So far I’ve plotted out a bit of a map for my exploration of Apache Flink, looked at what Flink is, and run my first Flink application. Being an absolutely abysmal coder—but knowing a thing or two about SQL—I figure that Flink SQL is where my focus is going to lie (I’m also intrigued by PyFlink, but that’s for another day…).
So let’s start exploring Flink SQL! I’ll use the same local cluster that I started last time, against which I’m going to run the SQL Client:
./bin/sql-client.sh
🐿️ From here we get the most wonderful ASCII art squirrel, which put a smile on my face.
▒▓██▓██▒
▓████▒▒█▓▒▓███▓▒
▓███▓░░ ▒▒▒▓██▒ ▒
░██▒ ▒▒▓▓█▓▓▒░ ▒████
██▒ ░▒▓███▒ ▒█▒█▒
░▓█ ███ ▓░▒██
▓█ ▒▒▒▒▒▓██▓░▒░▓▓█
█░ █ ▒▒░ ███▓▓█ ▒█▒▒▒
████░ ▒▓█▓ ██▒▒▒ ▓███▒
░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░
▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒
███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒
░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒
███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░
██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓
▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒
▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒
▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█
██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █
▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓
█▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓
██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓
▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒
██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒
▓█ ▒█▓ ░ █░ ▒█ █▓
█▓ ██ █░ ▓▓ ▒█▓▓▓▒█░
█▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█
██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓
▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██
░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓
░▓██▒ ▓░ ▒█▓█ ░░▒▒▒
▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░
______ _ _ _ _____ ____ _ _____ _ _ _ BETA
| ____| (_) | | / ____|/ __ \| | / ____| (_) | |
| |__ | |_ _ __ | | __ | (___ | | | | | | | | |_ ___ _ __ | |_
| __| | | | '_ \| |/ / \___ \| | | | | | | | | |/ _ \ '_ \| __|
| | | | | | | | < ____) | |__| | |____ | |____| | | __/ | | | |_
|_| |_|_|_| |_|_|\_\ |_____/ \___\_\______| \_____|_|_|\___|_| |_|\__|
Orientating myself in the CLI environment - result and runtime modes #
When you first launch the Flink SQL Client and run a query (I used the one from the SQL Client guide):
SELECT
name,
COUNT(*) AS cnt
FROM
(VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name)
GROUP BY name;
it defaults to an interactive table view (result-mode=table)
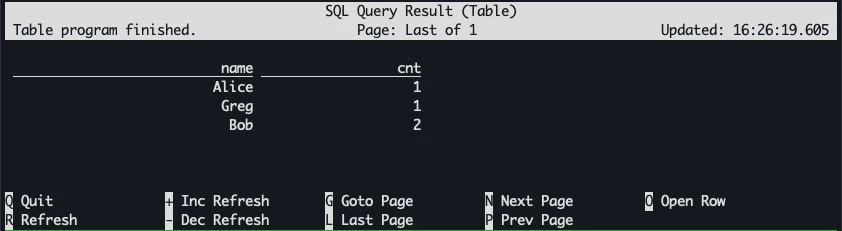
This is probably useful for streaming, but perhaps less so for a one-off static query?
The next result-mode is similar but shows the table as a change log (a concept very familiar to me from the stream-table duality). The results are still shown on an updating and interactive screen.
SET 'sql-client.execution.result-mode' = 'changelog';
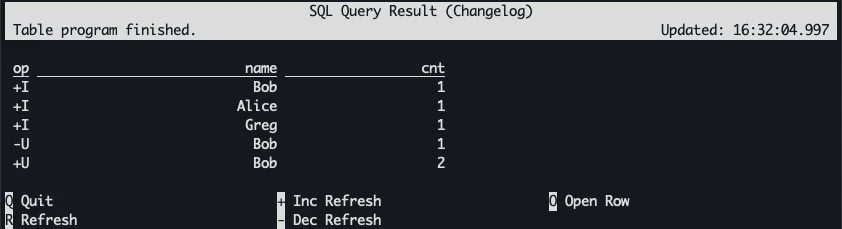
(If you are wondering how there is an UPDATE operation in a simple SELECT then take a close look at the FROM clause of the SQL being run. The name value Bob appears twice, and so the aggregate state change from a COUNT of 1 to 2)
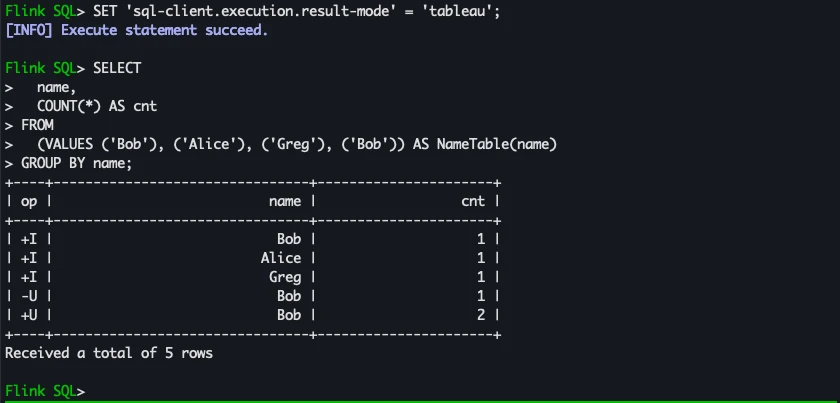
A more conventional way to display the results just as SQL*Plus in Oracle would, psql in PostgreSQL etc, is tableau. Note that you get the changelog operations shown just as when you explicitly set it in the previous option.
SET 'sql-client.execution.result-mode' = 'tableau';
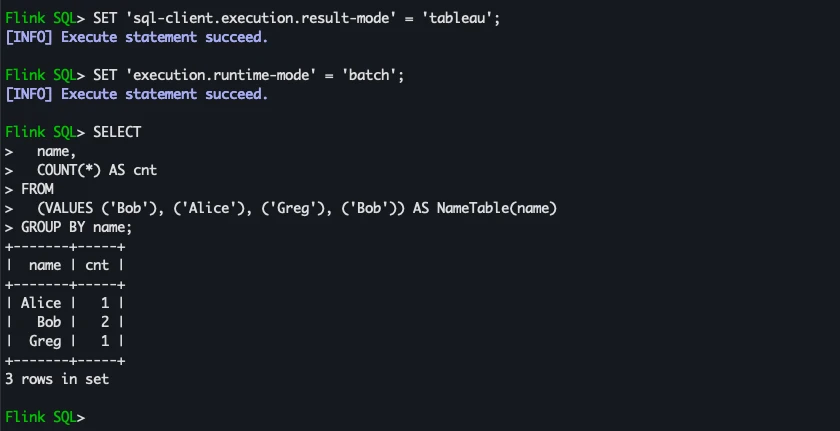
For a “normal” result display (in a tabular view, no change log, just the final state) we set another parameter, runtime-mode:
SET 'execution.runtime-mode' = 'batch';
A Stream is a Table is a Stream #

I want to start digging into how Flink’s view of everything being a stream—just bounded or unbounded—works alongside the SQL semantics of a TABLE.
In the SQL Client doc I noticed the syntax for CREATE TABLE included the option to read from a local CSV file. I’m hoping that I can define a table on the file to read it, and then start adding rows to the CSV and use this as a crude simulation of a stream a.k.a. unbounded data to see how it works in Flink.
I’ve not dug into Flink’s connector capabilities yet so am navigating this one completely in the dark to start with. Looking through the docs I found Connectors on the sidebar nav, of which there are three types listed
- DataSet Connectors
- DataStream Connectors
- Table API
One of the areas that I identified previously to look at was an understanding of Flink’s architecture and concepts—which I still need to do. For now, I’m going on the basis that I’ve seen “Table API” and “SQL” alongside each other before, so take a punt on the Table API menu section, which yielded the FileSystem SQL Connector. It looks like it supports a variety of formats, although not the option to derive columns and names from headers which is a shame.
NOTE: there is also a DataGen connector, but the File System one at this stage looked simpler for working with just a handful of rows to understand what was going on.
Using one of my favourite tools, Mockaroo, I generate some CSV data
timestamp,source_ip,dest_ip,source_prt,dest_prt
2018-05-11 00:19:34,151.35.34.162,125.26.20.222,2014,68
2018-05-11 22:20:43,114.24.126.190,21.68.21.69,379,1619
and write this to /tmp/firewall.csv.
Let’s create a table on it, using some fairly straightforward syntax lifted from the docs.
CREATE TABLE firewall (
event_time STRING,
source_ip STRING,
dest_ip STRING,
source_prt INT,
dest_prt INT
) WITH (
'connector' = 'filesystem',
'path' = 'file:///tmp/firewall.csv',
'format' = 'csv'
);
It worked first time…which always makes me suspicious… 🤔
[INFO] Execute statement succeed.
Let’s try querying it.
Flink SQL> SELECT * FROM firewall;
[ERROR] Could not execute SQL statement. Reason:
java.lang.NumberFormatException: For input string: "source_prt"
I knew it was too good to be true 😅 My guess was that perhaps the header was tripping things up (trying to store the source_prt as the defined INT). The first hit on Stack Overflow was pretty useful and pointed to a few options if I needed to keep the header. For the sake of expediency, I just removed it and tried the SELECT again:
Flink SQL> SET 'sql-client.execution.result-mode' = 'tableau';
[INFO] Execute statement succeed.
Flink SQL> SELECT * FROM firewall;
+----+--------------------------------+--------------------------------+--------------------------------+-------------+-------------+
| op | event_time | source_ip | dest_ip | source_prt | dest_prt |
+----+--------------------------------+--------------------------------+--------------------------------+-------------+-------------+
| +I | 2018-05-11 05:02:09 | 73.98.97.177 | 41.52.138.199 | 1478 | 1181 |
| +I | 2018-05-11 07:59:48 | 21.171.129.233 | 26.203.158.152 | 1538 | 1680 |
+----+--------------------------------+--------------------------------+--------------------------------+-------------+-------------+
Received a total of 2 rows
Nice! We’ve read from a flat file using Flink. At the moment it’s bounded data; there are two rows of data in the file, and we have read them. The boundary is the end of the file. What about if we cheat a little bit and move that boundary on and start adding some rows, making it kinda unbounded? Looking at how the query above ran and completed, we’re going to need to change something in how we run the query to tell Flink that there will be more data.
Reading a CSV file as a stream #

Let’s take a guess and change the runtime-mode:
SET 'sql-client.execution.result-mode' = 'changelog';
and query the table again:
SELECT * FROM firewall;
I got the interactive-looking screen:
SQL Query Result (Changelog)
Table program finished. Updated: 10:45:17.909
op event_time source_ip dest_ip source_prt dest_prt
+I 2018-05-11 05:02:09 73.98.97.177 41.52.138.199 1478 1181
+I 2018-05-11 07:59:48 21.171.129.233 26.203.158.152 1538 1680
But note the Table program finished in the top left—and when I added a row to the CSV file nothing changed in the results.
This is where the documentation comes in handy ;-) Above, I set the runtime-mode to batch - so is there a streaming counterpart? I struggled to find a clear documentation of this via the search, but under DataStream API I found an explanation of it. At this stage, I’m still randomly-jiggling things but I do need to go back and understand the relationship between the APIs properly. Anyway, let’s try changing it:
SET 'execution.runtime-mode' = 'STREAMING';
I got the same behaviour as before - no changes picked up by the query. What about the connector itself? It turns out that it isn’t doing the streaming:
By default, the file system connector is bounded
However, it does have an option for streaming, whereby it monitors a folder for new files. Since we’ve started down this path, let’s keep going. I’ll create a dedicated folder locally for my CSV files, and recreate the table:
DROP TABLE firewall;
CREATE TABLE firewall (
event_time STRING,
source_ip STRING,
dest_ip STRING,
source_prt INT,
dest_prt INT,
`file.path` STRING NOT NULL METADATA
) WITH (
'connector' = 'filesystem',
'path' = 'file:///tmp/firewall/',
'format' = 'csv',
'source.monitor-interval' = '1' -- unclear from the docs what the unit is here
);
(I’ve added another column that I found in the docs, showing metadata for the file that was read).
On disk I’ve got:
$ ls -l /tmp/firewall
total 8
-rw-r--r--@ 1 rmoff wheel 117 10 Oct 10:58 1.csv
-rw-r--r--@ 1 rmoff wheel 251 10 Oct 12:14 2.csv
Now let’s query it, and re-issue the runtime-mode and results-mode settings just to keep things in one place and clear (note that you have to run the statements in the CLI one by one):
SET 'sql-client.execution.result-mode' = 'changelog';
SET 'execution.runtime-mode' = 'STREAMING';
SELECT * FROM firewall;
NOW we are getting somewhere! 🥳 Note how the Updated field is advancing and the top left says Refresh: Fastest (rather than the previous message about a table program finishing):

Now that the query is running continuously, let’s add some more data. Mockaroo supports a REST API which I’ll pull straight into the new file:
curl "https://api.mockaroo.com/api/f6255400?count=4&key=" > /tmp/firewall/2.csv
Unfortunately, Flink doesn’t seem to like this, and the executing query aborts as soon as I run the curl command:
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalArgumentException
It was all going so well 😅… #

In the root of the Flink directory (from which I launched the cluster and the SQL Client) is a folder called log. In there I looked at the recently changed files and searched for IllegalArgumentException which yielded the following in flink-rmoff-standalonesession-0-asgard08.log:
2023-10-10 13:45:20,609 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Source: firewall[3] -> Sink: Collect table sink (1/1) (b75ce256ec609708e0d19f8a57a84e48_cbc357ccb763df2852fee8c4fc7d55f2_0_0) switched from RUNNING to FAILED on localhost:52591-4b9201 @ localhost (dataPort=52593).
java.lang.RuntimeException: One or more fetchers have encountered exception
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:261) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:169) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:131) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:417) ~[flink-dist-1.17.1.jar:1.17.1]
at org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68) ~[flink-dist-1.17.1.jar:1.17.1]
at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65) ~[flink-dist-1.17.1.jar:1.17.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:550) ~[flink-dist-1.17.1.jar:1.17.1]
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:231) ~[flink-dist-1.17.1.jar:1.17.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:839) ~[flink-dist-1.17.1.jar:1.17.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:788) ~[flink-dist-1.17.1.jar:1.17.1]
at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:952) ~[flink-dist-1.17.1.jar:1.17.1]
at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:931) ~[flink-dist-1.17.1.jar:1.17.1]
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:745) ~[flink-dist-1.17.1.jar:1.17.1]
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:562) ~[flink-dist-1.17.1.jar:1.17.1]
at java.lang.Thread.run(Thread.java:829) ~[?:?]
Caused by: java.lang.RuntimeException: SplitFetcher thread 1 received unexpected exception while polling the records
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:165) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:114) ~[flink-connector-files-1.17.1.jar:1.17.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515) ~[?:?]
at java.util.concurrent.FutureTask.run(FutureTask.java:264) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) ~[?:?]
... 1 more
Caused by: java.lang.IllegalArgumentException
and then in the flink-rmoff-taskexecutor-1-asgard08.log I saw:
2023-10-10 13:45:20,587 INFO org.apache.flink.connector.base.source.reader.SourceReaderBase [] - Adding split(s) to reader: [FileSourceSplit: file:/tmp/firewall/2.csv [0, 0) (no host info) ID=0000004128 position=null]
2023-10-10 13:45:20,587 INFO org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher [] - Starting split fetcher 1
2023-10-10 13:45:20,588 ERROR org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager [] - Received uncaught exception.
java.lang.RuntimeException: SplitFetcher thread 1 received unexpected exception while polling the records
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:165) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:114) [flink-connector-files-1.17.1.jar:1.17.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515) [?:?]
at java.util.concurrent.FutureTask.run(FutureTask.java:264) [?:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) [?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) [?:?]
at java.lang.Thread.run(Thread.java:829) [?:?]
Caused by: java.lang.IllegalArgumentException
at org.apache.flink.util.Preconditions.checkArgument(Preconditions.java:122) ~[flink-dist-1.17.1.jar:1.17.1]
at org.apache.flink.connector.file.src.impl.StreamFormatAdapter$TrackingFsDataInputStream.<init>(StreamFormatAdapter.java:264) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.file.src.impl.StreamFormatAdapter.lambda$openStream$3(StreamFormatAdapter.java:180) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.file.src.util.Utils.doWithCleanupOnException(Utils.java:45) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.file.src.impl.StreamFormatAdapter.openStream(StreamFormatAdapter.java:172) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.file.src.impl.StreamFormatAdapter.createReader(StreamFormatAdapter.java:70) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.file.src.impl.FileSourceSplitReader.checkSplitOrStartNext(FileSourceSplitReader.java:112) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.file.src.impl.FileSourceSplitReader.fetch(FileSourceSplitReader.java:65) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.base.source.reader.fetcher.FetchTask.run(FetchTask.java:58) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:162) ~[flink-connector-files-1.17.1.jar:1.17.1]
... 6 more
2023-10-10 13:45:20,593 INFO org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher [] - Split fetcher 1 exited.
The salient lines here seeming to be
Adding split(s) to reader: [FileSourceSplit: file:/tmp/firewall/2.csvSplitFetcher thread 1 received unexpected exception while polling the recordsCaused by: java.lang.IllegalArgumentExceptionat org.apache.flink.util.Preconditions.checkArgument(Preconditions.java:122) ~[flink-dist-1.17.1.jar:1.17.1]at org.apache.flink.connector.file.src.impl.StreamFormatAdapter$TrackingFsDataInputStream.<init>(StreamFormatAdapter.java:264) ~[flink-connector-files-1.17.1.jar:1.17.1]
Perhaps having curl stream the HTTP call output into the file is confusing things; it it better to buffer it and then give the connector a complete file to read?
By using && in bash I can write the output from curl to one file, and then once that completes, rename it into the /tmp/firewall folder:
curl "https://api.mockaroo.com/api/f6255400?count=4&key=ff7856d0" > /tmp/data.csv && \
mv /tmp/data.csv /tmp/firewall/3.csv
Look at that! A streaming query! 👀 😄
More errors 😑 #
Before my celebrations had quite died, down the query itself aborted:
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.shaded.netty4.io.netty.channel.ConnectTimeoutException: connection timed out: localhost/127.0.0.1:52596
This in fact happened whether I added to data or not; if I left the SELECT running for more than a few seconds I got this. Some kind of built-in timeout, perhaps?
Remembering the Flink Web UI that I saw last time I headed over to see what I could see there. A whole lotta CANCELED!
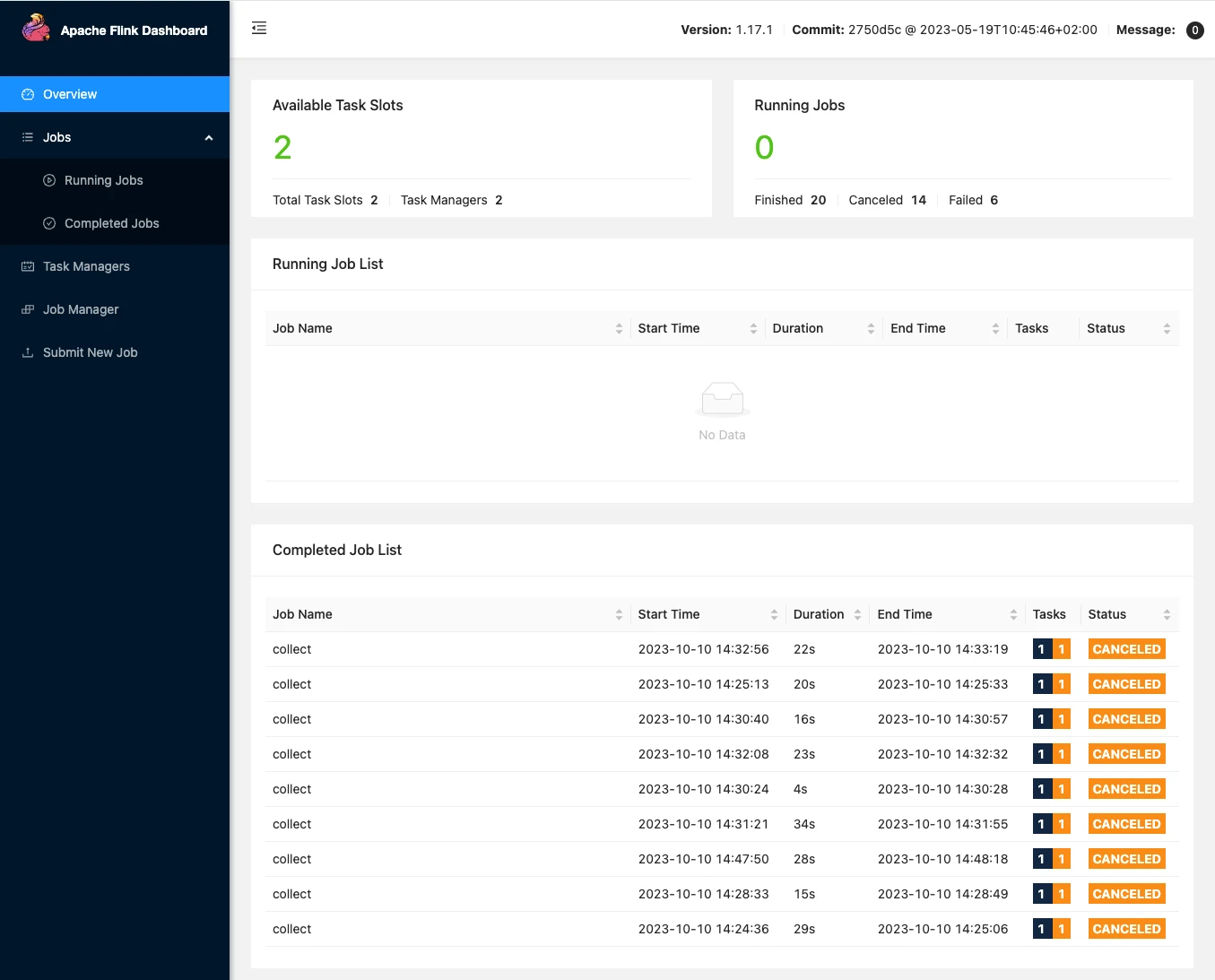
Via this you can get to the Job Manager and Task Manager logs (just as I did from the log folder, but this time through the Web UI). It also reminds me that I still need to figure out where these components come in the runtime architecture 😅
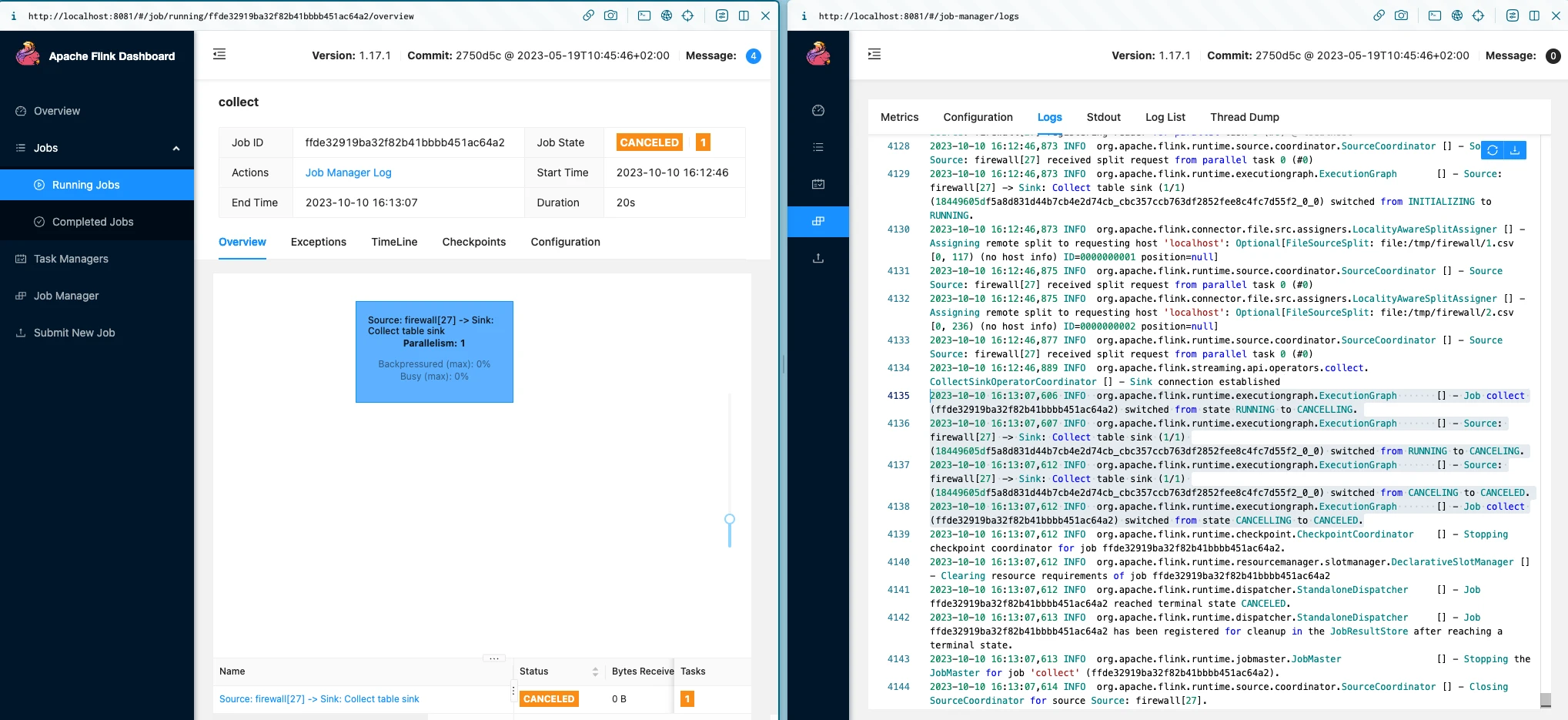
-
Job Manager
2023-10-10 16:13:07,606 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job collect (ffde32919ba32f82b41bbbb451ac64a2) switched from state RUNNING to CANCELLING. 2023-10-10 16:13:07,607 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Source: firewall[27] -> Sink: Collect table sink (1/1) (18449605df5a8d831d44b7cb4e2d74cb_cbc357ccb763df2852fee8c4fc7d55f2_0_0) switched from RUNNING to CANCELING. 2023-10-10 16:13:07,612 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Source: firewall[27] -> Sink: Collect table sink (1/1) (18449605df5a8d831d44b7cb4e2d74cb_cbc357ccb763df2852fee8c4fc7d55f2_0_0) switched from CANCELING to CANCELED. 2023-10-10 16:13:07,612 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job collect (ffde32919ba32f82b41bbbb451ac64a2) switched from state CANCELLING to CANCELED. -
Task Manager
2023-10-10 16:13:07,607 INFO org.apache.flink.runtime.taskmanager.Task [] - Attempting to cancel task Source: firewall[27] -> Sink: Collect table sink (1/1)#0 (18449605df5a8d831d44b7cb4e2d74cb_cbc357ccb763df2852fee8c4fc7d55f2_0_0). 2023-10-10 16:13:07,607 INFO org.apache.flink.runtime.taskmanager.Task [] - Source: firewall[27] -> Sink: Collect table sink (1/1)#0 (18449605df5a8d831d44b7cb4e2d74cb_cbc357ccb763df2852fee8c4fc7d55f2_0_0) switched from RUNNING to CANCELING. 2023-10-10 16:13:07,607 INFO org.apache.flink.runtime.taskmanager.Task [] - Triggering cancellation of task code Source: firewall[27] -> Sink: Collect table sink (1/1)#0 (18449605df5a8d831d44b7cb4e2d74cb_cbc357ccb763df2852fee8c4fc7d55f2_0_0). 2023-10-10 16:13:07,609 INFO org.apache.flink.connector.base.source.reader.SourceReaderBase [] - Closing Source Reader. 2023-10-10 16:13:07,610 INFO org.apache.flink.runtime.taskmanager.Task [] - Source: firewall[27] -> Sink: Collect table sink (1/1)#0 (18449605df5a8d831d44b7cb4e2d74cb_cbc357ccb763df2852fee8c4fc7d55f2_0_0) switched from CANCELING to CANCELED.
Time out #

At this point I’ve got the basics of a query running, I’ve learnt something about tables and connectors - and I’m stuck!
I’m going to step back, and learn more about the Flink architecture and components before digging myself a deeper hole on this particular issue 😁 Particular things I’ve come across during my reading that I want to find out more about include the SQL Gateway, Dynamic Tables, and the Flink Architecture docs.
Join me next time for more fun and stack traces…
