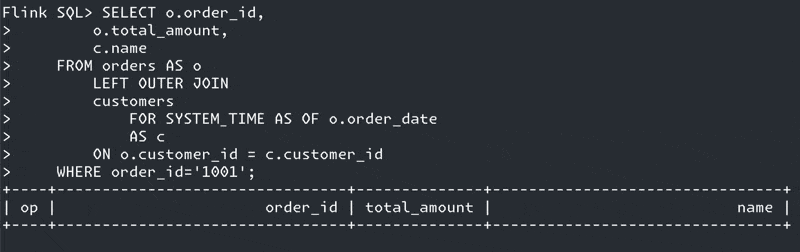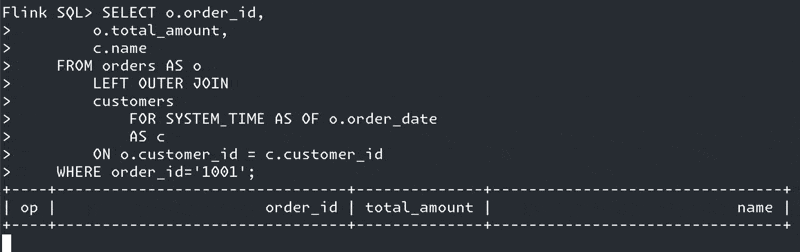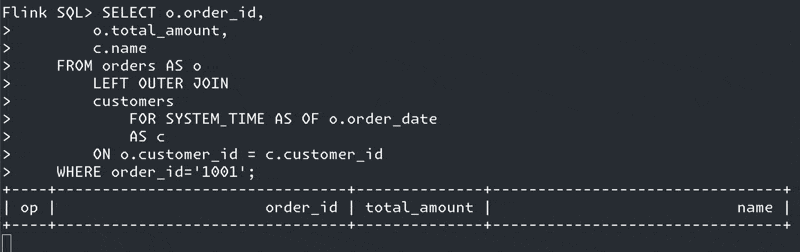
Why?

Watermarks. It’s always watermarks.
Looking at the Apache Flink dashboard we can see the orders source is producing a watermark, whilst the customers source isn’t.
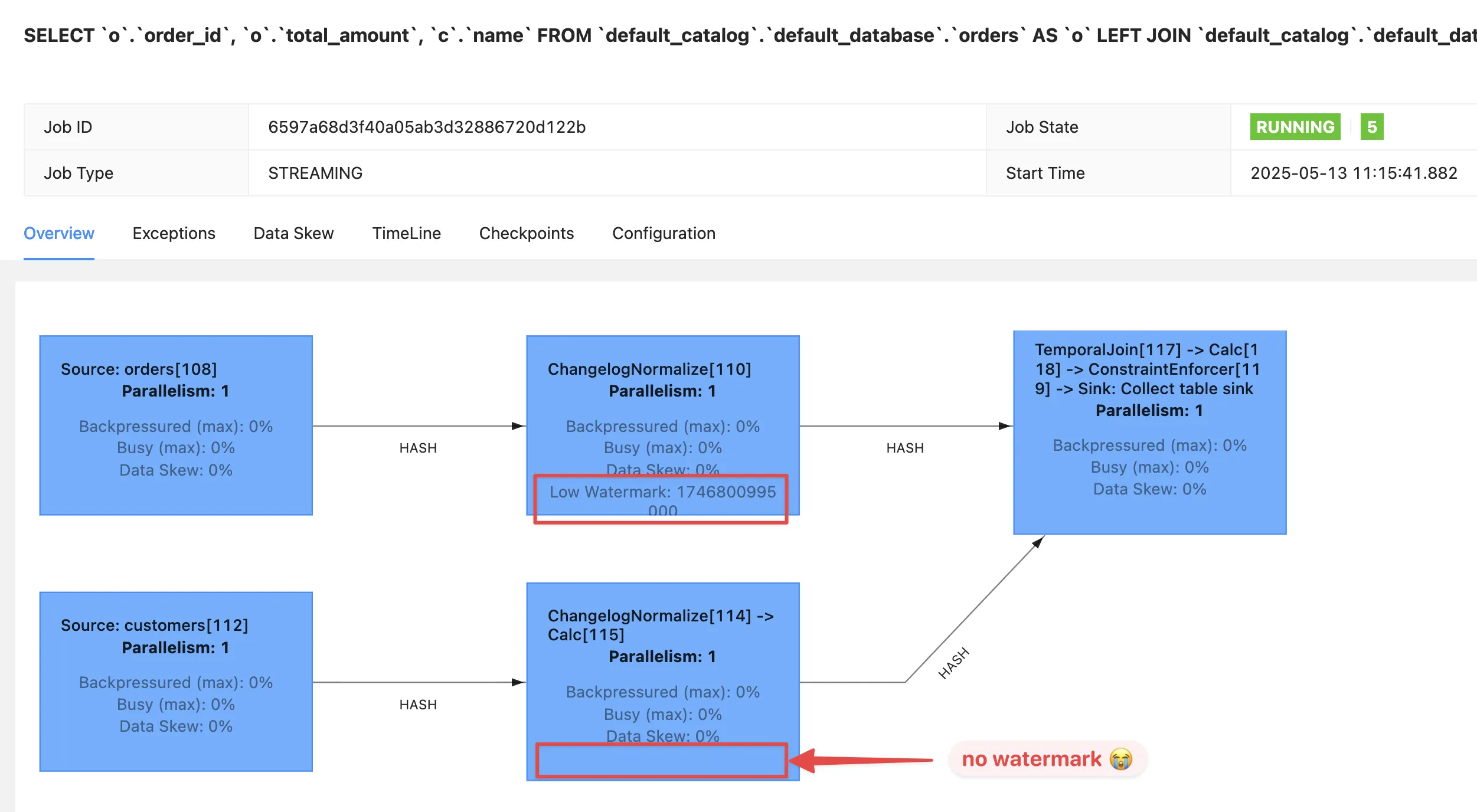
In this case it’s our friend the idle partition.
We can verify this by looking at the topic partitions in which the customer data resides.
Since Flink doesn’t store the data per se, but is just reading it from a Kafka topic, I’m going to create a second Flink table over the same customers topic in order to examine the partitions, whilst leaving the current customers unchanged:
Flink SQL> CREATE TABLE customers_tmp (
topic_partition INT METADATA FROM 'partition',
customer_id STRING,
name STRING,
`record_time` TIMESTAMP(3) METADATA FROM 'timestamp',
WATERMARK FOR `record_time` AS `record_time`,
PRIMARY KEY (customer_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'customers',
'properties.bootstrap.servers' = 'broker:9092',
'key.format' = 'json',
'value.format' = 'json'
);
Flink SQL> SELECT topic_partition, customer_id FROM customers_tmp;
+----+-----------------+--------------------------------+
| op | topic_partition | customer_id |
+----+-----------------+--------------------------------+
| +I | 2 | CUST-5678 |
| +I | 1 | CUST-3456 |
| +I | 1 | CUST-9012 |Since there’s no record in partition 0, the customers operator won’t generate a watermark.
But why does a lack of a watermark on customers stop the join from working?
At this point we need to handle two separate paths of logic when mentally evaluating this LEFT OUTER JOIN:
-
Just as in an RDBMS batch world, what are the rows of data on the left of the join, and are there any matching to return as part of a
LEFT OUTER JOIN? -
Since the processing is time-based, for what point in time does Flink consider each source to be complete?
This is defined by the current watermark, and watermarks are generated by each source and allow for any records that may have arrived out of order (as defined by the watermark generation stategy). In the case of
customerswe’re not allowing for that (WATERMARK FOR record_time AS record_time) and onorderswe are allowing a five second grace (WATERMARK FOR order_date AS order_date - INTERVAL '5' SECONDS).To determine the watermark for the join operator Flink will take the watermarks from the two source operators (
ordersandcustomers) and choose the earlier of the two. If either is null, then the watermark for the join operator will also be null.The watermark on the join operator defines the point in time at which Flink considers data to have arrived for both sides of the join, and thus ready to be emitted, based on the
LEFT OUTER JOINconditions (per point (1) above).If the watermark is null (or earlier than the records in the tables being joined), then the join operator won’t emit records because Flink can’t be sure that there might not be out of order records still to arrive.
In this instance, Flink hasn’t got a watermark from the customers source (because of the idle partition), and thus the join operator doesn’t have a watermark, meaning that it cannot emit any rows yet because logically it doesn’t know if there may be more to arrive before considering that point in time complete.
To fix this we’ll configure the customers table to ignore partitions that are idle for longer than five seconds:
ALTER TABLE customers
SET ('scan.watermark.idle-timeout'='5 sec');Now when we re-run the same query, we get a watermark generated by the customers operator:
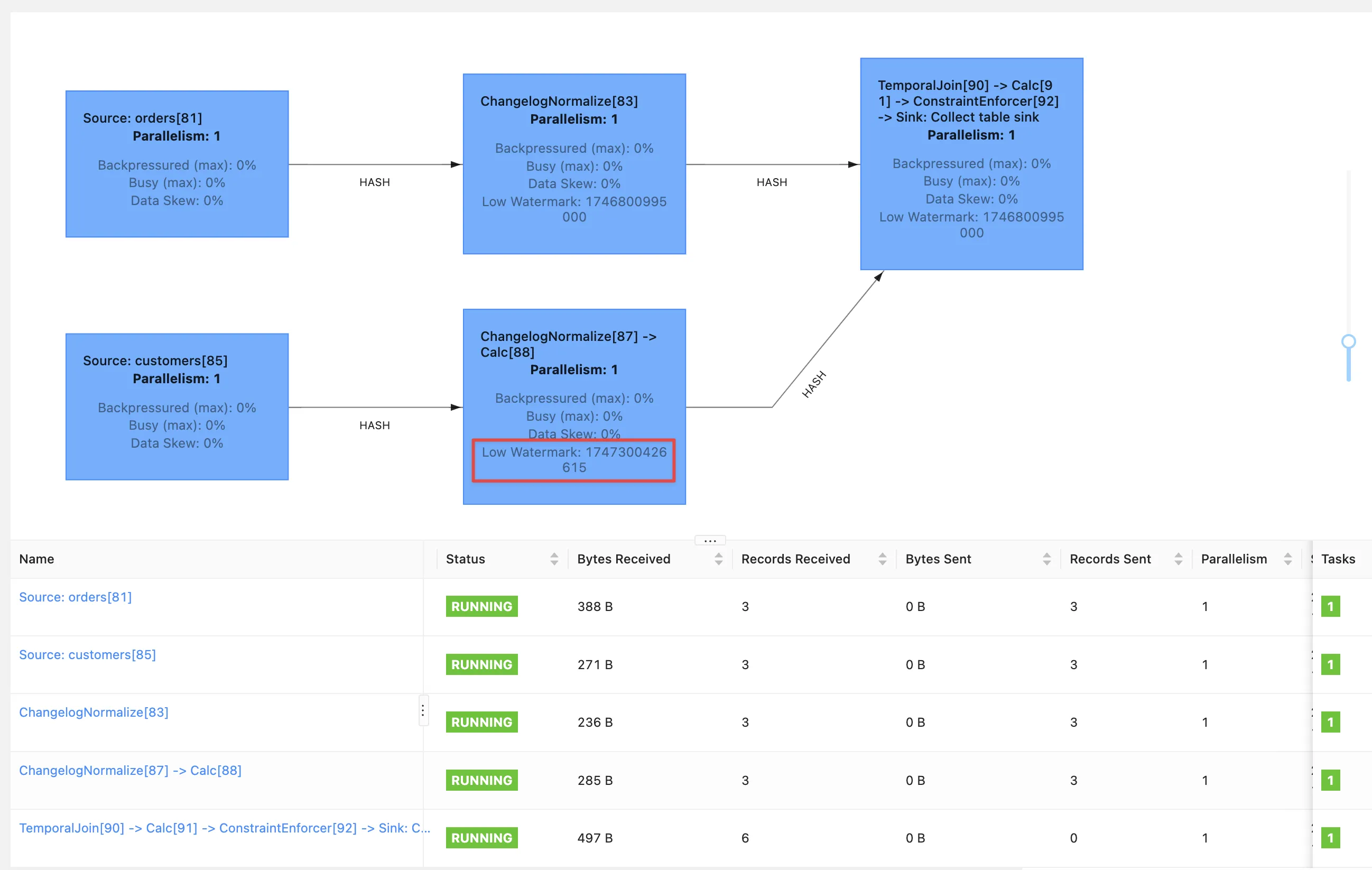
BUT we still don’t get any query results!
If you look closely at the screenshot above you’ll see that the Records Sent for each source operator is 3 (three orders, three customers), and the join operator has received six records (2x3 = 6). However, our query is still stubbornly stuck showing no results from the join:
Why?

Watermarks!! 🤪 😭
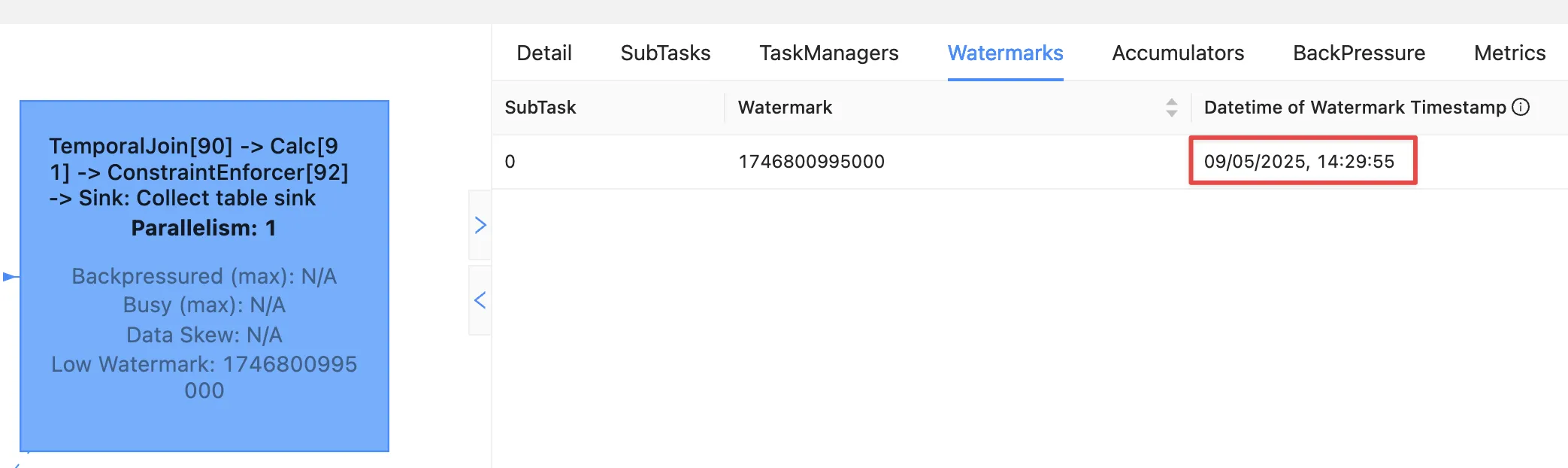
This time it’s not the absence of a watermark (as above), it’s the fact that the watermark on the join operator exists, and is earlier than any of the records received. Since the watermark is earlier, then Flink will not emit the records.
|
A quick aside; why is the watermark Let’s look at the operator watermarks in the Flink UI (I’ve overlaid the translation from epoch milliseconds to make it easier to follow): 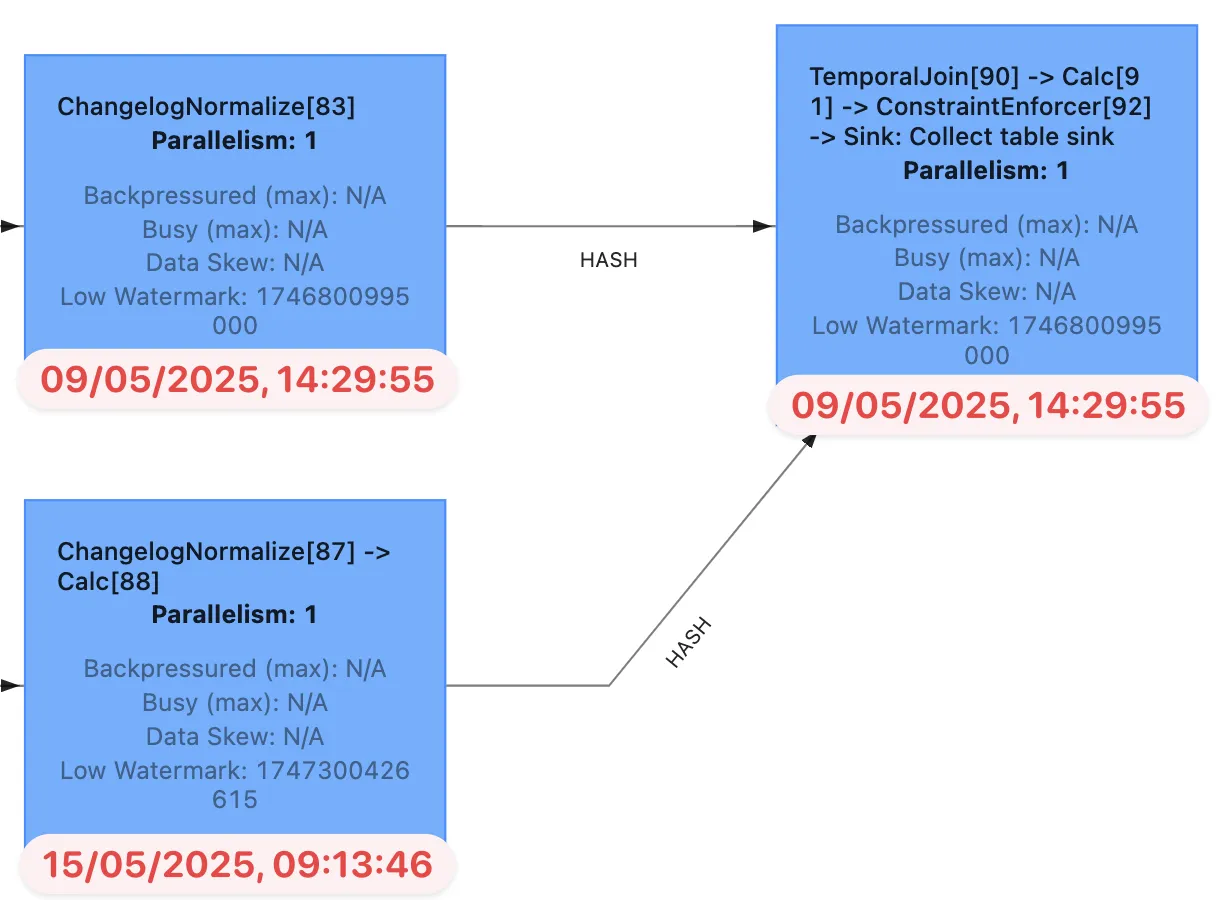
The downstream operator (in this case, the join operator) will take the earliest of the upstream watermarks. The
|
Fixing the stuck watermark 🔗
To advance the watermark, we need to give Flink another record with an event time later than the current watermark.
INSERT INTO orders (order_id, customer_id, order_date, total_amount)
VALUES ('1042', 'CUST-5678', TIMESTAMP '2025-05-09 15:50:00', 42.00);But the watermark stays stuck and still no data. This is because my Kafka topic is partitioned, and whilst I’ve moved the watermark on for partition 0 (where the new order, 1042, happened to end up) the overall watermark for the orders operator remains the same (2025-05-09 14:29:55.000):
+----+-----------------+-----------+-------------------------+-------------------------+
| op | topic_partition | order_id | order_date | expected_watermark |
+----+-----------------+-----------+-------------------------+-------------------------+
| +I | 0 | 1002 | 2025-05-09 15:45:00.000 | 2025-05-09 15:44:55.000 |
| +I | 0 | 1042 | 2025-05-09 15:50:00.000 | 2025-05-09 15:49:55.000 | (1)
| +I | 1 | 1001 | 2025-05-09 14:30:00.000 | 2025-05-09 14:29:55.000 | (2)
| +I | 2 | 1003 | 2025-05-09 16:15:00.000 | 2025-05-09 16:14:55.000 || 1 | New record sets the watermark for partition 0 |
| 2 | Existing record in partition 1 is still the lowest across the watermarks of the three partitions |
At this point we could keep firing records into the orders table until we manage to tip each partition’s watermark forward. However, a more sensible approach would be to configure an idle timeout, since that’s what in effect is hitting here; partitions 1 and 2 are idle but Flink is still using their watermarks instead of ignoring them.
ALTER TABLE orders
SET ('scan.watermark.idle-timeout'='5 sec');
If you’re running these queries in multiple windows, remember that the table definition is local to the session only, so you need to run the ALTER on each session.
Guess how I discovered this ;)
|
This itself doesn’t trigger any change in the query results (which are still running in a separate session), because there’s no new data to trigger the watermark generation. And when I run the query again…still no results. Why? Because the idle timeout is based on the wallclock. That means that when I re-ran the query the data was consumed from all three partitions, meaning that none of them are "idle" (because all provide data), and thus the watermark remains 'stuck' as it was before.
But now that I’ve configured an idle timeout, and the query is still running, this time when I add a new row, it should advance the watermark.
INSERT INTO orders (order_id, customer_id, order_date, total_amount)
VALUES ('1043', 'CUST-5678', TIMESTAMP '2025-05-09 15:51:00', 42.00);✨ And now we get results from the join!
+----+----------+-------------------------+--------------+----------+
| op | order_id | order_date | total_amount | name |
+----+----------+-------------------------+--------------+----------+
| +I | 1042 | 2025-05-09 15:50:00.000 | 42.00 | <NULL> |
| +I | 1001 | 2025-05-09 14:30:00.000 | 199.99 | <NULL> |
| +I | 1002 | 2025-05-09 15:45:00.000 | 349.50 | <NULL> |Over in the Flink UI we can see that the watermark has advanced
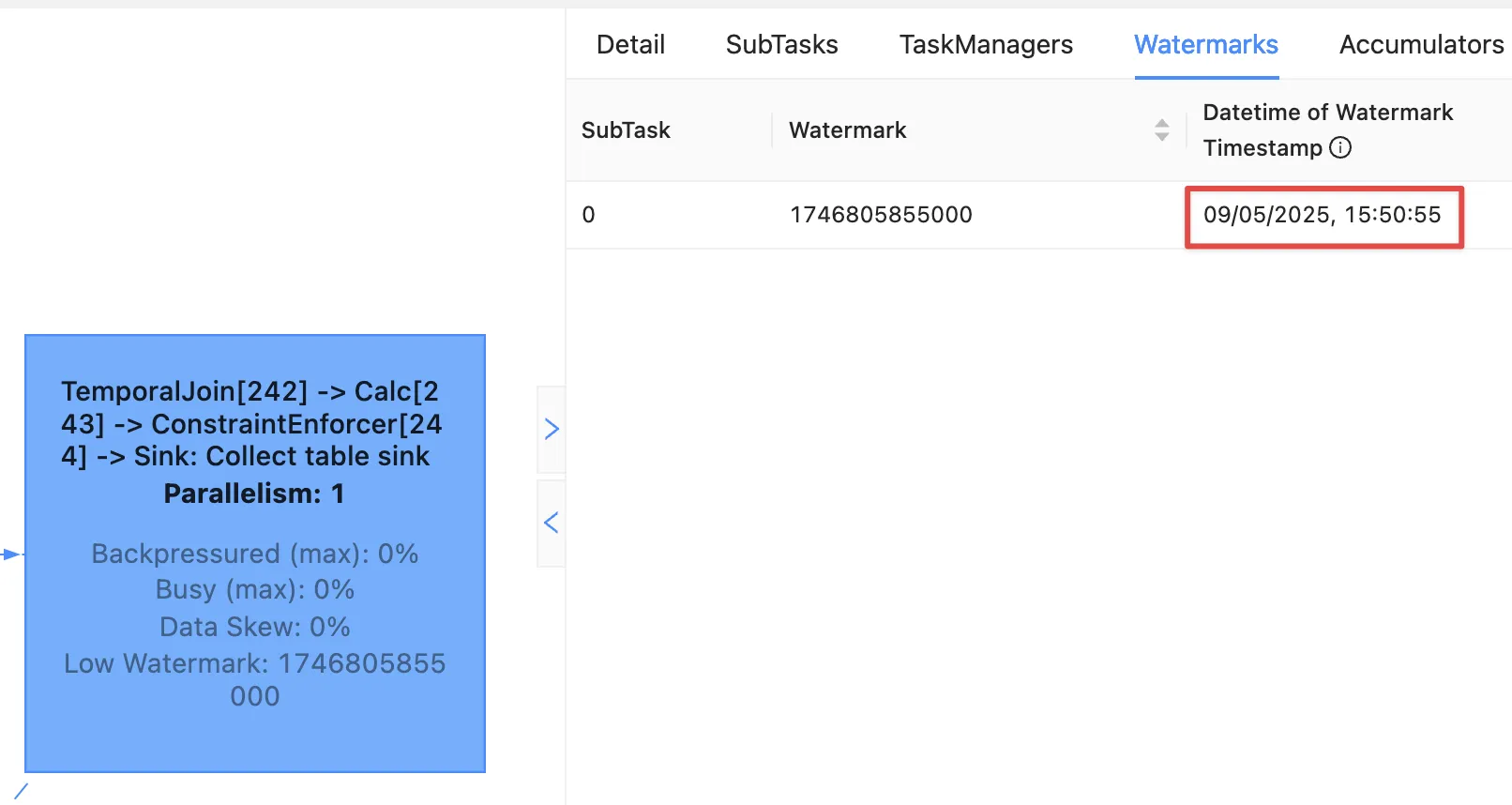
The watermark is now 09/05/2025, 15:50:55, which is generated from order_date minus 5 seconds of the order 1043 that we inserted.
Where is order 1003?
That has an order_date of 2025-05-09 16:15:00.000 which is after the watermark and so won’t be emitted.
|
🙋 So I need to insert a new row each time to advance the watermark?
Yes. Idle timeouts, whether defined on the table, or as a global setting for the session (using No new record, no watermark generation. |
Back to the join 🔗
To recap, we’ve run a temporal join:
SELECT o.order_id,
o.order_date,
o.total_amount,
c.name
FROM orders AS o
LEFT OUTER JOIN
customers
FOR SYSTEM_TIME AS OF o.order_date
AS c
ON o.customer_id = c.customer_id;and got some data:
+----+----------+-------------------------+--------------+----------+
| op | order_id | order_date | total_amount | name |
+----+----------+-------------------------+--------------+----------+
| +I | 1042 | 2025-05-09 15:50:00.000 | 42.00 | <NULL> |
| +I | 1001 | 2025-05-09 14:30:00.000 | 199.99 | <NULL> |
| +I | 1002 | 2025-05-09 15:45:00.000 | 349.50 | <NULL> |Now the question is: why am I getting a <NULL> in my join output?
Let’s look at order 1001 and just consider it on its own for now.
Here are the respective records that in a regular ole' batch query would be a simple match.
On the left of the join, we have the orders row:
Flink SQL> SELECT order_id, customer_id, order_date FROM orders WHERE order_id='1001';
+----+--------------------------------+--------------------------------+-------------------------+
| op | order_id | customer_id | order_date |
+----+--------------------------------+--------------------------------+-------------------------+
| +I | 1001 | CUST-5678 | 2025-05-09 14:30:00.000 |On the right is customers, which holds the following for CUST-5678:
Flink SQL> SELECT customer_id, name FROM customers WHERE customer_id = 'CUST-5678';
+----+--------------------------------+--------------------------------+
| op | customer_id | name |
+----+--------------------------------+--------------------------------+
| +I | CUST-5678 | Bucky Barnes |Given that we’ve got a valid record for CUST-5678, why does the JOIN above emit a <NULL>?
Looking at our join logic:
FROM orders AS o
LEFT OUTER JOIN (1)
customers
FOR SYSTEM_TIME (2)
AS OF o.order_date (3)
AS c
ON o.customer_id = c.customer_id; (4)| 1 | Do a left join from orders to customers |
| 2 | Based on the state of customers as it was at… |
| 3 | …the value of order_date |
| 4 | Using the FK/PK relationship |
Perhaps we now see the problem.
On 9th May, there was no entry on customers for CUST_5678.
The first entry for this customer is 15th May:
Flink SQL> SELECT record_time, customer_id, name FROM customers WHERE customer_id = 'CUST-5678';
+----+-------------------------+--------------------------------+--------------------------------+
| op | record_time | customer_id | name |
+----+-------------------------+--------------------------------+--------------------------------+
| +I | 2025-05-15 09:13:46.615 | CUST-5678 | Bucky Barnes |So since there was in effect no entry for the join to match to, we get a <NULL>, just as we would in an outer join if there was no match on customer_id in a regular batch query.
Let’s prove this out, by creating an order for this customer with an order_date that does fall within the times for which we have an entry.
Since we’ll be added an orders record with a newer timestamp than any of the others we’ll need to advance the watermark too, so I’m going to add a second order to do this:
INSERT INTO orders (order_id, customer_id, order_date, total_amount)
VALUES ('1044', 'CUST-5678', TIMESTAMP '2025-05-15 09:14:00', 42.00),
('dummy', 'watermark yo', TIMESTAMP '2025-05-15 09:14:05', 0);The trouble is I was trying to be too clever, and Flink is more cleverer than me.
Here’s the orders table now:
+----+-----------------+-----------+-------------------------+-------------------------+
| op | topic_partition | order_id | order_date | expected_watermark |
+----+-----------------+-----------+-------------------------+-------------------------+
| +I | 0 | 1002 | 2025-05-09 15:45:00.000 | 2025-05-09 15:44:55.000 |
| +I | 0 | 1042 | 2025-05-09 15:50:00.000 | 2025-05-09 15:49:55.000 |
| +I | 0 | 1043 | 2025-05-09 15:51:00.000 | 2025-05-09 15:50:55.000 | (1)
| +I | 1 | 1001 | 2025-05-09 14:30:00.000 | 2025-05-09 14:29:55.000 |
| +I | 1 | 1044 | 2025-05-15 09:14:00.000 | 2025-05-15 09:13:55.000 | (2)
| +I | 2 | 1003 | 2025-05-09 16:15:00.000 | 2025-05-09 16:14:55.000 |
| +I | 2 | dummy | 2025-05-15 09:14:05.000 | 2025-05-15 09:14:00.000 | (3)| 1 | Partition 0 will be idle, since nothing’s been read from it for more than five seconds |
| 2 | Here’s our record that we’d like to see in the join output.
It’s setting the watermark for partition 1 to 2025-05-15 09:13:55.000 |
| 3 | This was the clever idea that wasn’t. It’s advanced the watermark but only for partition 2. |
Flink takes the earliest of the three watermarks across the partitions. Partition 0 is idle; and of partitions 1 and 2 partition 1 has the earlier watermark. Thus the overall watermark doesn’t advance 🤦
What we need to do instead is insert our dummy record long enough after the real record, so that its partition has fallen idle. Long enough, say, since I’ve been typing this :)
INSERT INTO orders (order_id, customer_id, order_date, total_amount)
VALUES ('me dummy', 'watermark yo, again', TIMESTAMP '2025-05-15 09:14:05', 0);And there it is!
+----+----------+-------------------------+--------------+--------------+
| op | order_id | order_date | total_amount | name |
+----+----------+-------------------------+--------------+--------------+
| +I | 1042 | 2025-05-09 15:50:00.000 | 42.00 | <NULL> |
| +I | 1001 | 2025-05-09 14:30:00.000 | 199.99 | <NULL> |
| +I | 1002 | 2025-05-09 15:45:00.000 | 349.50 | <NULL> |
| +I | 1043 | 2025-05-09 15:51:00.000 | 42.00 | <NULL> |
| +I | 1003 | 2025-05-09 16:15:00.000 | 75.25 | <NULL> |
| +I | 1044 | 2025-05-15 09:14:00.000 | 42.00 | Bucky Barnes | (1)| 1 | Yay🎉 The order we were expecting—and with a successful join to customers! |
So the temporal join worked. What now? 🔗
Let’s see what happens if we add an order with a time after the customers watermark.
As a reminder, here is the customers data:
Flink SQL> SELECT record_time, topic_partition, customer_id, name FROM customers_tmp;
+----+-------------------------+-----------------+-------------+--------------------------------+
| op | record_time | topic_partition | customer_id | name |
+----+-------------------------+-----------------+-------------+--------------------------------+
| +I | 2025-05-15 09:13:46.615 | 2 | CUST-5678 | Bucky Barnes | (1)
| +I | 2025-05-15 09:13:46.614 | 1 | CUST-3456 | Yelena Belova |
| +I | 2025-05-15 09:13:46.615 | 1 | CUST-9012 | Valentina Allegra de Fontaine | (1)| 1 | 2025-05-15 09:13:46.615 is the latest record time across the two (of three) populated partitions, so Flink will use the lowest of these (but they’re the same), making this time the watermark for customers |
Here’s the INSERT, using a time of 2025-05-16 10:43:00.000:
INSERT INTO orders (order_id, customer_id, order_date, total_amount)
VALUES ('1045', 'CUST-9012', TIMESTAMP '2025-05-16 10:43:00.000', 23.00);(plus a second INSERT more than five seconds later for a dummy record to advance the watermark)
Removing the earlier records, plus the dummy ones, we’ve now got these results:
+----+-----------+-------------------------+--------------+--------------------------------+
| op | order_id | order_date | total_amount | name |
+----+-----------+-------------------------+--------------+--------------------------------+
[…]
| +I | 1044 | 2025-05-15 09:14:00.000 | 42.00 | Bucky Barnes |
| +I | 1045 | 2025-05-16 10:43:00.000 | 23.00 | Valentina Allegra de Fontaine | (1)| 1 | Different customer name is the match for CUST-9012 |
This is good, but the bit that doesn’t make sense to me though is this:
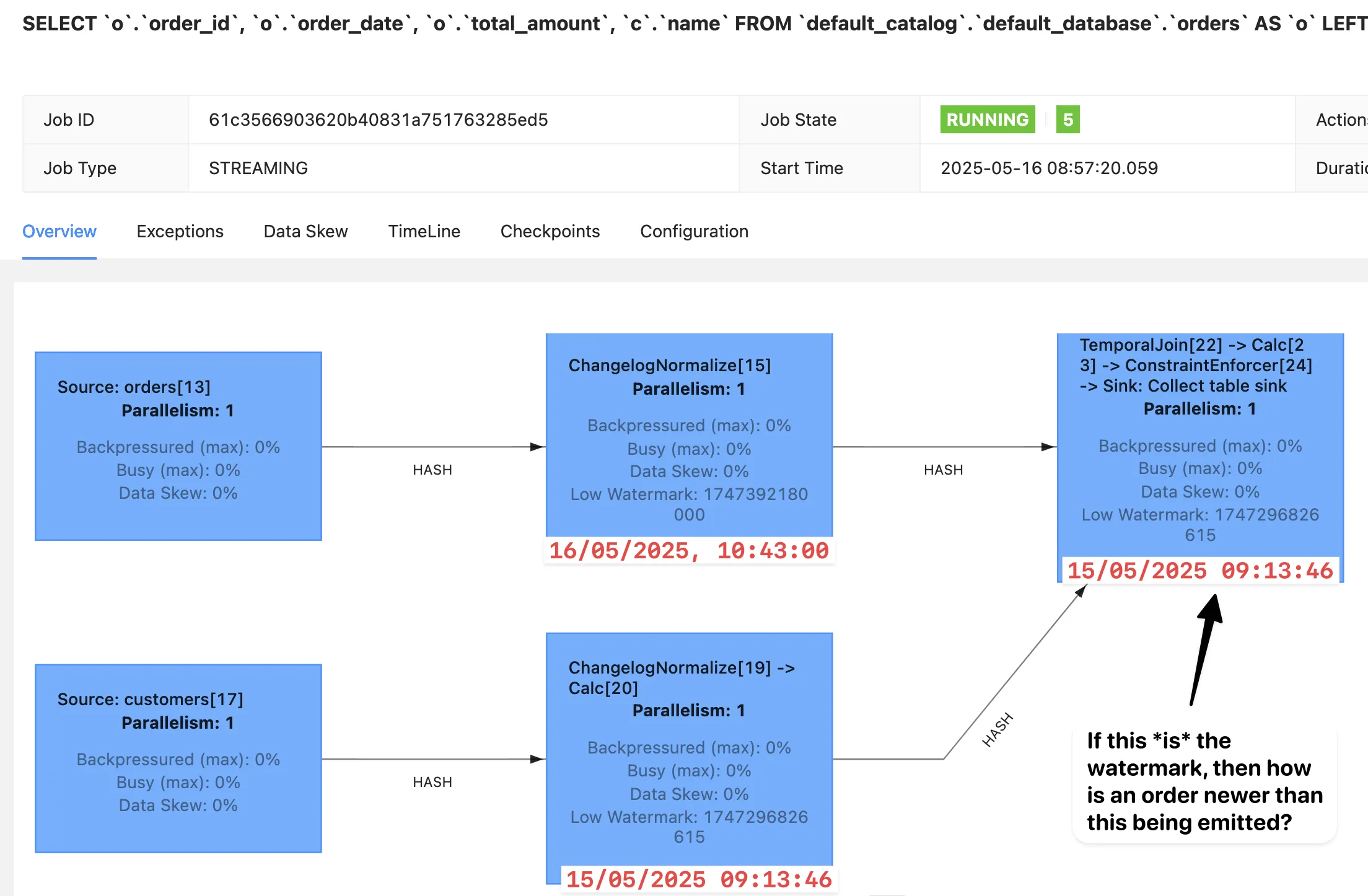
If the watermark on the join operator is 2025-05-15 09:13:46, how is an order record with timestamp 2025-05-16 10:43:00 able to be emitted?
My guess here is that the Flink UI is misleading.
My guess is that even though the customers watermark is earlier than the orders one and thus would normally be used by the join operator, it’s actually marking the customers source as idle (since we did configure 'scan.watermark.idle-timeout'='5 sec' on it), and thus uses the orders watermark.
The Flink UI renders data from Flink’s metrics, amongst which we find that there are MOAR watermark metrics than the Flink UI is necessarily showing us.
You can access watermarks directly using the REST API, or by adding them through the Metrics tab in the Flink UI once you’ve selected an operator.
When we do this, things start to make more sense; the orders watermark is indeed the one we see as the currentOutputWatermark of the join operator:
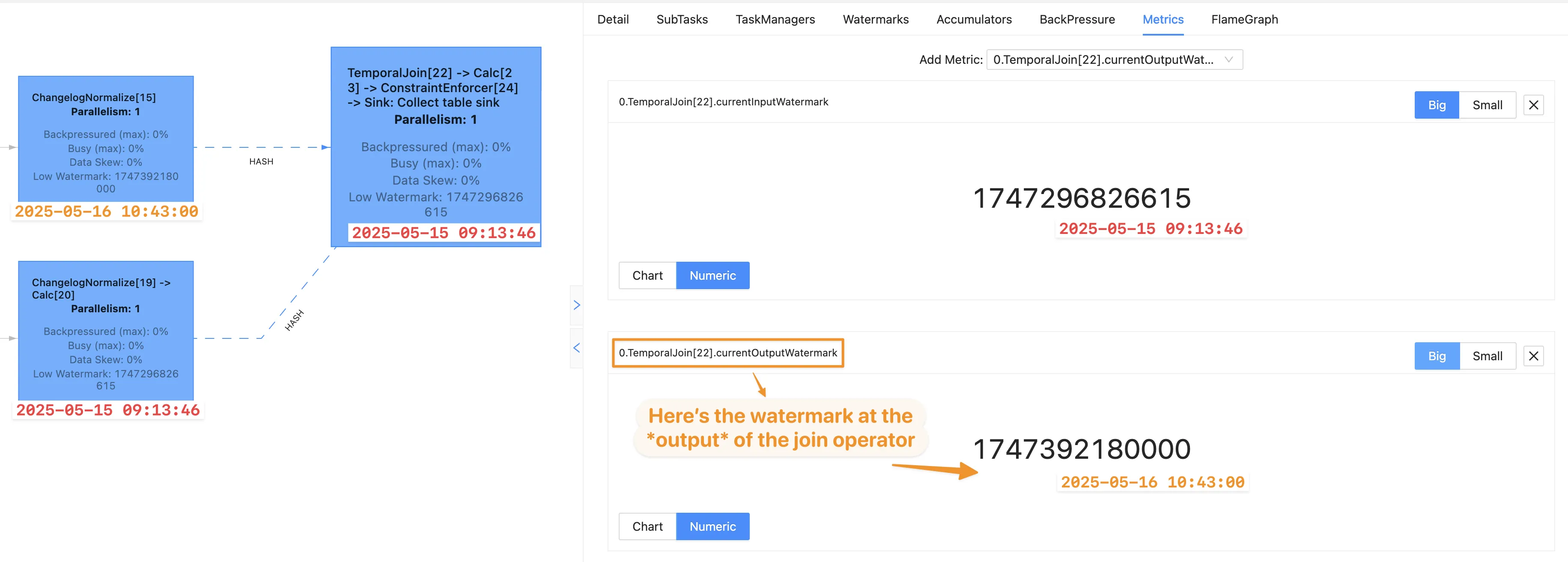
Am I simply fitting what I can find in the UI to match what I’m observing in the query output? Heck yeah! Can you tell me where I’m wrong? I’d love to be corrected :)
Avoiding NULLs in Temporal joins to reference data 🔗
Let’s claw our way back up into daylight, and look at fixing the problem we saw above: NULLs in the join results caused by the fact (order) having an event time newer than the reference (customer).
In the very verbose example above, I used the event time attribute of order_date when joining orders to customers, using this to lookup matches on customers as the state of the table was at that time.
The time on customers I defined as record_time, which came from the Kafka record timestamp.
Kafka record timestamps can be set by the producer to be an event time, but they are often just the time at which the broker wrote the message to disk.
If that’s the case, then the timestamp for the reference data is going to bear no relation to the fact data for which its related.
It could have been written a year or a second ago.
We saw that where order_date > record_time for a matching record, a NULL was returned, because in effect this record didn’t exist at the time of the order.
What if we want to tell Flink just join to the record on customers, I don’t care when it was created?
In other words, take the state of customers as you find it, and join if you can.
We could use a regular join like we saw originally, but this has the issue of growing state and re-emitting orders if new data is received for the customer.
Instead, we’ll still use a temporal join, but fudge things a little.
CREATE TABLE customers (
customer_id STRING,
name STRING,
epoch_ts AS TO_TIMESTAMP(FROM_UNIXTIME(0)), (1)
WATERMARK FOR epoch_ts AS epoch_ts, (2)
PRIMARY KEY (customer_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'customers',
'properties.bootstrap.servers' = 'broker:9092',
'key.format' = 'json',
'value.format' = 'json',
'scan.watermark.idle-timeout' = '5 sec' (3)
);| 1 | Create a timestamp column hardcoded with the value of the UNIX epoch (Jan 01 1970 00:00:00 GMT) |
| 2 | Set this as the event time attribute for the table, and use it as the watermark generation strategy |
| 3 | Set a watermark idle timeout, as before |
The orders configuration stays exactly as before:
CREATE TABLE orders (
order_id STRING,
customer_id STRING,
order_date TIMESTAMP(3),
total_amount DECIMAL(10, 2),
WATERMARK FOR `order_date` AS `order_date` - INTERVAL '5' SECONDS, (1)
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'orders',
'properties.bootstrap.servers' = 'broker:9092',
'key.format' = 'json',
'value.format' = 'json',
'scan.watermark.idle-timeout'='5 sec' (2)
);| 1 | Set order_date as the event time attribute, and define a watermark generation strategy |
| 2 | Define idle timeout for the watermark |
Now when we run our join, any matching records for the join (orders.customer_id = customers.customer_id) will never fail on the state of customers at the time of order_date not having the row—not unless orders come in before 1970, anyway :)
Testing this out using the same process as above, we get a nice match on the orders, as we’d hoped.
SELECT o.order_id,
o.order_date,
o.total_amount,
c.name,
c.epoch_ts
FROM orders AS o
LEFT OUTER JOIN
customers
FOR SYSTEM_TIME AS OF o.order_date
AS c
ON o.customer_id = c.customer_id;
+----+----------+-------------------------+--------------+--------------------------------+-------------------------+
| op | order_id | order_date | total_amount | name | epoch_ts |
+----+----------+-------------------------+--------------+--------------------------------+-------------------------+
| +I | 1042 | 2025-05-09 15:50:00.000 | 42.00 | Bucky Barnes | 1970-01-01 00:00:00.000 |
| +I | 1001 | 2025-05-09 14:30:00.000 | 199.99 | Bucky Barnes | 1970-01-01 00:00:00.000 |
| +I | 1003 | 2025-05-09 16:15:00.000 | 75.25 | Bucky Barnes | 1970-01-01 00:00:00.000 |
| +I | 1002 | 2025-05-09 15:45:00.000 | 349.50 | Valentina Allegra de Fontaine | 1970-01-01 00:00:00.000 |Implementing Slowly Changing Dimension (SCD) type 2 with Temporal Joins 🔗
When we joined to the customers table using the epoch as event time attribute, it meant that Flink would end up using the latest value of the record for a given customer.
This is a SCD type 1 approach.
SCD type 2 is where we join the fact to the dimension based on the state of the dimension at the time of the fact.
Consider a customer who moves house, and we want to report on sales by customer location. If we use SCD type 1 we’ll find out sales based on where customers live now. Contrast this to SCD type 2; that tells us sales based on where the customer lived at the time of the sale.
As with so much of SQL logic, there is not a "right" or "wrong", only a business requirement for particular logic.
To implement SCD type 2 you’ll need a field on the dimension table that holds the date from which the record is valid.
Let’s redefine our customers table thus:
CREATE TABLE customers (
customer_id STRING,
name STRING,
city STRING,
valid_from TIMESTAMP(3), (1)
WATERMARK FOR valid_from AS valid_from, (2)
PRIMARY KEY (customer_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'customers',
'properties.bootstrap.servers' = 'broker:9092',
'key.format' = 'json',
'value.format' = 'json',
'scan.watermark.idle-timeout'='5 sec'
);| 1 | This is the field for the SCD type 2 logic |
| 2 | We need to set valid_from as the event time attribute for the table, and define a watermark generation strategy for it. |
and add some data:
INSERT INTO customers (customer_id, name, city, valid_from)
VALUES
('CUST-3456', 'Yelena Belova', 'New York', TIMESTAMP '2025-01-01 00:00:00'),
('CUST-5678', 'Bucky Barnes', 'Brooklyn', TIMESTAMP '2025-01-02 00:00:00'), (1)
('CUST-9012', 'Valentina Allegra de Fontaine', 'Moscow', TIMESTAMP '2025-01-01 00:00:00'),
('CUST-5678', 'Bucky Barnes', 'Bucharest', TIMESTAMP '2025-05-10 00:00:00'); (2)| 1 | Bucky starts off in Brooklyn |
| 2 | Bucky is now in Bucharest |
Which gives us this:
Flink SQL> SELECT * FROM customers;
+----+--------------+--------------------------------+------------+-------------------------+
| op | customer_id | name | city | valid_from |
+----+--------------+--------------------------------+------------+-------------------------+
| +I | CUST-5678 | Bucky Barnes | Brooklyn | 2025-01-02 00:00:00.000 | (1)
| -U | CUST-5678 | Bucky Barnes | Brooklyn | 2025-01-02 00:00:00.000 | (2)
| +U | CUST-5678 | Bucky Barnes | Bucharest | 2025-05-10 00:00:00.000 | (3)
| +I | CUST-3456 | Yelena Belova | New York | 2025-01-01 00:00:00.000 |
| +I | CUST-9012 | Valentina Allegra de Fontaine | Moscow | 2025-01-01 00:00:00.000 || 1 | Original record for CUST-5678 |
| 2 | New record comes in so existing one is negated (-U) |
| 3 | New record for CUST-5678 is inserted |
Now we’ll set up the orders, using the same table definition as above.
CREATE TABLE orders (
order_id STRING,
customer_id STRING,
order_date TIMESTAMP(3),
total_amount DECIMAL(10, 2),
WATERMARK FOR `order_date` AS `order_date` - INTERVAL '5' SECONDS,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'orders',
'properties.bootstrap.servers' = 'broker:9092',
'key.format' = 'json',
'value.format' = 'json',
'scan.watermark.idle-timeout'='5 sec'
);The orders data is slightly different, to include a second order for CUST-5678 at a later date:
INSERT INTO orders (order_id, customer_id, order_date, total_amount)
VALUES
('1001', 'CUST-5678', TIMESTAMP '2025-05-09 14:30:00', 199.99),
('1002', 'CUST-3456', TIMESTAMP '2025-05-09 15:45:00', 349.50),
('1003', 'CUST-5678', TIMESTAMP '2025-05-09 16:15:00', 75.25),
('1004', 'CUST-5678', TIMESTAMP '2025-05-14 11:02:00', 42.25);This looks like this:
Flink SQL> SELECT * FROM orders;
+----+-----------+--------------+-------------------------+--------------+
| op | order_id | customer_id | order_date | total_amount |
+----+-----------+--------------+-------------------------+--------------+
| +I | 1002 | CUST-3456 | 2025-05-09 15:45:00.000 | 349.50 |
| +I | 1004 | CUST-5678 | 2025-05-14 11:02:00.000 | 42.25 | (2)
| +I | 1001 | CUST-5678 | 2025-05-09 14:30:00.000 | 199.99 | (1)
| +I | 1003 | CUST-5678 | 2025-05-09 16:15:00.000 | 75.25 | (1)| 1 | Expected city value in the join is Brooklyn |
| 2 | Expected city value in the join is Bucharest |
Let’s run the join:
SELECT o.order_id,
o.order_date,
o.total_amount,
c.name,
c.city,
c.valid_from
FROM orders AS o
LEFT OUTER JOIN
customers
FOR SYSTEM_TIME AS OF o.order_date
AS c
ON o.customer_id = c.customer_id;After adding a new row to orders to advance the watermark, we get succesful join results!
+----+----------+---------------------+--------------+---------------+------------+---------------------+
| op | order_id | order_date | total_amount | name | city | valid_from |
+----+----------+---------------------+--------------+---------------+------------+---------------------+
| +I | 1004 | 2025-05-14 11:02:00 | 42.25 | Bucky Barnes | Bucharest | 2025-05-10 00:00:00 | (2)
| +I | 1001 | 2025-05-09 14:30:00 | 199.99 | Bucky Barnes | Brooklyn | 2025-01-02 00:00:00 | (1)
| +I | 1003 | 2025-05-09 16:15:00 | 75.25 | Bucky Barnes | Brooklyn | 2025-01-02 00:00:00 | (1)
| +I | 1002 | 2025-05-09 15:45:00 | 349.50 | Yelena Belova | Moscow | 2025-01-01 00:00:00 || 1 | Bucky was in Brooklyn for the two orders (1001, 1003) placed on 2025-05-09 |
| 2 | Bucky then moved to Bucharest on 2025-05-10, meaning that the order 1004 on 2025-05-14 correctly shows his city at the time of the order. |
Temporal joins? tl;dr! 🔗
Let’s wrap this section up before we get back to the original subject at hand: changelogs.
For a temporal join to work you need to:
-
Understand watermarks!
Define idle partition/source timeouts as needed.
Understand that records won’t be emitted if the watermark hasn’t advanced past the record timestamp.
-
Have an event time attribute on both tables.
Remember that the time attribute defines the logic of the join; don’t just stick a column on assuming it can be anything. The example above of
record_timevsepoch_tsdemonstrates the impact that it can have.-
On the left of the join, the time attribute is used to lookup the state of the right-hand table as of that time
-
On the right of the join, the time attribute defines the time on the table to consider for this state
-
-
Use the
JOIN…FOR SYSTEM_TIME AS OFsyntax to declare it as a temporal join:FROM orders (1) AS o (2) LEFT OUTER JOIN (3) customers (4) FOR SYSTEM_TIME AS OF (5) o.order_date (6) AS c (7) ON o.customer_id = c.customer_id (8)1 Left-hand table 2 Optional alias for left-hand table 3 Type of join 4 Right-hand table 5 Join to the state of the right-hand table as of a given time 6 Event time attribute of left-hand table to use in the temporal join 7 Optional alias for right-hand table 8 Join predicate condition (typically foreign key/primary key relationship) You can read
FOR SYSTEM_TIMEas meaning "for the state of the right-hand table as defined by its event time attribute column"
Joins and Changelogs 🔗
I started off writing about changelogs, and then got somewhat waylaid into regular and temporal joins. Let’s see how these two different types of join reflect themselves in a changelog.
First though, a note about the Kafka connector. There are two Kafka connectors in Flink:
-
Kafka (
'connector'='kafka')-
The Kafka connector does not support primary keys and is for reading and writing append-only data. When reading data from a table using the Kafka connector you’ll only get
+Ichangelog operations.
-
-
Upsert Kafka (
'connector'='upsert-kafka')-
The Kafka Upsert connector supports primary keys and interprets messages on a Kafka topic for the same key as updates to that key. As a result you’ll see an update changelog from this connector (
+I,-D,-U,+U).The open source
upsert-kafkaconnector produces an upsert stream, and it only contains events of types+Uand-D. The reason why are you seeing the full set of types when you doSELECT * FROM customers_upsertis that changelog normalization has been applied to the upsert stream, converting it to a retract stream. Currently, Flink SQL always applies changelog normalization to upsert sources. This will change in Flink 2.1, thanks to FLIP-510.—David Anderson
-
Both connectors can read from a Kafka topic. The difference between them is primarily the semantic interpretation of the records.
Here’s an example of kafka [append] vs upsert-kafka [upsert], reading from the same Kafka topic.
On the topic there are two orders, one of which—1001— has an update made to it.
First off, the state that Flink builds (viewed using the table SQL client output mode).
The upsert-kafka connector pushes the update through into the state:
Flink SQL> SELECT * FROM orders_upsert;
SQL Query Result (Table)
order_id customer_id order_date total_amount
1004 CUST-5678 2025-05-14 11:02:00.000 42.25
1001 CUST-5678 2025-05-09 14:30:00.000 49.99 (1)| 1 | The order has been updated to hold the latest total_amount value |
Whilst the append connector just adds the update as another record:
Flink SQL> SELECT * FROM orders_append;
SQL Query Result (Table)
order_id customer_id order_date total_amount
1001 CUST-5678 2025-05-09 14:30:00.000 199.99 (1)
1004 CUST-5678 2025-05-14 11:02:00.000 42.25
1001 CUST-5678 2025-05-09 14:30:00.000 49.99 (2)| 1 | The order first has the total_amount value of 199.99 |
| 2 | The same order has a second entry when the value is 49.99 |
Now the changelog for each:
Flink SQL> SELECT * FROM orders_upsert;
+----+-----------+--------------+-------------------------+--------------+
| op | order_id | customer_id | order_date | total_amount |
+----+-----------+--------------+-------------------------+--------------+
| +I | 1004 | CUST-5678 | 2025-05-14 11:02:00.000 | 42.25 |
| +I | 1001 | CUST-5678 | 2025-05-09 14:30:00.000 | 199.99 | (1)
| -U | 1001 | CUST-5678 | 2025-05-09 14:30:00.000 | 199.99 | (2)
| +U | 1001 | CUST-5678 | 2025-05-09 14:30:00.000 | 49.99 | (2)| 1 | First instance of the order |
| 2 | Order is updated |
Compare this to the append changelog from the kafka connector:
Flink SQL> SELECT * FROM orders_append;
+----+-----------+--------------+-------------------------+--------------+
| op | order_id | customer_id | order_date | total_amount |
+----+-----------+--------------+-------------------------+--------------+
| +I | 1001 | CUST-5678 | 2025-05-09 14:30:00.000 | 199.99 |
| +I | 1004 | CUST-5678 | 2025-05-14 11:02:00.000 | 42.25 |
| +I | 1001 | CUST-5678 | 2025-05-09 14:30:00.000 | 49.99 |Let’s look at the customers data.
I’ve stripped it down to just one record, which has an update on city and valid_from:
Flink SQL> SELECT * FROM customers_upsert;
SQL Query Result (Table)
customer_id name city valid_from
CUST-5678 Bucky Barnes Bucharest 2025-05-10 00:00:00.000Flink SQL> SELECT * FROM customers_append;
SQL Query Result (Table)
customer_id name city valid_from
CUST-5678 Bucky Barnes Brooklyn 2025-01-02 00:00:00.000
CUST-5678 Bucky Barnes Bucharest 2025-05-10 00:00:00.000Here’s the changelog for the two versions of the table too, following the same patterns as above—only +I for append, vs +I, -U, +U for upsert:
Flink SQL> SELECT * FROM customers_upsert;
+----+--------------+---------------+------------+-------------------------+
| op | customer_id | name | city | valid_from |
+----+--------------+---------------+------------+-------------------------+
| +I | CUST-5678 | Bucky Barnes | Brooklyn | 2025-01-02 00:00:00.000 |
| -U | CUST-5678 | Bucky Barnes | Brooklyn | 2025-01-02 00:00:00.000 |
| +U | CUST-5678 | Bucky Barnes | Bucharest | 2025-05-10 00:00:00.000 |Flink SQL> SELECT * FROM customers_append;
+----+--------------+---------------+------------+-------------------------+
| op | customer_id | name | city | valid_from |
+----+--------------+---------------+------------+-------------------------+
| +I | CUST-5678 | Bucky Barnes | Brooklyn | 2025-01-02 00:00:00.000 |
| +I | CUST-5678 | Bucky Barnes | Bucharest | 2025-05-10 00:00:00.000 |Now, what happens when we join these differenct versions of the tables? Bear in mind, there are two different joins we’re looking at—regular, and temporal.
| In the following sections, I’m not showing the impact of watermarks, and am adding records when I need to advance the watermark in order to have the relevant rows output. |
Temporal join: append to append 🔗
Nope, not happening!
Flink SQL> SELECT o.order_id,
> o.total_amount,
> c.name,
> c.city
> FROM orders_append AS o
> LEFT OUTER JOIN
> customers_append
> FOR SYSTEM_TIME AS OF o.order_date
> AS c
> ON o.customer_id = c.customer_id;
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.ValidationException: Temporal Table Join requires primary key in versioned table, but no primary key can be found. The physical plan is:
FlinkLogicalJoin(condition=[AND(=($1, $4), __INITIAL_TEMPORAL_JOIN_CONDITION($2, $7, __TEMPORAL_JOIN_LEFT_KEY($1), __TEMPORAL_JOIN_RIGHT_KEY($4)))], joinType=[left])
FlinkLogicalTableSourceScan(table=[[default_catalog, default_database, orders_append, watermark=[-(order_date, 5000:INTERVAL SECOND)], idletimeout=[5000], watermarkEmitStrategy=[on-periodic]]], fields=[order_id, customer_id, order_date, total_amount])
FlinkLogicalSnapshot(period=[$cor0.order_date])
FlinkLogicalTableSourceScan(table=[[default_catalog, default_database, customers_append, watermark=[valid_from], idletimeout=[5000], watermarkEmitStrategy=[on-periodic]]], fields=[customer_id, name, city, valid_from])In this error:
Temporal Table Join requires primary key in versioned table, but no primary key can be foundthe versioned table is the right-hand table, i.e. customers, and because it’s an append table it doesn’t have a PK.
So let’s try joining to the upsert version:
Temporal join: append to upsert 🔗
Flink SQL> SELECT o.order_id,
> o.total_amount,
> c.name,
> c.city
> FROM orders_append AS o
> LEFT OUTER JOIN
> customers_upsert
> FOR SYSTEM_TIME AS OF o.order_date
> AS c
> ON o.customer_id = c.customer_id;
+----+-----------+--------------+---------------+------------+
| op | order_id | total_amount | name | city |
+----+-----------+--------------+---------------+------------+
| +I | 1001 | 199.99 | Bucky Barnes | Brooklyn |
| +I | 1001 | 49.99 | Bucky Barnes | Brooklyn |
| +I | 1004 | 42.25 | Bucky Barnes | Bucharest |From this we can see that the output is also an append log.
Temporal join: upsert to upsert 🔗
This is what we were doing in the article above, and gives us this output where the changed record with a new total_amount for order 1001 is re-emitted (-U → +I).
Note also that the city is correct based on the time of the order.
Flink SQL> SELECT o.order_id,
> o.total_amount,
> c.name,
> c.city
> FROM orders_upsert AS o
> LEFT OUTER JOIN
> customers_upsert
> FOR SYSTEM_TIME AS OF o.order_date
> AS c
> ON o.customer_id = c.customer_id;
+----+-----------+--------------+---------------+------------+
| op | order_id | total_amount | name | city |
+----+-----------+--------------+---------------+------------+
| +I | 1004 | 42.25 | Bucky Barnes | Bucharest |
| +I | 1001 | 199.99 | Bucky Barnes | Brooklyn |
| -U | 1001 | 199.99 | Bucky Barnes | Brooklyn |
| +U | 1001 | 49.99 | Bucky Barnes | Brooklyn |Temporal join: upsert to append 🔗
We know we can’t do this because it’s a version of what we tried above.
Flink SQL> SELECT o.order_id,
> o.total_amount,
> c.name,
> c.city
> FROM orders_upsert AS o
> LEFT OUTER JOIN
> customers_append
> FOR SYSTEM_TIME AS OF o.order_date
> AS c
> ON o.customer_id = c.customer_id;
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.ValidationException: Temporal Table Join requires primary key in versioned table, but no primary key can be found.Regular join: append to append 🔗
Flink SQL> SELECT o.order_id,
> o.total_amount,
> c.name,
> c.city
> FROM orders_append AS o
> LEFT OUTER JOIN
> customers_append
> AS c
> ON o.customer_id = c.customer_id;
+----+-----------+--------------+---------------+------------+
| op | order_id | total_amount | name | city |
+----+-----------+--------------+---------------+------------+
| +I | 1001 | 199.99 | <NULL> | <NULL> |
| +I | 1004 | 42.25 | <NULL> | <NULL> |
| -D | 1004 | 42.25 | <NULL> | <NULL> |
| -D | 1001 | 199.99 | <NULL> | <NULL> |
| +I | 1004 | 42.25 | Bucky Barnes | Brooklyn |
| +I | 1001 | 199.99 | Bucky Barnes | Brooklyn |
| +I | 1001 | 49.99 | Bucky Barnes | Brooklyn |
| +I | 1004 | 42.25 | Bucky Barnes | Bucharest |
| +I | 1001 | 49.99 | Bucky Barnes | Bucharest |
| +I | 1001 | 199.99 | Bucky Barnes | Bucharest |You’ll notice here the use of -D rather than -U.
The nett result is almost certainly what you would not want; a cartesian of every order update with every customer update:
SQL Query Result (Table)
order_id total_amount name city
1001 199.99 Bucky Barnes Brooklyn
1001 199.99 Bucky Barnes Bucharest
1001 49.99 Bucky Barnes Bucharest
1001 49.99 Bucky Barnes Brooklyn
1004 42.25 Bucky Barnes Brooklyn
1004 42.25 Bucky Barnes BucharestI’ve manually sorted the orders to make it easier to understand the results
Regular join: append to upsert 🔗
This one has an even more noisy changelog:
Flink SQL> SELECT o.order_id,
> o.total_amount,
> c.name,
> c.city
> FROM orders_append AS o
> LEFT OUTER JOIN
> customers_upsert
> AS c
> ON o.customer_id = c.customer_id;
+----+-----------+--------------+---------------+------------+
| op | order_id | total_amount | name | city |
+----+-----------+--------------+---------------+------------+
| +I | 1001 | 199.99 | <NULL> | <NULL> |
| +I | 1004 | 42.25 | <NULL> | <NULL> |
| +I | 1001 | 49.99 | <NULL> | <NULL> |
| -D | 1004 | 42.25 | <NULL> | <NULL> |
| -D | 1001 | 49.99 | <NULL> | <NULL> |
| -D | 1001 | 199.99 | <NULL> | <NULL> |
| +I | 1004 | 42.25 | Bucky Barnes | Brooklyn |
| +I | 1001 | 49.99 | Bucky Barnes | Brooklyn |
| +I | 1001 | 199.99 | Bucky Barnes | Brooklyn |
| -U | 1004 | 42.25 | Bucky Barnes | Brooklyn |
| -U | 1001 | 49.99 | Bucky Barnes | Brooklyn |
| -U | 1001 | 199.99 | Bucky Barnes | Brooklyn |
| +I | 1004 | 42.25 | <NULL> | <NULL> |
| +I | 1001 | 49.99 | <NULL> | <NULL> |
| +I | 1001 | 199.99 | <NULL> | <NULL> |
| -D | 1004 | 42.25 | <NULL> | <NULL> |
| -D | 1001 | 49.99 | <NULL> | <NULL> |
| -D | 1001 | 199.99 | <NULL> | <NULL> |
| +I | 1004 | 42.25 | Bucky Barnes | Bucharest |
| +I | 1001 | 49.99 | Bucky Barnes | Bucharest |
| +I | 1001 | 199.99 | Bucky Barnes | Bucharest |However the nett state is more useful than the dumb cartesian in the previous section. It shows each order entry but updated for the current customers value.
SQL Query Result (Table)
order_id total_amount name city
1004 42.25 Bucky Barnes Bucharest
1001 49.99 Bucky Barnes Bucharest
1001 199.99 Bucky Barnes BucharestRegular join: upsert to upsert 🔗
This one behaved a bit odd when I ran it; I saw a different changelog depending on whether I included a predicate on one order:
Flink SQL> SELECT o.order_id,
> o.total_amount,
> c.name,
> c.city
> FROM orders_upsert AS o
> LEFT OUTER JOIN
> customers_upsert
> AS c
> ON o.customer_id = c.customer_id;
+----+-----------+--------------+----------------+-------------+
| op | order_id | total_amount | name | city |
+----+-----------+--------------+----------------+-------------+
| +I | 1004 | 42.25 | <NULL> | <NULL> |
| -D | 1004 | 42.25 | <NULL> | <NULL> |
| +I | 1004 | 42.25 | Bucky Barnes | Brooklyn |
| +I | dummy | 0.00 | <NULL> | <NULL> |
| -U | 1004 | 42.25 | Bucky Barnes | Brooklyn |
| +I | 1004 | 42.25 | <NULL> | <NULL> |
| +I | 1001 | 199.99 | <NULL> | <NULL> |
| -D | 1004 | 42.25 | <NULL> | <NULL> |
| -D | 1001 | 199.99 | <NULL> | <NULL> |
| +I | 1004 | 42.25 | Bucky Barnes | Bucharest |
| +I | 1001 | 199.99 | Bucky Barnes | Bucharest |
| -D | 1001 | 199.99 | Bucky Barnes | Bucharest |
| +I | 1001 | 49.99 | Bucky Barnes | Bucharest |This gives the "correct" view of the data from each side of the join if you want to see the current value for both order and customer reflected in the state:
SQL Query Result (Table)
order_id total_amount name city
1004 42.25 Bucky Barnes Bucharest
1001 49.99 Bucky Barnes BucharestRegular join: upsert to append 🔗
You might be able guess this one now; it’s going to be the latest version of the order, with a new instance of it added for each customer change:
Flink SQL> SELECT o.order_id,
> o.total_amount,
> c.name,
> c.city
> FROM orders_upsert AS o
> LEFT OUTER JOIN
> customers_append
> AS c
> ON o.customer_id = c.customer_id;
+----+-----------+--------------+---------------+------------+
| op | order_id | total_amount | name | city |
+----+-----------+--------------+---------------+------------+
| +I | 1004 | 42.25 | Bucky Barnes | Bucharest |
| +I | 1004 | 42.25 | Bucky Barnes | Brooklyn |
| +I | dummy | 0.00 | <NULL> | <NULL> |
| +I | 1001 | 199.99 | Bucky Barnes | Bucharest |
| +I | 1001 | 199.99 | Bucky Barnes | Brooklyn |
| -D | 1001 | 199.99 | Bucky Barnes | Bucharest |
| -D | 1001 | 199.99 | Bucky Barnes | Brooklyn |
| +I | 1001 | 49.99 | Bucky Barnes | Bucharest |
| +I | 1001 | 49.99 | Bucky Barnes | Brooklyn | SQL Query Result (Table)
order_id total_amount name city
1004 42.25 Bucky Barnes Bucharest
1004 42.25 Bucky Barnes Brooklyn
dummy 0.00 <NULL> <NULL>
1001 49.99 Bucky Barnes Bucharest
1001 49.99 Bucky Barnes BrooklynJoins and Changelogs—Summary 🔗
Above I showed just what happens with different invocations of a LEFT OUTER JOIN.
Here’s what I observed for all the different permutations of join types and input changelog types:

| For a full set of test statements with which you can experiment yourself, see the GitHub repo. |
If you want an an append log from your join there are four options:
-
A regular append-append INNER or RIGHT OUTER JOIN
-
A temporal append-upsert INNER or LEFT OUTER JOIN
What if you need an append log, but want a different join type? (a.k.a. how do you convert an upsert log to an append log) 🔗
Per the above table, you only have a few permutations that will give you an append log.
Here we’re going to take two upsert tables to which we want to apply a LEFT OUTER JOIN.
Done as a regular join, or keeping both tables as upsert, will result in an upsert changelog:
Flink SQL> SELECT o.order_id, o.total_amount, c.name, c.city
FROM orders AS o
LEFT OUTER JOIN
customers AS c
ON o.customer_id = c.customer_id
WHERE order_id ='1001';
+----+-----------+--------------+---------------+------------+
| op | order_id | total_amount | name | city |
+----+-----------+--------------+---------------+------------+
| +I | 1001 | 199.99 | <NULL> | <NULL> |
| -D | 1001 | 199.99 | <NULL> | <NULL> |
| +I | 1001 | 199.99 | Bucky Barnes | Brooklyn |
| -U | 1001 | 199.99 | Bucky Barnes | Brooklyn |
| +I | 1001 | 199.99 | <NULL> | <NULL> |
| -D | 1001 | 199.99 | <NULL> | <NULL> |
| +I | 1001 | 199.99 | Bucky Barnes | Bucharest |We’ll change two things in this join:
-
Make it temporal (so that Flink doesn’t hold state for the left table and issue updates when the right-hand table changes)
-
Convert the left-hand table into an append changelog
To convert the left-hand table to an append log we’ll use a tumbling window function with a GROUP BY.
In effect, this introduces a buffer: instead of an upsert changelog for every single state change, the state is buffered within Flink.
Flink then outputs the state as it exists as defined by the window size.
Because it is only emitting it at this final point of the window (and because the watermark will have advanced past the end of the window), it knows that logically the data can’t change, and thus it’s an append log.
Flink SQL> SELECT order_id, customer_id, order_date, total_amount
FROM TUMBLE(
DATA => TABLE orders, (1)
TIMECOL => DESCRIPTOR(order_date), (1)
SIZE => INTERVAL '1' MINUTES) (1)
GROUP BY order_id,
customer_id,
order_date,
total_amount,
window_start, (2)
window_end; (2)
+----+-----------+--------------+-------------------------+--------------+
| op | order_id | customer_id | order_date | total_amount |
+----+-----------+--------------+-------------------------+--------------+
| +I | 1001 | CUST-5678 | 2025-05-09 14:30:00.000 | 199.99 |
| +I | 1002 | CUST-3456 | 2025-05-09 15:45:00.000 | 349.50 |
| +I | 1003 | CUST-5678 | 2025-05-09 16:15:00.000 | 75.25 |
| +I | 1004 | CUST-5678 | 2025-05-14 11:02:00.000 | 45.00 || 1 | I’ve included the parameter names here just to aid comprehension; it’s also valid to write it like this:
|
| 2 | The GROUP BY on the window start/end is what forces Flink to emit an append changelog once and only once the window is closed |
Now we’ll join this to the existing upsert table (customers):
Flink SQL> SELECT o.order_id, o.total_amount, c.name, c.city
FROM (SELECT order_id, customer_id, order_date, total_amount
FROM TUMBLE(
DATA => TABLE orders,
TIMECOL => DESCRIPTOR(order_date),
SIZE => INTERVAL '1' MINUTES)
GROUP BY order_id,
customer_id,
order_date,
total_amount,
window_start,
window_end) AS o
LEFT OUTER JOIN
customers
FOR SYSTEM_TIME AS OF o.order_date
AS c
ON o.customer_id = c.customer_id;
+----+-----------+--------------+----------------+------------+
| op | order_id | total_amount | name | city |
+----+-----------+--------------+----------------+------------+
| +I | 1001 | 199.99 | Bucky Barnes | Brooklyn | (1)
| +I | 1002 | 349.50 | Yelena Belova | New York |
| +I | 1003 | 75.25 | Bucky Barnes | Brooklyn |
| +I | 1004 | 45.00 | Bucky Barnes | Bucharest | (2)| 1 | Note the customer’s city is as of the time of order_date |
| 2 | This shows the latest state of the order 1004, it having gone through several updates on the source:
|