
There was a useful question on the Apache Flink Slack recently about joining data in Flink SQL:
How can I join two streams of data by id in Flink, to get a combined view of the latest data?
For example say I have input tables with schema
items_a
{"id": <INT>, "ts": <TIMESTAMP(3)>, "a": <STRING>}items_b
{"id": <INT>, "ts": <TIMESTAMP(3)>, "b": <STRING>}and would like to join on
idusing the latest record by timestamptsin each table, to get the output table
out
{"id": <INT>, "ts": <TIMESTAMP(3)>, "a": <STRING>, "b": <STRING>}where a new row in either input table produces a single output row
As I learn more about Flink SQL I thought it would be interesting to try and answer this.
Shortly before publishing this, my esteemed colleague Martijn Visser pointed me to this doc that details a more elegant way of writing the query—and which highlights several key reasons why my naïve approach that I show below of a simple JOIN might not be such a good idea. This is something for me to dig into (I do believe learning watermarks might be on the cards 🫣), so stay tuned 😁
|
Create the source tables 🔗
| You can try out this full article using this Docker Compose to run Flink and the Flink SQL client. |
Based on the details above (kudos to the OP for a well-structured and informative question), I created two Flink SQL tables:
CREATE TABLE items_a (
id INT,
ts TIMESTAMP(3),
a STRING
) WITH (
'connector' = 'filesystem',
'path' = '/data/items_a.csv',
'format' = 'csv'
);
CREATE TABLE items_b (
id INT,
ts TIMESTAMP(3),
b STRING
) WITH (
'connector' = 'filesystem',
'path' = '/data/items_b.csv',
'format' = 'csv'
);I’m using the Filesystem connector just because it’s quicker than setting up the necessary dependencies for something else—in practice the source of streaming data would often be Kafka.
Populate some source data 🔗
cat << EOF > data/items_a.csv
1,2025-03-06 10:00:00.000,item_a_1
2,2025-03-06 10:01:00.000,item_a_2
EOF
cat << EOF > data/items_b.csv
1,2025-03-06 10:00:00.000,item_b_1
2,2025-03-06 12:01:30.000,item_b_2
EOFQuery each table individually to check the data 🔗
SET 'sql-client.execution.result-mode' = 'tableau';
SET 'execution.runtime-mode' = 'batch';Flink SQL> SELECT * FROM items_a;
+----+-------------------------+----------+
| id | ts | a |
+----+-------------------------+----------+
| 1 | 2025-03-06 10:00:00.000 | item_a_1 |
| 2 | 2025-03-06 10:01:00.000 | item_a_2 |
+----+-------------------------+----------+
2 rows in set (0.32 seconds)
Flink SQL> SELECT * FROM items_b;
+----+-------------------------+----------+
| id | ts | b |
+----+-------------------------+----------+
| 1 | 2025-03-06 10:00:00.000 | item_b_1 |
| 2 | 2025-03-06 12:01:30.000 | item_b_2 |
+----+-------------------------+----------+
2 rows in set (0.32 seconds)Join the tables - batch 🔗
This does a join between the tables and returns all rows where the id and ts match.
A couple of notes:
-
It’s a
FULL OUTER JOIN, meaning that a row from either table will trigger the join. If I did aLEFTorRIGHTjoin then you’d only see rows where an entry existed on theitems_aoritems_btable respectively. -
Since we don’t know from which table we’re getting the common values (
idandts) we use aCOALESCEto return the first non-NULL value
SELECT COALESCE(a.id,b.id) AS id,
COALESCE(a.ts,b.ts) AS ts,
a.a AS a,
b.b AS b
FROM items_a a
FULL OUTER JOIN
items_b b
ON a.id=b.id
AND a.ts=b.ts;The output looks like this:
+----+-------------------------+----------+----------+ | id | ts | a | b | +----+-------------------------+----------+----------+ | 1 | 2025-03-06 10:00:00.000 | item_a_1 | item_b_1 | | 2 | 2025-03-06 12:01:30.000 | <NULL> | item_b_2 | | 2 | 2025-03-06 10:01:00.000 | item_a_2 | <NULL> | +----+-------------------------+----------+----------+ 3 rows in set (0.32 seconds)
There’s no match on id=2 because the timestamp differs on the two tables
|
Join the tables - changelog 🔗
SET 'execution.runtime-mode' = 'streaming';+----+-------------+-------------------------+-----------+-----------+ | op | id | ts | a | b | +----+-------------+-------------------------+-----------+-----------+ | +I | 1 | 2025-03-06 10:00:00.000 | item_a_1 | <NULL> | | -D | 1 | 2025-03-06 10:00:00.000 | item_a_1 | <NULL> | | +I | 1 | 2025-03-06 10:00:00.000 | item_a_1 | item_b_1 | | +I | 2 | 2025-03-06 10:01:00.000 | item_a_2 | <NULL> | | +I | 2 | 2025-03-06 12:01:30.000 | <NULL> | item_b_2 | +----+-------------+-------------------------+-----------+-----------+ Received a total of 5 rows (0.24 seconds)
Here we see the initial item_a_1 row unmatched (a NULL under b), and then that retracted (-D) and replaced (+I) with the successful match. id=2 remains unmatched, as before.
What about adding new data? Can we see it in action? 🔗
A detour into the Filesystem connector 🔗
By default the Filesystem connector is bounded—that is, Flink reads the contents of the file and then stops processing it. Let’s change that, by setting source.monitor-interval:
ALTER TABLE items_a SET ('source.monitor-interval'='1s');
ALTER TABLE items_b SET ('source.monitor-interval'='1s');Now look what happens when we query the table:
-- This was set above, but let's re-iterate it
-- here as it's core to the example
SET 'execution.runtime-mode' = 'streaming';
Flink SQL> select * from default_catalog.default_database.items_a ;
+----+-------------+-------------------------+----------+
| op | id | ts | a |
+----+-------------+-------------------------+----------+
| +I | 1 | 2025-03-06 10:00:00.000 | item_a_1 |
| +I | 2 | 2025-03-06 10:01:00.000 | item_a_2 |See how there’s no `"Received a total of 2 rows"` message? Instead in your SQL Client you’ll see just a cursor flashing, indicating that the query is still running.
Let’s add a row to the file:
cat << EOF >> data/items_a.csv
3,2025-03-06 10:02:00.000,item_a_3
EOFBUT…still nothing in the Flink query results, which stay exactly as they were—unless I cancel and re-run it (which is hardly a streaming query)
Flink SQL> select * from default_catalog.default_database.items_a ;
+----+-------------+-------------------------+-----------+
| op | id | ts | a |
+----+-------------+-------------------------+-----------+
| +I | 1 | 2025-03-06 10:00:00.000 | item_a_1 |
| +I | 2 | 2025-03-06 10:01:00.000 | item_a_2 |
^CQuery terminated, received a total of 2 rows (1.84 seconds)
Flink SQL> SELECT * FROM default_catalog.default_database.items_a ;
+----+-------------+-------------------------+-----------+
| op | id | ts | a |
+----+-------------+-------------------------+-----------+
| +I | 1 | 2025-03-06 10:00:00.000 | item_a_1 |
| +I | 2 | 2025-03-06 10:01:00.000 | item_a_2 |
| +I | 3 | 2025-03-06 10:02:00.000 | item_a_3 |The reason for this is in the docs for Filesystem connector:
Directory watching
[…]
Each file is uniquely identified by its path, and will be processed once […]
Emphasis is mine. The table above points to a single file, and the connector will only read a single file once, regardless of source.monitor-interval.
So, let’s create a folder for a data and b data.
❯ mkdir data/a data/b
❯ mv data/items_a.csv data/a/file1.csv
❯ mv data/items_b.csv data/b/file1.csv
❯ tree data
data
├── a
│ └── file1.csv
└── b
└── file1.csvBoth tables will need updating for the change in path:
ALTER TABLE items_a SET ('path' = '/data/a');
ALTER TABLE items_b SET ('path' = '/data/b');Let’s check items_a to make sure it still works:
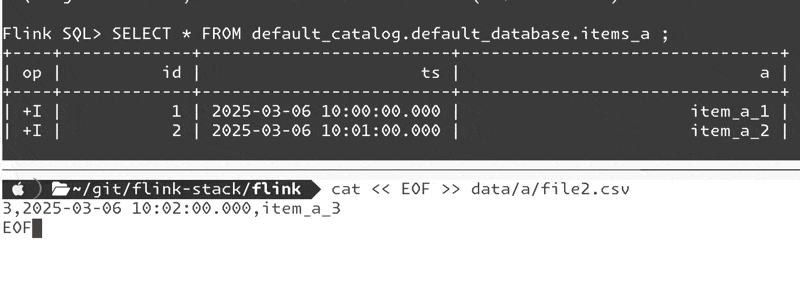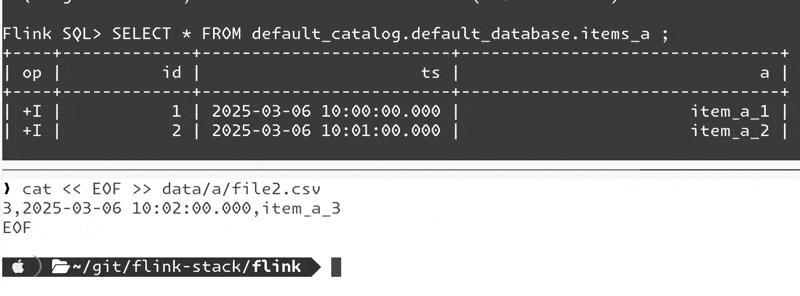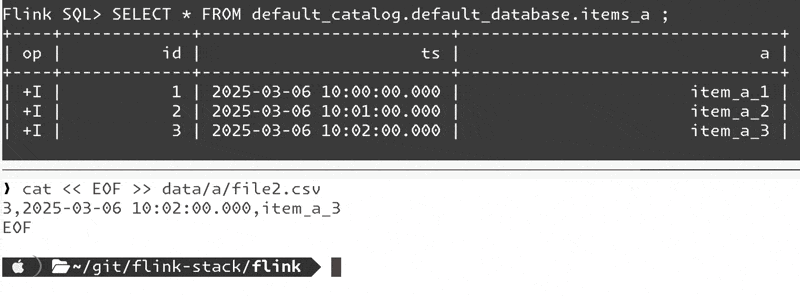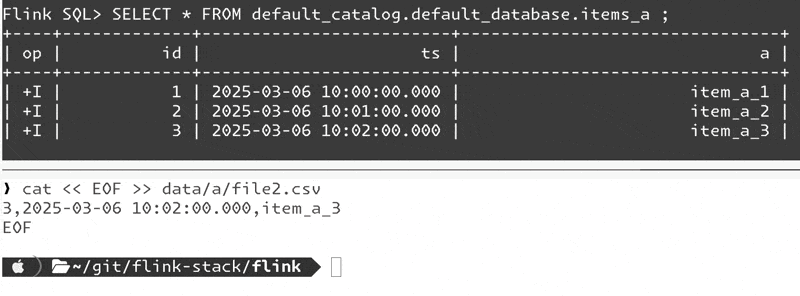
Flink SQL> SELECT * FROM default_catalog.default_database.items_a ;
+----+-------------+-------------------------+-----------+
| op | id | ts | a |
+----+-------------+-------------------------+-----------+
| +I | 1 | 2025-03-06 10:00:00.000 | item_a_1 |
| +I | 2 | 2025-03-06 10:01:00.000 | item_a_2 |and now add a new file to the source directory:
cat << EOF >> data/a/file2.csv
3,2025-03-06 10:02:00.000,item_a_3
EOFIt works!
Streaming join in action 🔗
With both tables now set up as unbounded, we can see how our join behaves in both streaming and batch modes:
SET 'execution.runtime-mode' = 'streaming';
SELECT COALESCE(a.id,b.id) AS id,
COALESCE(a.ts,b.ts) AS ts,
a.a AS a,
b.b AS b
FROM items_a a
FULL OUTER JOIN
items_b b
ON a.id=b.id
AND a.ts=b.ts;+----+-------------+-------------------------+-----------+----------+ | op | id | ts | a | b | +----+-------------+-------------------------+-----------+----------+ | +I | 1 | 2025-03-06 10:00:00.000 | item_a_1 | <NULL> | | -D | 1 | 2025-03-06 10:00:00.000 | item_a_1 | <NULL> | | +I | 1 | 2025-03-06 10:00:00.000 | item_a_1 | item_b_1 | | +I | 2 | 2025-03-06 10:01:00.000 | item_a_2 | <NULL> | | +I | 2 | 2025-03-06 12:01:30.000 | <NULL> | item_b_2 | | +I | 3 | 2025-03-06 10:02:00.000 | item_a_3 | <NULL> |
This is what it should be; id=2 is unmatched because of the different ts values (we could remove that from the ON join condition if we didn’t care about that), and id=3 is unmatched because there’s no corresponding value for item_b.
Let’s add an entry to item_b for id=3:
cat << EOF >> data/b/file2.csv
3,2025-03-06 10:02:00.000,item_b_3
EOFNow our results (which were still running from the query above) have these two rows added:
| -D | 3 | 2025-03-06 10:02:00.000 | item_a_3 | <NULL> | | +I | 3 | 2025-03-06 10:02:00.000 | item_a_3 | item_b_3 |
A -D to remove the unmatched row, and an +I to add in the now-matched row with the data from item_b.
What happens if we re-run this query as a batch? We should see just the final result of the joins, with the insert/delete steps omitted. Under the covers this is how any regular RDBMS operates—it’s just that in the batch world you never see it :)
SET 'execution.runtime-mode' = 'batch';
SELECT COALESCE(a.id,b.id) AS id,
COALESCE(a.ts,b.ts) AS ts,
a.a AS a,
b.b AS b
FROM items_a a
FULL OUTER JOIN
items_b b
ON a.id=b.id
AND a.ts=b.ts;[ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.ValidationException: Querying an unbounded table 'default_catalog.default_database.items_a' in batch mode is not allowed. The table source is unbounded.
Oh, I didn’t expect that! The error is pretty descriptive though. We changed the table from being bounded —which is the Filesystem connector default— to unbounded by setting source.monitor-interval.
What we need to do is change how the SQL Client interacts with the results. Instead of displaying them in tableau mode (as has been shown above), we use table mode, which is an interactive one:
SET 'execution.runtime-mode' = 'streaming';
SET 'sql-client.execution.result-mode' = 'table';SQL Query Result (Table)
Refresh: 1 s Page: Last of 1 Updated: 12:50:42.756
id ts a b
1 2025-03-06 10:00:00.000 item_a_1 item_b_1
2 2025-03-06 12:01:30.000 <NULL> item_b_2
2 2025-03-06 10:01:00.000 item_a_2 <NULL>
3 2025-03-06 10:02:00.000 item_a_3 item_b_3
This query continues to run, but shows us the current state of the query output, rather than the changelog mode (which can’t be displayed in tableau mode).
“Join using the latest record by timestamp” 🔗
This bit of the OP’s question isn’t addressed by the above solution. In fact, it conveniently steers completely around it ;) Let’s now look at how we’d implement it.
Before we dig into it, knowing which file the data is coming from will be useful, so let’s add that metadata to each table, just for debug purposes:
ALTER TABLE items_a ADD `file.path` STRING NOT NULL METADATA;
ALTER TABLE items_b ADD `file.path` STRING NOT NULL METADATA;The new column shows up like this:
Flink SQL> SELECT * FROM items_a;
+----+-------------+-------------------------+-----------+--------------------+
| op | id | ts | a | file.path |
+----+-------------+-------------------------+-----------+--------------------+
| +I | 1 | 2025-03-06 10:00:00.000 | item_a_1 | /data/a/file1.csv |
| +I | 2 | 2025-03-06 10:01:00.000 | item_a_2 | /data/a/file1.csv |
| +I | 3 | 2025-03-06 10:02:00.000 | item_a_3 | /data/a/file2.csv |Find the record for the latest timestamp 🔗
We’ll start simple with this new requirement, and consider just the table items_a. To start with we need some SQL that gives us for each id the value of a for the latest ts.
SELECT id, a, ts, `file.path`
FROM items_a items_a_outer
WHERE ts=(SELECT MAX(ts)
FROM items_a items_a_inner WHERE items_a_inner.id = items_a_outer.id);To begin with, we get this:
+----+-------------+----------+-------------------------+-------------------+ | op | id | a | ts | file.path | +----+-------------+----------+-------------------------+-------------------+ | +I | 1 | item_a_1 | 2025-03-06 10:00:00.000 | /data/a/file1.csv | | +I | 2 | item_a_2 | 2025-03-06 10:01:00.000 | /data/a/file1.csv | | +I | 3 | item_a_3 | 2025-03-06 10:02:00.000 | /data/a/file2.csv |
Now let’s add a file with the same key (id=3) but an older timestamp. We’ll hopefully not see the table update (because the WHERE ts=(SELECT MAX(ts) […] predicate isn’t matched)
cat << EOF >> data/a/file3.csv
3,2025-03-06 09:00:00.000,item_a_3_ts_is_older
EOFNothing changes on the table output. We can verify the row is there by looking at the table itself without predicates:
Flink SQL> SELECT * FROM items_a;
+----+-------------+-------------------------+----------------------+-------------------+
| op | id | ts | a | file.path |
+----+-------------+-------------------------+----------------------+-------------------+
| +I | 3 | 2025-03-06 10:02:00.000 | item_a_3 | /data/a/file2.csv |
| +I | 3 | 2025-03-06 09:00:00.000 | item_a_3_ts_is_older | /data/a/file3.csv |
| +I | 1 | 2025-03-06 10:00:00.000 | item_a_1 | /data/a/file1.csv |
| +I | 2 | 2025-03-06 10:01:00.000 | item_a_2 | /data/a/file1.csv |What if we add another file, with a newer timestamp this time?
Before we do that, we need to re-run our new query. When we do that, there’s something interesting already in the output:
Flink SQL> SELECT id, a, ts, `file.path`
FROM items_a items_a_outer
WHERE ts=(SELECT MAX(ts)
FROM items_a items_a_inner WHERE items_a_inner.id = items_a_outer.id);
+----+----+----------------------+-------------------------+-------------------+
| op | id | a | ts | file.path |
+----+----+----------------------+-------------------------+-------------------+
| +I | 1 | item_a_1 | 2025-03-06 10:00:00.000 | /data/a/file1.csv |
| +I | 2 | item_a_2 | 2025-03-06 10:01:00.000 | /data/a/file1.csv |
| +I | 3 | item_a_3_ts_is_older | 2025-03-06 09:00:00.000 | /data/a/file3.csv |
| -U | 3 | item_a_3_ts_is_older | 2025-03-06 09:00:00.000 | /data/a/file3.csv |
| +U | 3 | item_a_3 | 2025-03-06 10:02:00.000 | /data/a/file2.csv |Because /data/a/file3.csv looks like it gets read first, to start with item_a_3_ts_is_older value is the most recent timestamp. Then /data/a/file2.csv gets read, and the latest value for the key id=3 gets restated (-U followed by +U) to item_a_3.
If you’re particularly eagle-eyed, you might have noticed the operation in the changelog is -U /+U when an aggregate gets reissued, and a -D/+I when a join output changes. To learn more about changelog types, check out this useful doc.
|
Let’s now add a newer-still timestamp:
cat << EOF >> data/a/file4.csv
3,2025-03-06 11:00:00.000,item_a_3_ts_is_NEWER!
EOFJust as we saw above, now the value gets restated again:
| -U | 3 | item_a_3 | 2025-03-06 10:02:00.000 | /data/a/file2.csv | | +U | 3 | item_a_3_ts_is_NEWER! | 2025-03-06 11:00:00.000 | /data/a/file4.csv |
and to prove it’s not a fluke, another older timestamp:
cat << EOF >> data/a/file5.csv
3,2024-01-01 11:00:00.000,item_a_3_ts_is_old_old
EOFThe query output remains unchanged.
Joining latest records 🔗
Let’s finish by building the actual query the OP was looking for.
WITH item_a_newest AS (SELECT id, a, ts, `file.path`
FROM items_a items_a_outer
WHERE ts=(SELECT MAX(ts)
FROM items_a items_a_inner WHERE items_a_inner.id = items_a_outer.id)),
item_b_newest AS (SELECT id, b, ts, `file.path`
FROM items_b items_b_outer
WHERE ts=(SELECT MAX(ts)
FROM items_b items_b_inner WHERE items_b_inner.id = items_b_outer.id))
SELECT COALESCE(a.id,b.id) AS id,
a.ts AS a_ts,
b.ts AS b_ts,
a.a AS a,
b.b AS b,
a.`file.path` AS a_filepath,
b.`file.path` AS b_filepath
FROM item_a_newest a
FULL OUTER JOIN
item_b_newest b
ON a.id=b.id;Here’s the query output as a table (SET 'sql-client.execution.result-mode' = 'table';):
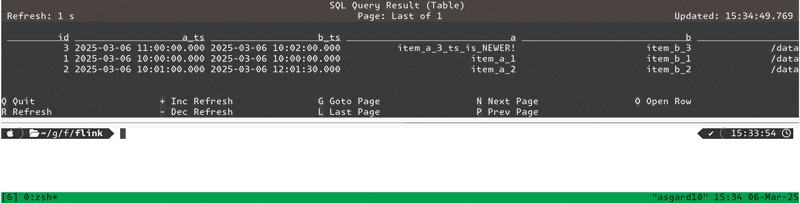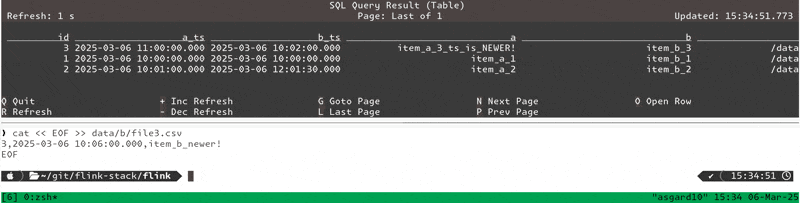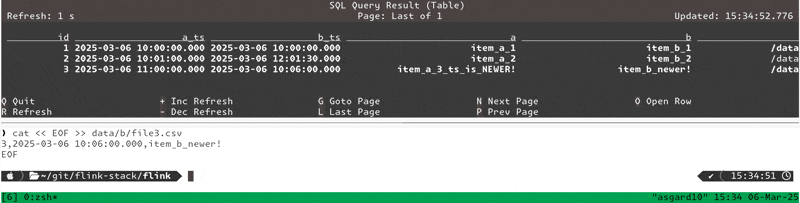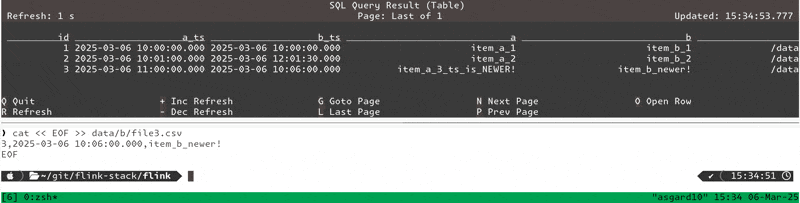
id a_ts b_ts a b a_filepath b_filepath 3 2025-03-06 11:00:00.000 2025-03-06 10:02:00.000 item_a_3_ts_is_NEWER! item_b_3 /data/a/file4.csv /data/b/file2.csv 1 2025-03-06 10:00:00.000 2025-03-06 10:00:00.000 item_a_1 item_b_1 /data/a/file1.csv /data/b/file1.csv 2 2025-03-06 10:01:00.000 2025-03-06 12:01:30.000 item_a_2 item_b_2 /data/a/file1.csv /data/b/file1.csv
This matches what we’d expect to see based on the data above. Let’s take a look at the changelog now (SET 'sql-client.execution.result-mode' = 'tableau';):
+----+----+-------------------------+-------------------------+-----------------------+----------+-------------------+-------------------+ | op | id | a_ts | b_ts | a | b | a_filepath | b_filepath | +----+----+-------------------------+-------------------------+-----------------------+----------+-------------------+-------------------+ | +I | 1 | 2025-03-06 10:00:00.000 | <NULL> | item_a_1 | <NULL> | /data/a/file1.csv | <NULL> | | +I | 2 | 2025-03-06 10:01:00.000 | <NULL> | item_a_2 | <NULL> | /data/a/file1.csv | <NULL> | | +I | 3 | 2025-03-06 09:00:00.000 | <NULL> | item_a_3_ts_is_older | <NULL> | /data/a/file3.csv | <NULL> | | -D | 3 | 2025-03-06 09:00:00.000 | <NULL> | item_a_3_ts_is_older | <NULL> | /data/a/file3.csv | <NULL> | | +I | 3 | 2025-03-06 10:02:00.000 | <NULL> | item_a_3 | <NULL> | /data/a/file2.csv | <NULL> | | -D | 3 | 2025-03-06 10:02:00.000 | <NULL> | item_a_3 | <NULL> | /data/a/file2.csv | <NULL> | | +I | 3 | 2025-03-06 11:00:00.000 | <NULL> | item_a_3_ts_is_NEWER! | <NULL> | /data/a/file4.csv | <NULL> | | -D | 3 | 2025-03-06 11:00:00.000 | <NULL> | item_a_3_ts_is_NEWER! | <NULL> | /data/a/file4.csv | <NULL> | | +I | 3 | 2025-03-06 11:00:00.000 | 2025-03-06 10:02:00.000 | item_a_3_ts_is_NEWER! | item_b_3 | /data/a/file4.csv | /data/b/file2.csv | | -D | 1 | 2025-03-06 10:00:00.000 | <NULL> | item_a_1 | <NULL> | /data/a/file1.csv | <NULL> | | +I | 1 | 2025-03-06 10:00:00.000 | 2025-03-06 10:00:00.000 | item_a_1 | item_b_1 | /data/a/file1.csv | /data/b/file1.csv | | -D | 2 | 2025-03-06 10:01:00.000 | <NULL> | item_a_2 | <NULL> | /data/a/file1.csv | <NULL> | | +I | 2 | 2025-03-06 10:01:00.000 | 2025-03-06 12:01:30.000 | item_a_2 | item_b_2 | /data/a/file1.csv | /data/b/file1.csv |
Insert a newer-timestamped row for an existing item_b key:
cat << EOF >> data/b/file3.csv
3,2025-03-06 10:06:00.000,item_b_newer!
EOFShows up in the table:
+----+----+-------------------------+-------------------------+-----------------------+----------------+-------------------+-------------------+ | op | id | a_ts | b_ts | a | b | a_filepath | b_filepath | +----+----+-------------------------+-------------------------+-----------------------+----------------+-------------------+-------------------+ | -D | 3 | 2025-03-06 11:00:00.000 | 2025-03-06 10:02:00.000 | item_a_3_ts_is_NEWER! | item_b_3 | /data/a/file4.csv | /data/b/file2.csv | | +I | 3 | 2025-03-06 11:00:00.000 | <NULL> | item_a_3_ts_is_NEWER! | <NULL> | /data/a/file4.csv | <NULL> | | -D | 3 | 2025-03-06 11:00:00.000 | <NULL> | item_a_3_ts_is_NEWER! | <NULL> | /data/a/file4.csv | <NULL> | | +I | 3 | 2025-03-06 11:00:00.000 | 2025-03-06 10:06:00.000 | item_a_3_ts_is_NEWER! | item_b_newer! | /data/a/file4.csv | /data/b/file3.csv |
To write this as a table, wrap the query in the CREATE TABLE … AS SELECT syntax.
CREATE TABLE `out` WITH (
'connector' = 'print'
) AS
WITH item_a_newest AS (SELECT id, a, ts
FROM items_a items_a_outer
WHERE ts=(SELECT MAX(ts)
FROM items_a items_a_inner WHERE items_a_inner.id = items_a_outer.id)),
item_b_newest AS (SELECT id, b, ts
FROM items_b items_b_outer
WHERE ts=(SELECT MAX(ts)
FROM items_b items_b_inner WHERE items_b_inner.id = items_b_outer.id))
SELECT COALESCE(a.id,b.id) AS id,
a.ts AS a_ts,
b.ts AS b_ts,
a.a AS a,
b.b AS b
FROM item_a_newest a
FULL OUTER JOIN
item_b_newest b
ON a.id=b.id;If you try and use the Filesystem connector you’ll get the error:
Table sink 'default_catalog.default_database.out' doesn't support consuming update and delete changes which is produced by node Join(joinType=[FullOuterJoin], where=[(id = id0)], select=[id, a, ts, id0, b, ts0],
leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey])Therefore I’m using the print connector since I don’t have anything installed that will act as an updatable sink. You can look at the Flink logs to see what gets written:
❯ docker compose logs taskmanager |grep -E '[\\+\\-][DUI]\['
taskmanager-1 | +I[1, null, 2025-03-06T10:00, null, item_b_1]
taskmanager-1 | +I[2, null, 2025-03-06T12:01:30, null, item_b_2]
taskmanager-1 | +I[3, null, 2025-03-06T10:06, null, item_b_newer!]
taskmanager-1 | -D[3, null, 2025-03-06T10:06, null, item_b_newer!]
taskmanager-1 | +I[3, 2025-03-06T09:00, 2025-03-06T10:06, item_a_3_ts_is_older, item_b_newer!]
taskmanager-1 | -D[3, 2025-03-06T09:00, 2025-03-06T10:06, item_a_3_ts_is_older, item_b_newer!]
taskmanager-1 | +I[3, null, 2025-03-06T10:06, null, item_b_newer!]
taskmanager-1 | -D[3, null, 2025-03-06T10:06, null, item_b_newer!]
taskmanager-1 | +I[3, 2025-03-06T11:00, 2025-03-06T10:06, item_a_3_ts_is_NEWER!, item_b_newer!]
taskmanager-1 | -D[1, null, 2025-03-06T10:00, null, item_b_1]
taskmanager-1 | +I[1, 2025-03-06T10:00, 2025-03-06T10:00, item_a_1, item_b_1]
taskmanager-1 | -D[2, null, 2025-03-06T12:01:30, null, item_b_2]
taskmanager-1 | +I[2, 2025-03-06T10:01, 2025-03-06T12:01:30, item_a_2, item_b_2]